当前位置:网站首页>2021:Greedy Gradient Ensemble for Robust Visual Question Answering
2021:Greedy Gradient Ensemble for Robust Visual Question Answering
2022-06-27 03:05:00 【weixin_42653320】
摘要
语言偏见是视觉问答中的一个关键性问题,即经常利用数据集偏见而不是图像信息来做最后的决定,导致模型在域外分布数据的糟糕表现和不充分的视觉解释性。本文提出一种新的去偏框架--Greedy Gradient Ensemble(GGE),结合多个偏见模型以进行去偏见的模型学习。由于贪婪策略,GGE迫使有偏见的模型优先过度拟合有偏见的数据分布,使得基本模型关注于有偏见模型难以解决的例子。实验表明我们的方法更好的利用了视觉信息,并在未使用额外注释的数据集VQA-CP上实现了最先进的表现。
一、介绍
语言偏见,即模型经常利用问题和答案的表面相关性来训练模型,而不考虑视觉信息。这个问题流行的解决方法可以被分为:基于集成、基于接地、基于反事实。基于集成的方法与传统的长尾分类中的重新加权和重新采样类似,它通过只有问题的分支对样本重新加权;基于接地的模型根据人类注释的视觉解释强调对图像信息的更好利用;最新提出的基于反事实的方法进一步结合了这两种工作并实现了更好的表现。而且,现有的方法也并不能充分利用视觉和语言信息,如基于接地的方法精度的提高并不是来自适当的视觉基础,而是来自一些未知的正则化效应。
通过实验分析,语言偏见实际上为两种:a)训练和测试间的统计分布差距,b)特定QA对的语义相关性,如图1所示。

我们提出了Greedy Gradient Ensemble(GGE),一种模型不可知的去偏框架,继承了偏见模型和在函数空间的梯度下降的基本模型。我们方法的关键思想是利用深度学习中的过度拟合现象。数据的偏见部分被偏见的特征贪婪地过拟合,因此可以用更理想的数据分布学习期望的基本模型,并关注在偏见模型难以解决的例子上。
二、相关工作
三、VQA中的语言先验
从实验中可以得出以下结论:1)好的正确率并不能保证系统在答案分类器上很好的应用了视觉信息,接地监督或只有问题正则化可能鼓励模型利用相反的语言偏见,而不是根号的视觉信息。2)分布偏见和相关性偏见是VQA中语言偏见的互补方面,一个单一集成分支并不能建模这两种偏见。
四、方法
4.1 Greedy Gradient Ensemble
(X,Y)表示训练集,X表示观察空间,Y表示标签空间,根据之前的VQA方法,主要考虑二值交叉熵损失的分类问题:

基线模型直接最小化预测f(X;sita)和标签Y之间的损失:
![]()
导致模型很容易过拟合数据集的偏见,从而有不好的泛化能力。
假设B为一组可以基于先验知识提取的偏见特征,我们拟合偏见模型和基本模型到标签Y:

hi表示确定偏见特征的一个偏见模型。理想情况下,我们希望数据的偏见部分仅通过偏见模型过拟合,因此基本模型可以学习非偏见的数据分布,为实现此目标,我们提出GGE,偏见模型有很高的有限性拟合数据。
在函数空间中,假设有Hm,希望找到hm+1添加到Hm上使得损失下降。理论上,hm+1的期望方向是L在Hm处的负导数:
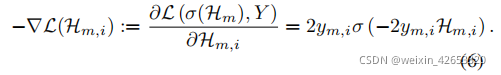
我们将负梯度作为分类的伪标签,并优化新模型hm+1的BCE损失:
![]()
整合所有偏见模型后,对期望的基本模型f进行优化:
![]()
在测试阶段只是用基本模型预测。
更直观地说,对于一个容易被偏置模型拟合的样本,其损失−∇L(HM)的负梯度(即基础模型的伪标签)将变得相对较小。f(X;θ)将更加关注以前的集成偏置分类器HM难以解决的样本
为使上述范式适应批随机梯度衰减(Batch SGD),我们实现两个优化调度GGE-迭代和GGE-together,对于GGE-iter,每个模型都在特定的数据批处理迭代中迭代更新。GGE-tog共同优化了偏执模型和基本模型:
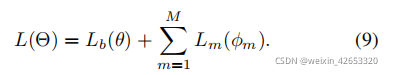
4.2 鲁棒VQA的GGE实现
我们定义两种偏见特征:分布偏见和shortcut偏见。
(1)分布偏见
我们将分布偏见定义为基于问题类型的训练集答案分布:
![]()
以问题类型为条件计算样本的原因是为了在减少分布偏见时保持类型信息。
(2)Shortcut 偏见
表示特定问答对的语义相关性,我们将问题shortcut偏见作为一个只有问题的分支:
![]()
为验证我们提出的分布偏见和shortcut偏见是互补的,我们设计三个版本的GGE来处理不同语言偏见的集合。

(1)GGE-D
只建模集成的模型分布偏见,如图2b,基本模型的损失是:
![]()
(2)GGE-Q
只使用一个基于问题的分支为shortcut偏见,如图2c,首先优化有标签的答案的只有问题分支:![]()
基本模型的损失为:![]()
(3)GGE-DQ
使用分布偏见和问题shortcut偏见,如图2d,Bq的损失为:
![]()
基本模型的损失为:![]()
4.3 连接到增强
增强是一种广泛应用的解决分类问题的集成策略,增强的主要思想是将多个高偏见、低方差的弱分类器相结合,成为一个低偏见、和低方差的强分类器。每个基本学习器都必须足够弱,否则,最初的几个分类器将很容易过拟合训练数据,然而,神经网络拟合能力太强,不能成为增强策略的高偏见和低方差,很难使用深度模型作为弱学习器。本文中,我们的方法利用这种过拟合现象,使偏见弱特征过拟合偏见分布。在测试阶段明知是用由偏见模型梯度训练的基本模型。
五、实验
5.1 评估指标
一个新的指标--正确预测但不合适的接地CPIG来评估视觉接地性,定义1-CPIG为CGR(为正确预测的正确接地):

为了定量评估模型是否使用视觉信息来回答决策,我们引入了CGW(正确的接地,但错误的预测):![]()
为了进行更清晰的比较,我们将CGR和CGW的差异表示为CGD(正确的接地性):
![]()
CGD只评估视觉信息是否在回答决策中获取,这与准确性平行。CGD的关键思想是一个模型确实使用视觉信息,并不仅仅基于正确视觉区域提供正确的预测,且由于不合适的视觉区域也会导致错误的答案。在表2中,UpDn,HINTinv和CSS-Vinv在正确率上实现可比较的表现,但在CGD上显著下降,正迎合了我们的分析:这些模型在做答案决策时并没有充分利用视觉信息。

5.2 与最新模型比较
将最好的模型GGE-DQ与最先进的偏见减少技术进行比较,包括基于视觉接地的方法HINT, SCR, 基于集成的方法AdvReg, RUBi, LMH, MFH, 基于问题编码的方法GVQE, DLP,基于反事实的方法CF-VQA, CSS和最近提出的正则化方法MFE。
在VQA-CP测试集中,GGE-DQ在没有额外注释时实现了最先进的表现,优于UpDn正确率17%,CGD13%,验证了GGE在答案分类和视觉接地能力的影响。在同一个基本模型UpDn之下,我们的方法实现了最好的表现,甚至与使用强壮的基本模型有竞争的性能。
对于问题类型的表现,合成GGE减少了偏见并提高了所有问题类型的表现,尤其时other类问题。CF-VQA在Y/N上表现最好,但是在所有其他指标上都比我们的方法更糟。LMH, LMH-MFE, 和LMH-CSS在Num上超过了其他方法,LMH-CSS在整体准确率上甚至轻微超过GGE-DQ,由于在Num上的高准确率。比较LM和LMH,在Num上明显增长,由于熵的正则化,然而,有熵正则化的方法在VQA v2上下降几乎10%,表明这些模型可能过度纠正偏见并大量使用“相反的语言偏见”。
5.3 消融实验

第一组消融是验证贪婪集成是否能保证用偏见模型学习偏见数据。我们比较其他两种集成策略,SUM-DQ直接总结偏见模型和基本模型的输出,LMH+RUBi结合LMH的分布偏见和RUBi的shortcut偏见。表5所示,SUM-DQ甚至比基线更糟,同时LMH+RUBi的正确率与LMH类似,大约比GGE-DQ糟6%,表示GGE可以真正迫使有偏见的数据被序列化的有偏见模型学习。基于分布或shortcut偏差容易预测的实例将被相应的偏见模型很好地拟合。因此,基础模型必须更加关注困难的例子,并考虑更多的视觉信息来进行最终决策。

第二组实验中,比较分布偏见和shortcut偏见,图3的实例分析表明GGE-D只统一预测,主要改善Y/N在表5中。Bq的工作原理像“硬例挖掘”,但也会引入一些噪音(例如本例中的“镜像”和“否”)由于反分布偏差。在第一阶段减少Bd可以进一步鼓励发现硬例,并迫使基础模型捕获视觉信息。在图3中,正确的答案有更高的置信度,并且最高的预测都是基于图像。如表5所示,GGE-DQ比单偏见版本高出10%。这很好地验证了我们的主张,即分布偏差和shortcut偏差是语言偏差的两个互补方面。
5.4 GGE的泛化
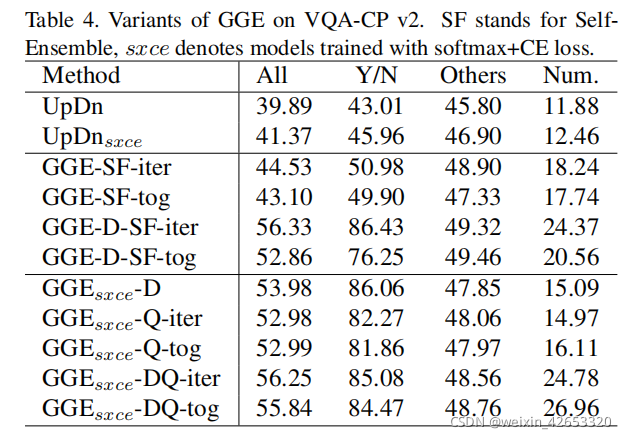
(1)自我集成
GGE的表现很大程度取决于预训练的偏见特征,此特征需要任务或数据集的先验知识。为进一步讨论GGE的泛化,我们测试一个更灵活的自我集成GGE-SF。GGE-SF将共同表示作为偏见特征,而不是预训练的只有问题分支,偏见预测为:
![]()
cs表示偏见模型的分类器,训练过程与GGE-Q一样。
如表4,即使没有预训练的偏见特征,GGE-SF仍然超过基线,意味着只要任务或数据集有足够的偏见,基本模型也可以被视为一个有偏模型。此外,如果我们首先在自我集成之前用GGE-D消除分布偏见,GGE-D-SF的性能也可以与现有的最先进方法相比。
(2)损失函数的泛化
为对之前工作进行公平比较,我们采用Sigmoid+BCE损失进行上述实验,实际上,GGE对分类损失是不可知的,在表4中提供关于Softmax+CE损失的额外实验。
(3)基本模型的泛化
GGE对基本模型的选择也是不可知的,提供BAN和S-MRL作为基本模型的额外实验。
5.5 定性评估

图4表示GGE-DQ如何利用视觉信息进行推理,我们提供了三种UpDn失败的例子,第一个关于shortcut偏见,UpDn的预测并没有基于正确的视觉接地;第二个例子关于分布偏见,UpDn正确的捕捉了视觉区域但仍然依据分布偏见回答问题;最后一个例子是除了y/n之外,减少语言先验的情况,UpDn只基于语言上下文in the water回答了boat,然而GGE-DQ提供了正确的回答tv和television,且有更显著的视觉区域。这些例子定性的验证了预测的准确率和视觉解释两方面的提升。
六、总结
本文分析了几种鲁棒VQA的方法,并提出一个新的框架来减少语言偏见。我们证明了VQA的语言偏见可以分为分布偏见和shortcut偏见,然后提出一种贪婪梯度集成策略来逐步消除这两种偏见。实验结果表明我们的偏见分解的合理性和GGE的有效性。我们相信GGE背后的想法是有价值的,并有可能成为数据集偏差问题的通用方法。在未来,我们将扩展GGE来解决其他任务的偏差问题,提供更严格的分析来保证模型的收敛性,并学习在没有先验知识的情况下自动检测不同类型的偏差特征。
边栏推荐
- Shell script series (1) getting started
- Window 加密壳实现
- Overview of Tsinghua & Huawei | semantic communication: Principles and challenges
- [array] sword finger offer II 012 The sum of left and right subarrays is equal | sword finger offer II 013 Sum of two dimensional submatrix
- DAMA、DCMM等数据管理框架各个能力域的划分是否合理?有内在逻辑吗?
- Parameter estimation -- Chapter 7 study report of probability theory and mathematical statistics (point estimation)
- Qingscan use
- Paddlepaddle 21 is implemented based on dropout with 4 lines of code droplock
- I found a JSON visualization tool artifact. I love it!
- Microsoft365 developer request
猜你喜欢

Learn Tai Chi maker mqtt (IX) esp8266 subscribe to and publish mqtt messages at the same time

Record the method of reading excel provided by unity and the solution to some pits encountered

Parameter estimation -- Chapter 7 study report of probability theory and mathematical statistics (point estimation)

Flink学习4:flink技术栈

栈溢出漏洞

How does source insight (SI) display the full path? (do not display omitted paths) (turn off trim long path names with ellipses)
Flink learning 2: application scenarios

Flink学习3:数据处理模式(流批处理)

超級詳細,2 萬字詳解,吃透 ES!
CVPR2022 | PointDistiller:面向高效紧凑3D检测的结构化知识蒸馏
随机推荐
Questions and answers of chlor alkali electrolysis process in 2022
pytorch_grad_cam——pytorch下的模型特征(Class Activation Mapping, CAM)可视化库
PAT甲级 1020 Tree Traversals
Flink学习1:简介
Solve the problem of error reporting in cherry pick submission
学习太极创客 — MQTT(六)ESP8266 发布 MQTT 消息
pytorch_ grad_ Cam -- visual Library of class activation mapping (CAM) under pytorch
Oracle/PLSQL: Ltrim Function
455. distribute biscuits [distribution questions]
清华&华为等 综述 | 语义通信:原则与挑战
Lodash get JS code implementation
Paddlepaddle 19 dynamically modify the last layer of the model
1、项目准备与新建
TechSmith Camtasia最新2022版详细功能讲解下载
[array] sword finger offer II 012 The sum of left and right subarrays is equal | sword finger offer II 013 Sum of two dimensional submatrix
Constraintlayout Development Guide
paddlepaddle 19 动态修改模型的最后一层
平均风向风速计算(单位矢量法)
2022 operation of simulated examination platform for tea artist (Senior) work license question bank
Yalm 100b: 100billion parameter open source large model from yandex, Russia, allowing commercial use