当前位置:网站首页>AMD64(x86_64)架构abi文档:中
AMD64(x86_64)架构abi文档:中
2022-07-26 02:26:00 【坤昱】
本篇基于<<AMD64(x86_64)架构abi文档:上>>延伸章节。
4 对象文件
4.1 ELF Header
4.1.1 机器信息
4.1.2 程序头数量
4.2 Section
4.2.1 Section标志
4.2.2 Section类型
4.2.3 特殊Section
4.2.4 EH_FRAME sections
4.3 符号表
4.4 重定位
4.4.1 重定位类型
4.4.2 大型模型
5 程序加载和动态链接
5.1 程序加载
5.1.1 程序头
5.2 动态链接
5.2.1 程序解释器
5.2.2 初始化和终止函数
6 函数库
6.1 C函数库
6.1.1 全局数据符号
6.1.2 浮点环境函数
6.2 展开库接口
6.2.1 异常处理程序框架
6.2.2 数据结构
6.2.3 抛出异常
6.2.4 异常对象管理
6.2.5 上下文管理
6.2.6 个性常规
6.3 通过汇编代码展开
7 开发环境
8 执行环境
9 约定
9.1 C++
9.2 Fortran
9.2.1 名称
9.2.2 Fortran类型的表示
9.2.3 参数传递
9.2.4 函数
9.2.5 公用块
9.2.6 Intrinsics
10 ILP32编程模型
10.1 参数传递
10.2 地址空间
10.3 线程本地存储支持
10.3.1 全局线程局部变量
目录预览
4 对象文件
4.1 ELF Heade
4.1.1 机器信息
编程模型
如第1节所述,使用AMD64指令集的二进制文件可以编程为32位模型(ILP32)或64位模型(LP64)。该规范描述了使用ILP32和LP64模型的二进制文件。
文件类
对于AMD64类型的ILP32对象,e_ident[EI_CLASS]中的文件类值必须为ELFCLASS32。对于AMD64 LP64对象,文件类的值必须是ELFCLASS64。
数据编码
对于e_ident[EI_DATA]中的数据编码,AMD64对象使用ELFDATA2LSB。
处理器标识
处理器标识驻留在ELF headers e_machine成员中,并且必须具有EM_X86_64的值。¹
¹ 该标识符的值为62。
4.1.2 程序头数量
e_phnum成员包含程序头表中的条目数。e_phentsize和e_phnum的乘积以字节为单位给出了表的大小。如果文件没有程序头表,e_phnum的值为0。
如果程序头文件的数量大于或等于PN_XNUM (0xffff),则该成员的值为PN_XNUM (0xffff)。程序头表项的实际数量包含在section头索引0的sh_info字段中。否则,初始条目的sh_info成员的值为0。
4.2 Section
4.2.1 Section标志
为了允许链接不同代码模型的目标文件,有必要提供一种方法来区分那些可能包含超过2GB的部分和那些可能不包含的部分。这是通过为sh_flag定义一个特定于处理器的section属性标志来实现的(见表4.1)。

SHF_X86_64_LARGE 如果一个object file section没有设置此标志,那么它可能不会超过2GB,可以使用较小的代码模型在对象中自由引用。否则,只有使用较大代码模型的对象才能引用它们。例如,一个中等代码模型对象除了能够引用没有设置该标志的部分的数据之外,还可以引用设置该标志的部分的数据;同样地,小代码模型对象只能引用未设置此标志的部分中的代码。
4.2.2 Section类型

SHT_X86_64_UNWIND 本节包含用于堆栈展开的展开函数表项。本文档4.2.4节介绍内容。
4.2.3 特殊Section

.got 本段保存着全局偏移表。
.plt 本段保存过程链接表。
.eh_frame 本段保存unwind函数表。本文档4.2.4节介绍内容。
表4.4中定义的附加部分由支持大型代码模型的系统使用。

为了使用不同代码模型的对象的静态链接,建议采用以下分段排序:
.plt .init .fini .text .got .rodata .rodata1 .data .data1 .bss 这些段的总大小可达2GB。
.lplt .ltext .lgot .lrodata .lrodata1 .ldata .ldata1 .lbss 这些段加上上述段的总大小可达16EB。
4.2.4 EH_FRAME sections
展开堆栈所需的调用帧信息被输出到一个或多个类型为SHT_X86_64_UNWIND的ELF段。在最简单的情况下,每个对象文件将有一个这样的段,它将被命名为.eh_frame。eh_frame section由一个或多个子section组成。每个小节包含一个CIE(公共信息条目),后面跟着不同数量的FDEs(帧描述符条目)。一个FDE对应于一个编译单元中显式的或编译器生成的函数,所有的FDE都可以访问其分段开始的CIE来获取数据。如果函数的代码不是一个连续的块,那么每个连续的子块将有一个单独的FDE。
如果一个对象文件包含c++模板实例化,那么在每个实例化对应的FDE之前应该有一个单独的CIE。
使用下面指定的首选编码,.eh_frame部分可以在链接时完全解析,因此可以成为文本段的一部分。
下面的EH_PE编码指的是在e_frame_hdr增强的LSB第七章中指定的指针编码。




可选调用帧指令区域的存在和大小必须基于总体大小和扫描CIE或FDE的前面字段时达到的偏移量来计算。
ELF section头给出了.eh_frame section的总体大小。确定条目数量的唯一方法是扫描到最后,在遇到条目时计数。
4.3 符号表
第5.2节中关于“函数地址”的讨论为符号表字段定义了一些特殊的值。
STT_GNU_IFUNC符号类型是可选的。它与STT_FUNC相同,不同的是它总是指向一个不带参数并返回函数指针的函数或可执行代码段。如果一个STT_GNU_IFUNC符号被重定位函数引用,那么该重定位函数的求值将被延迟到加载时。重定位中使用的值是调用STT_GNU_IFUNC符号返回的函数指针。
STT_GNU_IFUNC符号类型的目的是允许运行时在特定函数的多个实现版本之间进行选择。一般的选择将考虑到当前可用的硬件,并选择最合适的版本。
Linux对gABI的扩展: https://github.com/hjl-tools/linux-abi
4.4 重定位
4.4.1 重定位类型
图4.4.1显示了允许重定位的字段。

| 类型 | 说明 |
|---|---|
| word8 | 指定一个占用1字节的8位字段 |
| word16 | 指定一个16位字段,它使用任意的字节对齐方式占用2个字节。这些值与AMD64体系结构中的其他字值使用相同的字节顺序 |
| word32 | 指定一个32位字段,该字段使用任意字节对齐方式占用4个字节。这些值与AMD64体系结构中的其他字值使用相同的字节顺序 |
| word64 | 指定一个64位字段,该字段使用任意字节对齐方式占用8个字节。这些值与AMD64体系结构中的其他字值使用相同的字节顺序 |
| wordclass | 为LP64指定word64,为ILP32指定word32 |
表4.9中用于指定重定位的符号如下:
A 表示用于计算可重定位字段的值的加数。
B 表示在执行期间将共享对象加载到内存中的基址。通常,共享对象使用0基数的虚拟地址构建,但执行地址会有所不同。
G 表示重定位表项的符号在执行期间驻留在全局偏移表中的偏移量。
GOT 表示全局偏移表的地址。
L 表示符号的过程链接表项的位置(节偏移量或地址)。
P 表示被重新定位的存储单元的位置(区域偏移量或地址)(使用r_offset计算)。
S 表示其索引驻留在重定位项中的符号的值。
Z 表示其索引驻留在重定位项中的符号的大小。
AMD64 LP64 ABI架构只使用带有显式加数的Elf64_Rela重定位表项。r_addend成员用作重定位的加数。
AMD64 ILP32 ABI架构只在可重定位文件中使用Elf32_Rela重定位表项。可执行文件或共享对象可以使用Elf32_Rela或Elf32_Rel重定位表项。

† 这种重定位仅用于LP64。
†† 这种重定位只出现在ILP32可执行文件或共享对象中。
大多数重定位类型的特殊语义与Intel386 ABI中使用的相同。
R_X86_64_GOTPCREL重定位与R_X86_64_GOT32或等价的i386 R_386_GOTPC重定位具有不同的语义。特别是,由于AMD64体系结构具有相对于指令指针的寻址模式,因此可以使用单个指令从GOT加载地址。由R_X86_64_GOTPCREL重定位完成的计算给出了给出符号地址的GOT中的位置与应用重定位的位置之间的差异。
在以下汇编指令中出现[email protected]:
call *[email protected](%rip)
jmp *[email protected](%rip)
mov [email protected](%rip), %reg
test %reg, [email protected](%rip)
binop [email protected](%rip), %reg
其中binop是adc, add, and, cmp, or, sbb, sub, xor指令之一,应该生成R_X86_64_GOTPCRELX重定位,或R_X86_64_REX_GOTPCRELX重定位,如果REX前缀存在,应该生成R_X86_64_GOTPCREL重定位,而不是R_X86_64_GOTPCREL重定位。
R_X86_64_32和R_X86_64_32S重定位将计算值截断为32位。链接器必须验证R_X86_64_32 (R_X86_64_32S)重定位生成的值0 -extends (sign-extends)到原来的64位值。
使用R_X86_64_8、R_X86_64_16、R_X86_64_PC16的程序或目标文件或R_X86_64_PC8重定位与ABI不一致,这些重定位仅为文档目的而添加。R_X86_64_16和R_X86_64_8重定位将计算值截断为16位、8位。
R_X86_64_DTPMOD64、R_X86_64_DTPOFF64、R_X86_64_TPOFF64、R_X86_64_TLSGD、R_X86_64_TLSLD、R_X86_64_DTPOFF32、R_X86_64_GOTTPOFF和R_X86_64_TPOFF32的重定位为列的完整性。它们是线程本地存储ABI扩展的一部分,并在名为“线程本地存储ELF处理”的文档中进行了记录。
尽管AMD64体系结构支持ip相对寻址模式,但仍然需要GOT,因为静态连接器无法知道从特定指令到特定数据项的偏移量。
注意,AMD64体系结构假设GOT的偏移量是32位值,而不是64位值。这个选择意味着最多可以在GOT中放置2^32/8 = 2^29的条目。然而,这对大多数程序来说已经足够了。如果这还不够,链接器可以创建多个got。由于使用了32位偏移量,加载全局数据不需要将偏移量加载到位移寄存器;可以使用基础加直接位移寻址形式。
此文档目前可通过via http://www.akkadia.org/drepper/tls.pdf。
重定位R_X86_64_GOTPC32_TLSDESC、R_X86_64_TLSDESC_CALL和R_X86_64_TLSDESC也用于线程本地存储,但在撰写本文时没有记录。在文档“线程本地存储描述符为IA32和AMD64/EM64T”中可以找到一个描述。
为了使该文档自包含,以下是对TLS重新定位的描述。
%fs段寄存器用于实现线程指针。线程指针的线性地址存储在相对于%fs段寄存器的偏移量0处。下面的代码加载%rax寄存器中的线程指针:
movq %fs:0, %rax
R_X86_64_DTPMOD64解析为指向对应于定义引用符号的模块的TLS块基址的动态线程向量条目的索引。R_X86_64_DTPOFF64和R_X86_64_DTPOFF32计算从该条目中的指针到被引用符号的偏移量。对于R_X86_64_TLSGD和R_X86_64_TLSLD的重定位,链接器在GOT中相邻的表项中产生这样的重定位。如果链接器可以自己计算偏移量,因为被引用的符号在本地绑定,重定位R_X86_64_64和R_X86_64_32可能会被使用代替。否则,这样的重定位总是成对的,这样R_X86_64_DTPOFF64重定位应用于对应的R_X86_64_DTPMOD64重定位后面的字64。
R_X86_64_TPOFF64和R_X86_64_TPOFF32解析线程指针到线程局部变量的偏移量。前者是根据R_X86_64_GOTTPOFF生成的,它解析为一个包含64位偏移量的GOT条目的相对pc地址。
R_X86_64_TLSLD和R_X86_64_TLSLD都解析到DTPMOD GOT条目的pc相对偏移量。它们之间的区别是,对于R_X86_64_TLSGD,下面的GOT项将包含被引用符号到其TLS块的偏移量,而对于R_X86_64_TLSLD,下面的GOT项将包含TLS块的基址的off集。这个想法是,将这个偏移量添加到一个符号的R_X86_64_DTPMOD32的结果中,对于同一个符号应该得到与R_X86_64_DTPMOD64相同的结果。
R_X86_64_TLSDESC解析为一对word64s,称为TLS描述符,第一个是指向函数的指针,后面是一个参数。函数传递一个指向%rax中这对表项的指针,并且使用第二个表项中的参数,它必须计算并返回从线程指针到重定位中引用的符号的偏移量,而不修改除处理器标志之外的任何寄存器。R_X86_64_GOTPC32_TLSDESC解析为与已命名符号相对应的TLS描述符的pc -相对地址。R_X86_64_TLSDESC_CALL必须注释用于调用TLS描述符解析器函数的指令,以便启用该指令的松弛。
R_X86_64_IRELATIVE类似于R_X86_64_RELATIVE,不同之处在于重定位中使用的值是函数返回的程序地址,该函数在对应的R_X86_64_RELATIVE重定位结果的地址处不带参数。
R_X86_64_IRELATIVE重定位的一个用途是避免在加载时对本地定义的STT_GNU_IFUNC符号进行名称查找。对这种重定位的支持是可选的,但对于STT_GNU_IFUNC符号是必需的。
4.4.2 大型模型
为了将PLT和GOT扩展到2GB以上,有必要添加适当的重定位类型来处理完整的64位寻址。参见图4.10。

5 程序加载和动态链接
5.1 程序加载
程序加载是将文件段映射到虚拟内存段的过程。为了有效地映射可执行文件和共享object文件,必须有文件偏移量和虚拟地址对页面大小取模相等的段。
为了节省空间,保存文本段的最后一页的文件页也可以包含数据段的第一页。最后一个数据页可能包含与正在运行的进程无关的文件信息。在逻辑上,系统强制内存权限,就好像每个段都是完整的和独立的;对段的地址进行调整,以确保地址空间中的每个逻辑页都有一组权限。在上面的例子中,保存文本结尾和数据开头的文件区域将被映射两次:一个虚拟地址用于文本,另一个虚拟地址用于数据。
数据段的末尾需要对未初始化的数据进行特殊处理,系统将其定义为0值开始。因此,如果文件的最后一个数据页包含不在逻辑内存页中的信息,则必须将无关数据设置为零,而不是可执行文件的未知内容。其他三个页面中的“杂质”在逻辑上不是流程映像的一部分;系统是否删除未指定。
段加载在可执行文件和共享对象之间的一个方面是不同的。可执行文件段通常包含绝对代码(参见3.5节“编码示例”)。为了正确地执行进程,段必须驻留在用于构建可执行文件的虚拟地址。因此,系统使用未更改的p_vaddr值作为虚拟地址。
另一方面,共享对象段通常包含位置无关的代码。这允许段虚拟地址从一个进程更改到另一个进程,而不会使执行行为失效。虽然系统为各个进程选择虚拟地址,但它保持段的相对位置。由于位置无关代码在段之间使用相对寻址,因此虚拟地址之间存在差异在内存中必须匹配文件中虚拟地址之间的差异。
5.1.1 程序头
定义了以下AMD64程序头类型:
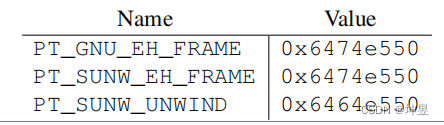
PT_GNU_EH_FRAME, PT_SUNW_EH_FRAME和PT_SUNW_UNWIND段包含堆栈展开表。参见本文档的第4.2.4节。
5.2 动态链接
Dynamic Section
动态段条目向动态链接器提供信息。其中一些信息是特定于处理器的,包括对动态结构中某些条目的解释。
Global Offset Table (GOT)
位置无关的代码通常不能包含绝对虚拟地址。全局偏移表在私有数据中保存绝对地址,因此在不影响位置独立性和程序文本的可共享性的情况下使地址可用。程序使用与位置无关的寻址来引用它的全局偏移表,并提取绝对值,从而将与位置无关的引用重定向到绝对位置。
为了适应现有的GNU实现,这些程序头的值已经放在PT_LOOS和PT_HIOS (os特定的范围)中。新的操作系统想要同意这些程序头也应该添加到他们的操作系统特定范围。
如果一个程序需要直接访问一个符号的绝对地址,该符号将有一个全局偏移表项。因为可执行文件和共享对象有单独的全局偏移表,一个符号的地址可能出现在几个表中。动态连接器在将控制权交给进程映像中的任何代码之前处理所有的全局偏移表重定位,从而确保在执行期间绝对地址是可用的。
表的第一个条目(数字0)被保留用来保存动态结构的地址,用符号_DYNAMIC引用。这允许一个程序,比如动态链接器,在没有处理重定位项的情况下找到它自己的动态结构。这对于动态链接器尤其重要,因为它必须初始化自己,而不依赖于其他程序来重新定位它的内存映像。在AMD64架构中,全局偏移表中的表项1和表项2也是保留的。
全局偏移表包含64位地址。
对于大型模型,GOT的尺寸可以达到16EB。
extern Elf64_Addr _GLOBAL_OFFSET_TABLE_ [];
符号_GLOBAL_OFFSET_TABLE_可以位于.got部分的中间,允许地址数组中存在负的和非负的偏移量。
函数地址
从可执行文件和与之关联的共享对象引用函数的地址可能不会解析为相同的值。来自共享对象的引用通常会被动态链接器解析为函数本身的虚地址。在可执行文件中对共享对象中定义的函数的引用通常会被链接编辑器解析为该函数在可执行文件中的过程链接表项的地址。
为了允许函数地址的比较按预期进行,如果一个可执行文件引用了一个在共享对象中定义的函数,链接编辑器将把该函数的过程链接表项的地址放在其关联的符号表项中。这将产生section索引为SHN_UNDEF但类型为STT_FUNC且st_value非零的符号表项。从共享库中引用函数的地址将由可执行文件中的这样的定义来满足。
有些重定位与过程链接表项相关联。这些条目用于直接调用函数,而不是引用函数地址。这些重定位不使用上面描述的特殊符号值。否则就会形成一个非常紧密的无限循环。
程序链接表
就像全局偏移表将位置无关的地址计算重定向到绝对位置一样,过程链接表将位置无关的函数调用重定向到绝对位置。链接编辑器无法解析从一个可执行或共享对象到另一个对象的执行传输(如函数调用)。因此,链接编辑器安排程序将控制转移到过程链接表中的条目。在AMD64架构中,过程链接表驻留在共享文本中,但是它们使用私有全局偏移表中的地址。动态连接器确定目的地的绝对地址,并相应地修改全局偏移表的内存映像。因此,动态连接器可以在不影响位置独立性和程序文本的可共享性的情况下重定向条目。可执行文件和共享object文件具有单独的过程链接表。与Intel386 ABI不同的是,这个ABI对程序和共享对象使用相同的过程链接表(参见图5.2)。

按照下面的步骤,动态连接器和程序“合作”,通过过程链接表和全局偏移表解析符号引用。
1. 当第一次创建程序的内存映像时,动态连接器将全局偏移表中的第二个和第三个条目设置为特殊值。下面的步骤将详细解释这些值。
2. 进程映像中的每个共享object文件都有自己的过程链接表,并且控制只能从同一个对象文件中传输到一个过程链接表条目。
3. 为了说明这一点,假设程序调用了name1,它将控制转移到标签. plt1。
4. 第一条指令跳转到name1的全局偏移表条目中的地址。最初,全局偏移表保存了以下pushq指令的地址,而不是name1的真实地址。
5. 现在程序将一个重定位索引(index)压入堆栈。重定位索引是一个32位的非负索引,指向由DT_JMPREL动态section表项寻址的重定位表。指定的重定位表项类型为R_X86_64_JUMP_SLOT,它的偏移量将指定在前面的jmp指令中使用的全局偏移表项。重定位表项包含一个符号表索引,该索引将引用相应的符号,在本例中为name1。
6. 推入重定位索引后,程序跳转到. plt0,这是程序链接表中的第一个条目。pushq指令将第二个全局偏移表项(GOT+8)的值放在堆栈上,从而给动态连接器一个单词的标识信息。然后,程序跳转到第三个全局偏移表项(GOT+16)中的地址,这将控制传递给动态连接器。
7. 当动态连接器接收到控制时,它打开堆栈,查看指定的重定位表项,找到符号的值,将name1的“真实”地址存储在它的全局偏移表项中,并将控制传输到想要的目的地。
8. 后续的过程链接表条目的执行将直接转移到name1,而不需要第二次调用动态连接器。也就是说. plt1的jmp指令将转移到name1,而不是“下发”到pushq指令。
LD_BIND_NOW环境变量可以更改动态链接行为。如果其值为非空,则动态连接器在将控制转移到程序之前评估过程链接表项。也就是说,动态连接器在进程初始化时处理R_X86_64_JUMP_SLOT类型的重定位表项。否则,动态连接器会惰性地评估过程链接表项,将符号解析和重定位延迟到表项第一次执行时。
R_X86_64_TLSDESC类型的重定位表项也可能会被延迟重定位,使用过程链接表和全局偏移表中的单个表项,分别位于DT_TLSDESC_PLT和DT_TLSDESC_GOT指定的位置,如“线程本地存储描述符为IA32和AMD64/EM64T”中描述的。
对于自包含,DT_TLSDESC_GOT指定了一个GOT条目,动态加载器应该在其中存储其内部TLS描述符解析器函数的地址,而DT_TLSDESC_PLT指定了一个PLT条目的地址,该PLT条目将被用作该模块内部的TLS描述符解析器函数的延迟解析。PLT条目必须将模块的linkmap推入堆栈并尾部调用内部TLS描述符解析器函数。
大型模型
在中小型代码模型中,PLT和GOT的大小都受限于最大32位位移大小。因此,PLT的底部和GOT的顶部最多只能相距2GB。
因此,为了支持16EB的可用寻址空间,有必要对PLT和GOT进行扩展。此外,PLT需要支持超过2GB的GOT,而GOT的大小可以超过2GB。
假设GOT地址在%r15中,对PLT进行了扩展,如图5.3所示。
该文件目前可用via http://www.fsfla.org/~lxoliva/writeups/TLS/RFC-TLSDESC-x86.txt
如果确定PLT的基础在GOT的顶部2GB以内,也允许对大型代码模型对象使用与中小型代码模型相同的PLT布局。

这样,对于前102261125个条目,除. plt0外,每个PLT条目只使用21个字节。之后,当每个PLT条目长度为27字节时,PLT条目代码通过重复. plt0的代码来改变。请注意,为了保持PLT尺寸下降,任何对齐考虑都被删除了。
因此,每个扩展的PLT条目比中小型代码模型PLT条目大5到11个字节。
入口. plt0的功能在中小型代码模型中保持不变。
注意,符号索引仍然被限制在32位,这将允许最多4G的全局和外部功能。
通常,UNIX编译器支持两种类型的PLT,通常通过选项-fPIC和-fPIC。当使用大型代码模型构建位置无关对象时,只允许使用-fPIC。在大型代码模型中使用选项-fpic保留到将来使用。
5.2.1 程序解释器
表5.4列出了符合AMD64 ABI的程序的有效程序解释器,其中也包含了Linux使用的程序解释器。

5.2.2 初始化和终止函数
该实现负责执行由可执行文件和共享对象文件中的DT_INIT、DT_INIT_ARRAY和DT_PREINIT_ARRAY项指定的初始化函数,以及由System V ABI指定的DT_FINI和DT_FINI_ARRAY指定的终止(或终结)函数。用户程序不再执行由这些动态标记指定的初始化和终止函数。
6 函数库
需要对Intel386 ABI进行进一步的分析。
6.1 C函数库
6.1.1 全局数据符号
AMD64 ABI没有提供_fp_hw, __flt_rounds和__huge_val这些符号。
6.1.2 浮点环境函数
ISO C 99定义了来自的浮点环境函数。由于AMD64有两个具有单独控制字的浮点单元,编程环境必须保持控制值同步。另一方面,这意味着访问控制字的例程只需要访问一个单元,而SSE单元是在这些情况下应该访问的单元。因此,fegetround函数只需要报告SSE单元的舍入值,可以忽略x87单元。
6.2 展开库接口
本节定义了Unwind库接口1,期望由任何符合AMD64 psabi的系统提供。c++ ABI异常处理工具就是在这个接口上构建的。我们假设以DWARF调试信息格式文档中描述的调用帧信息表为基础。
整体结构和外部接口来源于IA-64 UNIX System V ABI
本节旨在指定一个与语言无关的接口,该接口可用于提供更高级别的异常处理功能,如c++定义的那些功能。
unwind库接口至少包含以下例程:
_Unwind_RaiseException ,
_Unwind_Resume ,
_Unwind_DeleteException ,
_Unwind_GetGR ,
_Unwind_SetGR ,
_Unwind_GetIP ,
_Unwind_GetIPInfo ,
_Unwind_SetIP ,
_Unwind_GetRegionStart ,
_Unwind_GetLanguageSpecificData ,
_Unwind_ForcedUnwind ,
_Unwind_GetCFA
此外,还定义了两种数据类型(_Unwind_Context和_Unwind_Exception)来与调用运行时(比如c++运行时)和上述例程进行接口。所有例程和接口的行为就像定义的extern “C”。特别是,名字没有被破坏。定义为该接口一部分的所有名称都有一个“Unwind”前缀。
最后,编译器将把特定于语言和供应商的个性例程存储在unwind描述符中,用于需要进行异常处理的堆栈帧。人格例程由解码器调用来处理特定于语言的任务,例如识别处理特定异常的框架。
6.2.1 异常处理程序框架
退出的原因
展开堆栈有两个主要原因:
异常,由支持它们的语言(如c++)定义。
“强制”unwind(如由longjmp或线程终止引起的)。
这里描述的接口试图保持两者相似。然而,有一个主要的区别:
在抛出异常的情况下,堆栈在异常传播时展开,但预计每个堆栈框架的个性例程知道它是想捕获异常还是传递异常。因此,这种选择被委托给了人格惯例,它被期望对任何类型的例外,无论是“本土的”或“外国的”采取适当的行动。下面给出了一些“适当行事”的准则。
另一方面,在“强制解除”过程中,外部因素正在推动解除。例如,这可以是longjmp例程。这个外在的代理人,不是每个人格惯例,知道什么时候停止放松。人格例程没有选择是否继续展开,这是由_UA_FORCE_UNWIND标志指示的。
为了适应这些差异,提出了两种不同的例程。_Unwind_RaiseException在人格例程控制下执行异常风格的展开。另一方面,_unwind_forceunwind执行unwind,但让外部代理有机会拦截对个性例程的调用。这是使用代理人格例程完成的,它拦截对人格例程的调用,让外部代理覆盖堆栈框架的人格例程的默认值。
因此,对于每个人格惯例来说,没有必要知道任何可能导致放松的外部因素。例如,c++个性例程只需要处理c++异常(可能还需要伪装外部异常),但它不需要知道关于为longjmp或pthreads取消而展开的任何具体信息。
展开过程
标准ABI异常处理/展开过程从抛出异常开始,以上面提到的一种形式。此调用指定异常对象和异常类。
然后运行时框架启动一个两阶段的过程:
在搜索阶段,框架反复调用人格例程,使用_UA_SEARCH_PHASE标记,如下所述,首先针对当前%rip和注册状态,然后在每一步展开一个框架到一个新的%rip,直到人格例程在所有框架中报告成功(在查询的框架中找到一个处理程序)或失败(没有处理程序)。它实际上并没有恢复解除的状态,个性例程必须通过API访问状态。
如果搜索阶段报告失败,例如因为没有找到处理程序,它将调用terminate()而不是开始阶段2。
如果搜索阶段报告成功,则框架将在清理阶段重新启动。它再次重复调用人格例程,使用_UA_CLEANUP_PHASE标志,如下所述,首先用于当前%rip和注册状态,然后在每一步unwind一个帧到一个新的%rip,直到它到达带有标识处理程序的帧。此时,它将恢复寄存器状态,并将控制权转移到用户的着陆垫代码。
这两个阶段都使用unwind库和个性例程,因为给定处理程序的有效性和向它传递控制的机制与语言有关,但定位和恢复以前的堆栈帧的方法与语言无关。
两阶段异常处理模型对于实现c++语言语义并不是严格必要的,但是它确实提供了一些好处。例如,第一个阶段允许异常处理机制在堆栈展开之前拒绝异常,这允许假定异常处理(纠正异常条件并在引发异常的地方恢复执行)。虽然c++不支持假定异常处理,但其他语言支持,两阶段模型允许c++与堆栈上的这些语言共存。
请注意,即使是两阶段模型,对于单个异常,我们也可以不止一次地执行这两个阶段的每个阶段,就好像该异常被多次抛出一样。例如,由于无法确定给定的catch子句在不执行它的情况下是否会重新抛出,因此异常传播在每个catch子句处有效地停止,如果需要重新启动,则在阶段1重新启动。析构函数(清除代码)不需要这个过程,因此阶段1可以安全地一次性处理所有析构函数框架,并在下一个封闭的catch子句处停止。
例如,如果展开的前两帧只包含清理代码,而第三帧包含c++ catch子句,那么阶段1中的个性例程并不能表明它找到了前两帧的处理程序。对于第三帧,它必须这样做,因为不知道异常将如何传播到第三帧,例如通过重新抛出异常或在c++中抛出一个新的异常。
AMD64 psABI为实现这个框架指定的API将在下面几节中描述。
6.2.2 数据结构
原因代码
unwind接口在多个上下文中使用原因代码来识别失败或其他操作的原因,定义如下:
typedef enum {
_URC_NO_REASON = 0,
_URC_FOREIGN_EXCEPTION_CAUGHT = 1,
_URC_FATAL_PHASE2_ERROR = 2,
_URC_FATAL_PHASE1_ERROR = 3,
_URC_NORMAL_STOP = 4,
_URC_END_OF_STACK = 5,
_URC_HANDLER_FOUND = 6,
_URC_INSTALL_CONTEXT = 7,
_URC_CONTINUE_UNWIND = 8
} _Unwind_Reason_Code;
下面描述了这些代码的解释。
异常头
unwind接口使用指向异常头对象的指针作为正在抛出的异常的表示。通常,异常对象的完整表示是特定于语言和实现的,但它的前缀是一个可以被unwind接口理解的头,定义如下:
typedef void (*_Unwind_Exception_Cleanup_Fn)
(_Unwind_Reason_Code reason,
struct _Unwind_Exception *exc);
struct _Unwind_Exception {
uint64 exception_class;
_Unwind_Exception_Cleanup_Fn exception_cleanup;
uint64 private_1;
uint64 private_2;
};
_Unwind_Exception对象必须是八字节对齐的。前两个字段在引发异常之前由用户代码设置,后两个字段除了运行时之外永远不应该被触及。
exception_class字段是异常类型的特定于语言和实现的标识符。例如,它允许人格程序区分本土和外来的例外。按照惯例,高的4个字节表示供应商(例如AMD\0),低的4个字节表示语言。对于本文档中描述的c++ ABI,较低的四个字节是c++ \0。
每当一个异常对象需要由一个不同于创建异常对象的运行时销毁时,就会调用exception_cleanup例程,例如,如果Java异常被c++ catch处理程序捕获。在这种情况下,一个原因代码(见上面)表示为什么需要删除异常对象:
_URC_FOREIGN_EXCEPTION_CAUGHT = 1 这表明不同的运行时捕获了此异常。嵌套的外部异常或重新抛出外部异常会导致未定义的行为。
_URC_FATAL_PHASE1_ERROR = 3 个性例程在第1阶段遇到错误,而不是定义的特定错误代码。
_URC_FATAL_PHASE2_ERROR = 2 个性化例程在第2阶段遇到错误,例如堆栈损坏。
正常情况下,所有错误都应该在阶段1通过返回_Unwind_RaiseException来报告。然而,着陆垫代码可能导致阶段1和阶段2之间的堆栈损坏。对于c++异常,在这种情况下,运行时应该调用terminate()。
异常对象中的私有解绕器状态(private_1和private_2)不应该被个性例程或语言特定运行时的其他部分读取或写入。它由主机上的解卷器的特定实现用于存储内部信息,例如在解卷阶段之间记住最后的处理程序帧。
除了上述信息之外,典型的运行时(如c++运行时)还会添加用于处理异常的特定于语言的信息。这应该是_Unwind_Exception对象之后的一块连续内存区域,但只要匹配的个性例程知道如何处理它,并且exception_cleanup例程正确地将其分配,就不需要这样做。
展开上下文
_Unwind_Context类型是一种不透明的类型,用于引用系统展开所使用的特定于系统的数据结构。这个环境是由系统创建和破坏的,并在展开过程中传递给个性程序。
struct _Unwind_Context
6.2.3 抛出异常
_Unwind_RaiseException
_Unwind_Reason_Code _Unwind_RaiseException
( struct _Unwind_Exception *exception_object );
引发异常,并传递给定的异常对象,该异常对象应该设置其exception_class和exception_cleanup字段。异常对象是由特定于语言的运行时分配的,并且具有特定于语言的格式,除了它必须包含一个_Unwind_Exception结构体(参见上面的exception头)。_Unwind_RaiseException不返回,除非找到错误条件(例如没有异常处理程序,错误的堆栈格式等)。在这种情况下,返回一个_Unwind_Reason_Code值。
可能性包括:
_URC_END_OF_STACK 在阶段1期间,展开器遇到堆栈的末端,但没有找到处理程序。unwind运行时不会修改堆栈。在这种情况下,c++运行时通常会调用uncaught_exception()。
_URC_FATAL_PHASE1_ERROR 解卷器在第一阶段遇到意外错误,例如栈损坏。unwind运行时不会修改堆栈。在这种情况下,c++运行时通常会调用terminate()。
如果展开器在阶段2遇到意外错误,它应该向它的调用者返回_URC_FATAL_PHASE2_ERROR。在c++中,这通常是__cxa_throw,它将调用terminate()。
unwind运行时可能已经修改了栈(例如从栈中弹出帧)或注册上下文,或者着陆垫代码可能已经损坏了它们。因此,_Unwind_RaiseException的调用者不能对其堆栈或寄存器的状态做出任何假设。
_Unwind_ForcedUnwind
typedef _Unwind_Reason_Code (*_Unwind_Stop_Fn)
(int version,
_Unwind_Action actions,
uint64 exceptionClass,
struct _Unwind_Exception *exceptionObject,
struct _Unwind_Context *context,
void *stop_parameter );
_Unwind_Reason_Code_Unwind_ForcedUnwind
( struct _Unwind_Exception *exception_object,
_Unwind_Stop_Fn stop,
void *stop_parameter );
引发强制展开的异常,传递给定的异常对象,该异常对象应该设置其exception_class和exception_cleanup字段。异常对象是由特定于语言的运行时分配的,并且具有特定于语言的格式,除了它必须包含一个_Unwind_Exception结构体(参见上面的exception头)。
强制展开是一个单阶段过程(正常异常处理过程的第2阶段)。stop和stop_parameter参数控制unwind进程的终止,而不是通常的个性例程查询。stop函数参数用于每个unwind帧,下面描述了通常的人格例程的参数,外加一个额外的stop_parameter。
当stop函数确定目标帧时,它将控制(根据自己未指定的约定)适当地传递给用户代码,而不返回,通常是在调用_Unwind_DeleteException之后。如果不是,它应该返回一个_Unwind_Reason_Code值,如下所示:
_URC_NO_REASON 这不是目标帧。unwind运行时将调用在动作中设置了_UA_FORCE_UNWIND和_UA_CLEANUP_PHASE标志的帧的个性例程,然后unwind到下一帧并再次调用stop函数。
_URC_END_OF_STACK 为了允许_unwind_forceunwind在到达堆栈末尾时执行特殊处理,unwind运行时将在最后一帧被拒绝后调用它,在上下文中使用NULL堆栈指针,而stop函数必须捕捉这个条件(即通过注意NULL堆栈指针)。如果它不能处理堆栈结束符,它可能返回此原因代码。
_URC_FATAL_PHASE2_ERROR stop函数可能会在其他致命的情况下返回此代码,例如栈损坏。
如果stop函数返回_URC_NO_REASON以外的任何原因代码,则从_unwind_forceunwind的调用方的角度来看,堆栈状态是不确定的。因此,unwind库应该向调用者返回_URC_FATAL_PHASE2_ERROR,而不是试图返回。
Example: longjmp_unwind()
longjmp_unwind()的预期实现如下所示。setjmp()例程将保存状态,以便在其习惯的位置恢复,包括帧指针。longjmp_unwind()例程将通过一个stop函数调用_unwind_forceunwind,该函数将上下文记录中的帧指针与保存的帧指针进行比较。如果相等,它将按惯例恢复setjmp()状态,否则将返回_URC_NO_REASON或_URC_END_OF_STACK。
如果确定了未来对两阶段强制展开的需求,则可以定义一个替代例程来请求它,并定义一个动作参数标志来支持它。
_Unwind_Resume
void _Unwind_Resume
(struct _Unwind_Exception *exception_object);
恢复现有异常的传播,例如在部分解缠的堆栈中执行清理代码后。在执行清理但没有恢复正常执行的停机坪的末端插入对这个例程的调用。它使unwind进一步进行。
_Unwind_Resume 不应用于实现重新抛出。对于展开运行时,重新抛出的catch代码是一个处理程序,并且在进入前一个展开会话之前终止它。重新抛出是通过对同一个异常对象再次调用_Unwind_RaiseException来实现的。
这是unwind库中唯一一个预计将由生成的代码直接调用的例程:在“停机坪”模型中,它将在停机坪的末端调用。
6.2.4 异常对象管理
_Unwind_DeleteException
void _Unwind_DeleteException
(struct _Unwind_Exception *exception_object);
删除给定的异常对象。如果给定的运行时在捕获外部异常后恢复正常执行,它将不知道如何删除该异常。这样的异常将通过调用_Unwind_DeleteException来删除。这是一个方便的函数,它调用异常头的exception_cleanup字段所指向的函数。
6.2.5 上下文管理
这些函数用于在放松库和个性例程和停机坪之间交流关于放松上下文的信息(例如,放松描述符和用户注册状态)。它们包括读取或设置堆栈框架中与给定解开上下文相对应的寄存器的上下文记录图像的例程,以及识别当前解开描述符和解开框架的位置的例程。
_Unwind_GetGR
uint64 _Unwind_GetGR
(struct _Unwind_Context *context, int index);
这个函数返回给定通用寄存器的64位值。寄存器由其索引标识,如图3.36所示。
在展开的两个阶段中,没有寄存器有一个保证值。
_Unwind_SetGR
void _Unwind_SetGR
(struct _Unwind_Context *context,
int index,
uint64 new_value);
这个函数设置给定寄存器的64位值,由_Unwind_GetGR的索引标识。
只有在展开的第二阶段调用该函数时,才能保证该行为,并将其应用于表示处理程序框架的展开上下文,个性例程将返回_URC_INSTALL_CONTEXT。在这种情况下,只应该使用寄存器%rdi, %rsi, %rdx, %rcx。这些scratch寄存器是为传递个性程序和着陆垫之间的参数而保留的。
_Unwind_GetIP
uint64 _Unwind_GetIP
(struct _Unwind_Context *context);
这个函数返回指令指针(IP)的64位值。
在展开过程中,该值保证是紧跟着展开上下文标识的函数中的调用位置的指令地址。对于已知不会返回的函数调用(例如_Unwind_Resume),这个值可能在过程片段之外。
通过异步信号和其他非调用位置展开的应用程序应该使用下面的_Unwind_GetIPInfo,以及函数提供的附加标志。
_Unwind_GetIPInfo
uint64 _Unwind_GetIPInfo
(struct _Unwind_Context *context, int *ip_before_insn);
这个函数返回与_Unwind_GetIP相同的值。此外,参数ip_before_insn必须不是空的,并且*ip_before_insn被更新为一个标志,表明返回的指针是在第一个尚未完全执行的指令处还是之后。
如果*ip_before_insn为false,调用_Unwind_GetIPInfo的应用程序应该假定提供的指令指针指向尚未返回的调用指令之后。通常,这意味着应用程序应该使用前面的调用指令作为unwind上下文的指令指针位置。通常,这可以通过从返回的指令指针中减去1来近似值。
如果*ip_before_insn为真,则指令指针不指向活动的调用站点。通常,这意味着指令指针指向异步信号到达的点。在这种情况下,应用程序应该使用_Unwind_GetIPInfo返回的指令指针作为unwind上下文的指令指针位置,无需进行调整。
_Unwind_SetIP
void _Unwind_SetIP
(struct _Unwind_Context *context,
uint64 new_value);
这个函数为解除上下文标识的例程设置指令指针(IP)的值。
只有当表示处理程序框架的展开上下文调用该函数时,才会保证这种行为,对于这个处理程序框架,个性例程将返回_URC_INSTALL_CONTEXT。在这种情况下,控制将被转移到给定的地址,该地址应该是一个停机坪的地址。
_Unwind_GetLanguageSpecificData
uint64 _Unwind_GetLanguageSpecificData
(struct _Unwind_Context *context);
这个例程返回当前堆栈帧的特定于语言的数据区域的地址。
这个例程并不是严格必需的:可以使用DWARF调用框架信息表的文档格式通过_Unwind_GetIP访问它,但是由于这项工作首先是为了查找个性例程,所以将结果缓存到上下文中是有意义的。我们也可以把它作为人格常规的参数传递。
_Unwind_GetRegionStart
uint64 _Unwind_GetRegionStart
(struct _Unwind_Context *context);
这个例程返回当前unwind描述符块所描述的过程或代码片段的开头地址。
要访问存储在过程片段开头的任何数据,都需要此信息。例如,可以相对于包含调用的过程片段的开头存储调用站点表。在展开期间,函数返回当前堆栈帧中包含调用点的过程片段的开始部分。
_Unwind_GetCFA
uint64 _Unwind_GetCFA
(struct _Unwind_Context *context);
这个函数返回64位规范帧地址,该地址被定义为前一帧调用点的%rsp值。当上下文被传递给个性例程或停止函数时,这个值保证是正确的。
6.2.6 个性常规
_Unwind_Reason_Code (*__personality_routine)
(int version,
_Unwind_Action actions,
uint64 exceptionClass,
struct _Unwind_Exception *exceptionObject,
struct _Unwind_Context *context);
个性例程是c++(或其他语言)运行时库中的函数,它充当系统unwind库和特定于语言的异常处理语义之间的接口。它特定于由放松信息块描述的代码片段,并且它总是通过放松信息块中的指针引用,因此它没有psabi指定的名称。
参数
个性常规参数如下:
version 展开运行时的版本号,用于检测展开约定与人格例程之间的不匹配,或提供向后兼容性。对于本文档中描述的约定,版本号为1。
actions 指示个性例程预期执行什么处理(作为位掩码)。下面描述了可能的操作。
exceptionClass 一个8字节的标识符,指定所抛出异常的类型。按照惯例,高的4个字节表示供应商(例如AMD\0),低的4个字节表示语言。对于本文档中描述的c++ ABI,较低的四个字节是c++ \0。这不是一个以空结束的字符串。有些实现可能不使用空字节。
exceptionObject 指向内存位置的指针,根据给定语言的语义记录处理异常所需的信息(参见上面的异常头部分)。
context 展开状态信息,供个性例程使用。这是个性例程用于访问框架寄存器的不透明句柄(参见上面的Unwind上下文部分)。
return value 个性例程的返回值指示进一步展开应该如何进行,以及可能的错误条件。请参阅下面的部分。
个性常规操作
个性例程的actions参数是以下一个或多个常量的按位OR:
typedef int _Unwind_Action;
const _Unwind_Action _UA_SEARCH_PHASE = 1;
const _Unwind_Action _UA_CLEANUP_PHASE = 2;
const _Unwind_Action _UA_HANDLER_FRAME = 4;
const _Unwind_Action _UA_FORCE_UNWIND = 8;
_UA_SEARCH_PHASE 指示个性例程应该检查当前帧是否包含处理程序,如果包含则返回_URC_HANDLER_FOUND,否则返回_URC_CONTINUE_UNWIND。“_UA_SEARCH_PHASE”和“_UA_CLEANUP_PHASE”不能同时设置。
_UA_CLEANUP_PHASE 指示个性例程应该为当前框架执行清理。个性例程可以通过调用嵌套过程来执行这种清理,并返回_URC_CONTINUE_UNWIND。或者,它可以设置寄存器(包括IP)来将控制转移到一个“着陆台”,并返回_URC_INSTALL_CONTEXT。
_UA_HANDLER_FRAME 在阶段2中,指示个性例程当前框架是在阶段1中标记为处理程序框架的框架。个性例程在阶段1和阶段2之间不允许改变它的想法,即它必须在阶段2处理这个框架中的异常。
_UA_FORCE_UNWIND 在阶段2期间,表示不允许任何语言“捕获”异常。该标志是在为longjmp解除堆栈或在线程取消期间设置的。catch子句中的用户定义代码仍然可以被执行,但是catch子句在完成时必须通过调用_Unwind_Resume来恢复展开。
将控制转移到着陆平台
如果个性例程决定它应该将控制转移到一个着陆平台(在阶段2),它可以通过调用上面的上下文管理例程,用合适的值设置寄存器(包括IP)以进入着陆平台(例如,带着陆平台参数)。然后返回_URC_INSTALL_CONTEXT。
在着陆台中执行代码之前,unwind库使用上下文记录将未被个性例程更改的寄存器恢复到抛出异常的调用之前该帧中的状态,如下所示。所有被基本ABI指定为被调用保存的寄存器都将被恢复,以及临时寄存器%rdi、%rsi、%rdx、%rcx(见下文)。除了这些异常之外,scratch(或调用者保存的)寄存器不会被保留,它们的内容在传输时是未定义的。
起落架可以恢复正常执行(例如,在c++ catch结束时),也可以通过调用_Unwind_Resume并向它传递个性例程接收到的exceptionObject参数来恢复展开。_Unwind_Resume永远不会返回。
当且仅当个性例程在阶段1没有返回_Unwind_HANDLER_FOUND时,应该调用_Unwind_Resume。因此,unwinder可以分配资源(例如实例内存)并在异常对象保留字中跟踪它们。然后,它应该释放这些资源,然后将控制权转移到最后一个(处理程序)停机坪。它不需要在进入非处理程序着陆区之前释放资源,因为_Unwind_Resume最终将被调用。
着陆台可以从运行时接收参数,通常在个性例程使用_Unwind_SetGR设置的寄存器中传递。对于一个可以调用_Unwind_Resume的停机坪,一个参数必须是exceptionObject指针,它必须保留下来传递给_Unwind_Resume。
起落架可以接收其他参数,例如指示异常类型的开关值。为此保留了四个刮痕寄存器(%rdi, %rsi, %rdx,%rcx)。
正确的跨语言操作规则
对于不同厂商的语言和/或运行时之间的正确操作,必须遵守以下规则:
具有未知类别的异常不能被个性例程改变。外部异常处理的语义取决于展开的堆栈帧的语言。这特别涵盖了如何将来自外语的异常映射到该框架中的母语。
如果一个运行时恢复正常执行,并且捕获的异常是由另一个运行时创建的,那么它应该调用_Unwind_DeleteException。即使它理解异常对象格式(例如不同的c++运行时之间的情况),这也是正确的。
如果将_UA_FORCE_UNWIND标志传递给个性例程,则不允许运行时捕获异常。
Example: Foreign Exceptions in C++. 在c++中,外部异常可以由catch(…)语句捕获。如果它们属于定义在中的__foreign_exception类,也可以捕获它们。如果运行时能够识别某些外语,则__foreign_exception可能有子类,如__java_exception和__ada_exception。
该行为在以下情况下是未定义的:
可以以任何方式访问__foreign_exception catch参数(包括取其地址)。
__foreign_exception与另一个异常同时是活动的(捕获外部异常时存在嵌套异常,或者外部异常本身被嵌套)。
Uncaught_exception()、set_terminate()、set_unexpected()、terminate()或unexpected()在存在外部异常时被调用(例如,在解除外部异常时调用set_terminate())。
所有这些情况都可能涉及到访问所抛出异常的c++特定内容,例如链接活动异常。
否则,允许一个捕获外部异常的catch块:
恢复正常执行,从而停止外部异常的传播并删除它,或
重新抛出外部异常。在这种情况下,原始异常对象必须不被c++运行时更改。
catch-all块可能在强制展开期间执行。例如,longjmp可以在堆栈展开期间执行catch(…)中的代码。但是,如果发生这种情况,不管是否存在显式的重新抛出,unwind都将在catch-all块的末尾进行。
将异常类的低4字节设置为c++ \0是保留给与通用c++ ABI兼容的c++运行时使用的。
6.3 通过汇编代码展开
为了在AMD64上成功展开,每个函数必须以DWARF调试信息格式提供有效的调试信息。在高级语言中(例如C/ c++, Fortran, Ada,…),这个信息是由编译器自己生成的。然而,对于手写的汇编例程,调试信息必须由代码的作者提供。为了简化这个任务,添加了一些新的汇编指令:
.cfi_startproc 在每个函数的开头使用,该函数应该在.eh_frame中有一个条目。它初始化一些内部数据结构,并发出依赖于体系结构的初始CFI指令。每个。cfi_startproc指令必须通过.cfi_endproc关闭。
.cfi_endproc 在函数的末尾使用,关闭之前由.cfi_startproc打开的unwind条目,并将其发出给.eh_frame。
.cfi_def_cfa REGISTER, OFFSET 定义了一个计算CFA的规则:从REGISTER中获取地址并向其添加OFFSET。
.cfi_def_cfa_register REGISTER 修改计算CFA的规则。从现在起,将使用REGISTER来代替旧的。偏移量保持不变。
.cfi_def_cfa_offset OFFSET 修改计算CFA的规则。寄存器保持不变,但是OFFSET是新的。请注意,这是将添加到已定义寄存器以计算CFA地址的绝对偏移量。
.cfi_adjust_cfa_offset OFFSET 类似于.cfi_def_cfa_offset,但是OFFSET是一个相对值,它是从前面的偏移量中添加或减去的。
.cfi_offset REGISTER, OFFSET 保存之前的寄存器值在offset offset从CFA。
.cfi_rel_offset REGISTER, OFFSET 保存当前CFA寄存器在offset处的REGISTER的前一个值。使用CFA寄存器的已知位移将其转换为.cfi_offset。这通常更容易使用,因为数字将与它注释的代码匹配。
.cfi_escape EXPRESSION[, …] 允许用户向unwind信息添加任意字节。可以使用它添加特定于操作系统的CFI操作码,或汇编器不支持的通用CFI操作码。

7 开发环境
在编译C或c++代码时,至少表7.1中的符号是由预处理器定义的。
2003年3月GCC 3.3中添加了__LP64和__LP64__。

8 执行环境
尚未完成。
9 约定
9.1 C++
对于c++ ABI,我们将使用IA-64 c++ ABI并适当地实例化它。该ABI的当前草案可在: http://mentorembedded.github.io/cxx-abi/
9.2 Fortran
不存在正式的Fortran ABI。大多数Fortran编译器都是为非常特定的高性能计算应用程序设计的,因此Fortran编译器使用不同的传递约定和内存布局,为其特定目的进行了优化。例如,必须运行在分布式内存机器上的Fortran应用程序需要不同于运行在对称多处理器共享内存机器上的应用程序的数组描述符(也称为dope vector或fat pointer)的数据表示。因此,规范的Fortran ABI是不可取的。但是,为了实现不同Fortran编译器的互操作性,以及与其他语言的互操作性,本节提供了一些数据类型表示和参数传递的指导原则。本节中的指南来源于GNU Fortran 77 (G77)编译器,并且GNU Fortran 95 (gfortran)编译器也遵循该指南(仅限于Fortran 77特性)。在撰写本文时,AMD64上已经可用的其他Fortran编译器可能使用不同的约定,因此兼容性不能得到保证。
当此文本使用术语Fortran过程时,该文本适用于Fortran FUNCTION和子例程子程序以及备用入口点,除非另有特别说明。
在这个ABI中没有显式定义的所有内容都留给实现。
9.2.1 名称
Fortran中的外部名称是在链接时对所有子程序可见的实体的名称。这包括COMMON块和Fortran过程的名称。为了避免与链接的库的名称空间冲突,所有外部名称都必须被打乱。为了避免混乱的外部名称与本地名称的名称空间冲突,所有本地名称也必须是支离破碎。mangling方案简单如下:
所有没有下划线的名称都应该加上一个下划线
所有包含一个或多个下划线的外部名称(无论在哪里)都应该有两个下划线
所有外部名称都应该映射为小写,遵循Fortran编译器的传统UNIX模型
历史起见,这是为了与f2c兼容。
示例见图9.1:

主程序单元的入口点称为MAIN__。空白公共块的符号名称是__BLNK__。未命名的BLOCK DATA例程的外部名称是__BLOCK_DATA__。
9.2.2 Fortran类型的表示
由于历史原因,GNU Fortran 77将Fortran程序映射到C ABI,因此数据表示可以通过提供Fortran类型到由G77在AMD643上使用的C类型的映射来得到最好的解释,如图9.2所示。“TYPE*N”表示法指定TYPE类型的变量或聚合成员应占用N字节的存储空间。

逻辑类型的值是. true、. false实现为1和0。
G77提供了一个头g2c.h,其中包含了所有支持的Fortran标量类型的等效C类型定义。
CHARACTER类型为4的数据对象表示为C字符类型的字符数组(不保证以“\0”结尾),并使用单独的长度计数器来区分具有长度参数的CHARACTER数据对象和具有长度参数的CHARACTER数据对象的聚合类型。
其他聚合类型的布局是实现定义的。GNU Fortran将连续内存中的所有数组按列主序排列。GNU Fortran 95为派生类型构建了一个等价的C结构,而无需对类型字段进行重新排序。其他编译器可以根据需要使用其他表示形式。Fortran 90/95数组描述符的表示和使用是由实现定义的。注意,数组索引默认从1开始。
Fortran 90/95允许使用类型的kind类型参数对每种基本类型进行不同的类型。Kind类型参数值是实现定义的。
常用的Cray指针的布局是实现定义的。
9.2.3 参数传递
对于每个给定的Fortran 77程序,都可以推导出一个等价的C语言原型。一旦知道了这个等价的C原型,就应该应用C ABI约定来确定如何将参数传递给Fortran过程。
G77通过引用传递过程的所有(用户定义的)形式参数。具体地说,指向变量、数组、数组元素、保存表达式求值结果的临时位置或保存常量值的临时或永久位置(xf g77 manual)的内存位置的指针作为实际参数传递。人工编译器生成的参数可以通过值或引用传递,因为它们本身是编译器的,因此是特定于实现的。
具有CHARACTER类型的数据对象作为指向字符串及其长度的指针传递,因此Fortran过程中的每个CHARACTER形式参数会在等效的C原型中产生两个实际参数。第一个参数在Fortran过程的形式参数列表中占据位置。该参数是一个指针,指向由调用方传递的字符串组成的字符数组。第二个参数被追加到用户指定的正式参数列表的末尾。此参数为默认整数类型,其值为字符数组的长度,即作为第一个参数传递的长度。这个长度是通过值传递的。当参数列表中出现多个CHARACTER参数时,长度参数将按照原始参数出现的顺序追加。上面的讨论也适用于子字符串。
这个ABI没有定义可选参数的传递。它们只在Fortran 90/95中被允许,它们的传递是由实现定义的。
这包括子字符串。
这个ABI没有定义数组函数(返回数组的函数)。它们只在Fortran 90/95中被允许,并且需要定义数组描述符。
注意,如果要将Fortran 90/95过程参数与用Fortran 77编写的代码链接起来,那么带有INTENT(IN)属性的过程参数也应该通过引用传递。Fortran 77不支持也不能支持INTENT属性,因为它没有显式接口的概念。因此,不能将被调用方的参数声明为INTENT(IN)。Fortran 77编译器必须假设所有过程参数都是Fortran 90/95意义上的INTENT(INOUT)。
9.2.4 函数
语句函数的调用是在实现中定义的(因为它们只在本地定义,所以编译器可以自由地应用它喜欢的任何调用约定)。
具有交替返回值的子程序(例如:“子例程X(,)”被称为“CALL X(*10,*20)”)被实现为返回默认类型INTEGER的函数。返回的整数的值是子例程5的“RETURN”语句中指定的整数,或者是不带参数的RETURN语句中指定的0。由调用者决定是否跳转到相应的替代返回标签。调用序列中省略了实际的交替返回参数。
例如:

此整数指示子例程的替代返回在正式参数列表中的位置
这里子例程ALTERNATE_RETURN_EXAMPLE被实现为一个函数,返回一个INTEGER*4,如果N是0值,1如果N是1,2如果N是2和3的所有N的其他值。这个返回值被调用者使用,就好像实际的调用被这个序列代替了:
INTEGER X
X = CALL ALTERNATE_RETURN_EXAMPLE (N)
GOTO (10, 20, 30), X
总之,在调用之后,返回到标签的索引(从1开始)将包含在%rax中。
子例程或FUNCTION的备选入口点应被视为独立的子程序,这是Fortran标准所规定的。也就是说,传递给替代条目的参数应该被当作替代条目是一个单独的子例程或函数来传递。如果一个FUNCTION有可选入口点,则必须返回每个可选入口点的结果,就好像可选入口是一个结果类型为可选入口的单独FUNCTION。备用入口点的外部命名见9.2.1节。
9.2.5 公用块
在没有任何涉及公共块中的变量的等效声明的情况下,公共块的布局与等效C结构的布局完全相同(变量的类型根据9.2.2节替换),包括对齐要求。
这个ABI只在某些情况下定义了存在EQUIVALENCE语句的布局:
如果忽略了等效性,COMMON块的布局一定不能改变,等效性指的是:
如果两个数组是等价的,较大的数组必须在COMMON块中命名,并且必须完全包含,特别是另一个数组不能扩展等价段的大小。它也可能不会改变对齐要求。
如果数组元素和标量等价,则数组必须在COMMON块中命名,且数组不能小于标量。标量的类型不能要求比数组更大的对齐方式。
如果两个标量相等,则它们必须具有相同的大小和对齐要求。
其他情况是实现定义的。
因为Fortran标准允许空白的COMMON块在不同的子程序中有不同的大小,所以可能无法确定它是否小到可以放入.bss部分。因此,在编译中型或大型代码模型时,空白的COMMON块应该始终放在.lbss部分中。
9.2.6 Intrinsics
本节列出了符合标准的编译器至少必须支持的一组intrinsic。它们因起源而分开。它们遵循常规的调用和命名约定。
intrinsic的签名使用语法return - type(argtype1, argtype2,…),其中各个类型可以是以下字符:V(在void中)指定子例程,L指定LOGICAL, I指定INTEGER, R指定REAL, C指定CHARACTER。因此,I(R,L)指定了一个函数,返回一个INTEGER,接受一个REAL和一个LOGICAL。如果参数是一个数组,则使用一个尾随数字来表示,例如I13是一个包含13个元素的INTEGER数组。如果CHARACTER参数或返回值具有固定长度,则使用星号和尾随数字表示,例如C16是CHARACTER(len=16)。如果必须传递任意长度的CHARACTER参数,则末尾的数字将被替换为N,例如CN。


有关表9.2中列出的F77 intrinsic的签名和定义,请参阅Fortran 77语言标准。根据标准,这些intrinsic可以有一个前缀,因此这个表不是详尽的。

有关表9.3中列出的F90 intrinsic的签名和定义,请参阅Fortran 90语言标准。


10 ILP32编程模型
“x32”常用来指AMD64 ILP32编程模型。
10.1 参数传递
当一个指针类型的值在寄存器中返回或传递时,32到63位应为0。
10.2 地址空间
ILP32二进制位于64位虚拟地址空间的低32位,所有地址的大小都是32位。它们应符合3.5.1节中描述的小代码模型或小位置独立代码模型(PIC)。
10.3 线程本地存储支持
ILP32 TLS (Thread-Local Storage)支持是在LP64 TLS实现的基础上做了一些修改。
10.3.1 全局线程局部变量
对于全局线程局部变量x:
extern __thread int x;
通用动态模型加载地址x到%rax

在TLSDESC码序列中,即使目的寄存器不需要合法指令,也必须使用前缀rex进行编码。如果leal编码的长度是可变的,链接器就不能知道它从哪里开始,也不能安全地执行GDesc -> IE/LE优化。

初始Exec模型加载x到%rax的地址。指令addl必须用rex前缀编码,即使目标寄存器不需要它。否则链接器无法安全地执行IE -> LE优化。

初始Exec模型,II装载x到%edi的值。%fs:(%eax)内存操作数不能用于ILP32,因为它的有效地址是%fs的基址+ %eax 0扩展到64位结果的值,这是错误的,在%eax中为负值。

目录预览
边栏推荐
- 图解B+树的插入过程
- Wechat applet decryption and unpacking to obtain source code tutorial
- Digital warehouse: on the construction practice of digital warehouse in banking industry
- Binary logs in MySQL
- scipy.sparse.vstack
- 商业智能BI全解析,探寻BI本质与发展趋势
- National standard gb28181 protocol video platform easygbs message pop-up mode optimization
- C unit test
- 1. Mx6ul core module uses serial EMMC read / write test (IV)
- 租户问题。
猜你喜欢

(Dynamic Programming Series) sword finger offer 48. the longest substring without repeated characters

图解B+树的插入过程

简单使用 MySQL 索引

Games101 review: rasterization

力扣148:排序链表

prometheus+process-exporter+grafana 监控进程的资源使用

1. Mx6ul core module uses serial NAND FLASH read / write test (III)

Wechat applet decryption and unpacking to obtain source code tutorial

Activiti workflow gateway
![[early knowledge of activities] list of recent activities of livevideostack](/img/14/d2cdae45a18a5bba7ee1ffab903af2.jpg)
[early knowledge of activities] list of recent activities of livevideostack
随机推荐
A pluggable am335x industrial control module onboard WiFi module
关于mysql的问题,希望个位能帮一下忙
Manifold learning
数仓:银行业数仓的分层架构实践
GAMES101复习:着色(Shading)、渲染管线
Audio and video technology development weekly | 254
Ggplot2 learning summary
[pyqt5 packaged as exe]
GAMES101复习:光栅化
数仓:浅谈银行业的数仓构建实践
U++ common type conversion and common forms and proxies of lambda
prometheus+blackbox-exporter+grafana 监控服务器端口及url地址
Li Kou daily question - day 39 -67. Binary sum
1. Mx6ul core module serial WiFi test (VIII)
Adruino basic experimental learning (I)
Bo Yun container cloud and Devops platform won the trusted cloud "technology best practice Award"
17. Reverse the linked list
Activiti workflow gateway
BigDecimal use
MySQL(4)