当前位置:网站首页>[Bert] QA, reading comprehension, information retrieval
[Bert] QA, reading comprehension, information retrieval
2022-07-25 00:15:00 【Zunxinbiwei】
List of articles
brief introduction :
- BERT stay QA And the progress and practice of reading comprehension
- BERT In search and information retrieval (IR) Progress and practice
One 、BERT be applied to QA And reading comprehension
QA The core issue is : Natural language query questions for a given user Q, For example, ask “ Who is the most unreliable president in American history ?”, I hope the system can find a language fragment from a large number of candidate documents , This language segment can correctly answer the questions raised by users , It is better to be able to answer directly A Return to the user , For example, the correct answer to the above question :“ trump ”.
QA+ Reading comprehension can better optimize search engines , Machines learn to read and understand , Understand each article , And then for the user's questions , Go straight back to the answer .
1. QA General process of application
(1) utilize BM25 And other classic text matching models or other simple and fast models to sort documents preliminarily , Get the top score Top K file , Then use a complex machine learning model to Top K Return the results to reorder .
(2) take Query and Document Input BERT, utilize BERT Deep language processing ability , Make a judgment on whether the two are related .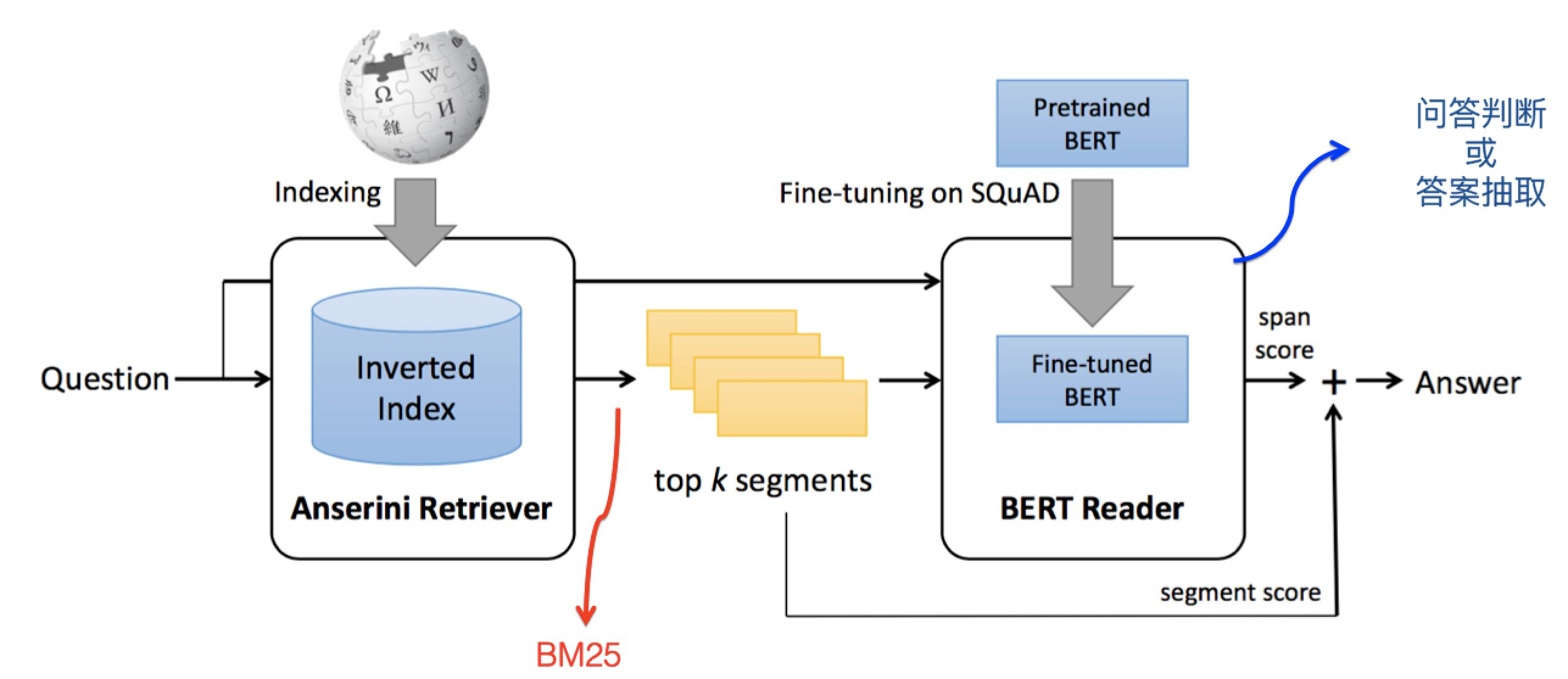
2. Read and understand the general process of application
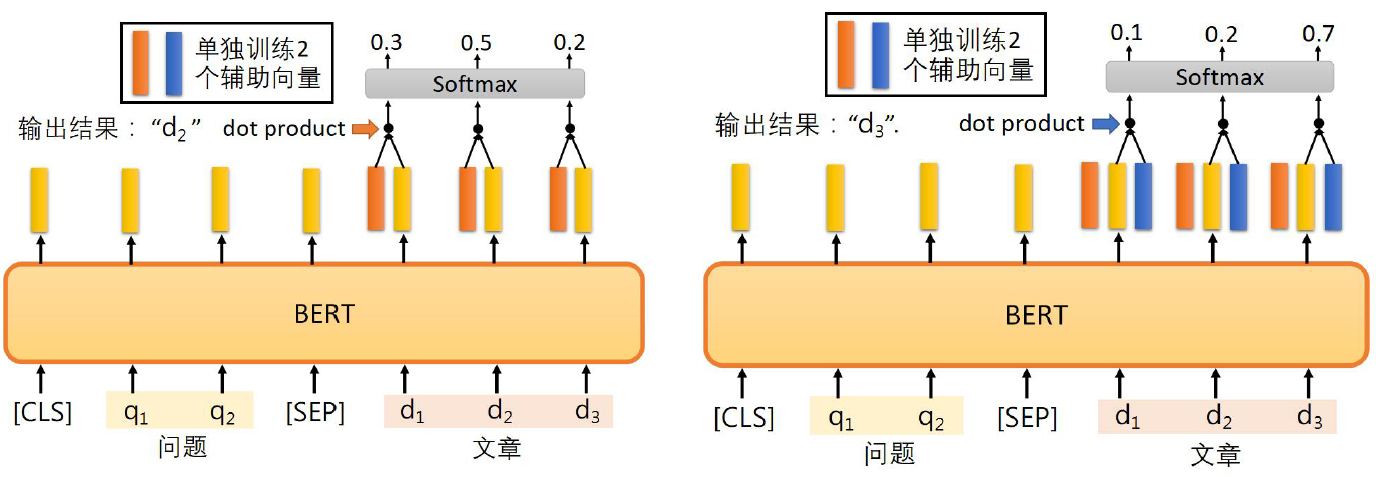
Removed QA The first stage of , Output start position index And termination location index.
3. BERT stay QA And the effect of reading comprehension
QA And reading comprehension , In the application BERT when , Basically similar tasks to some extent , If the understanding is simplified , You can put the above QA Throw away the first stage of the process , Keep only the second stage , That is, reading comprehension task application BERT The process of .
Of course , The above is a simplified understanding , As far as the task itself is concerned , In fact, the two have a lot in common , But there are also some subtle differences :
(1) It's normal QA When looking for the answer to the question , Rely on the The context is shorter , Reference information More local some , answer More superficial some ;
(2) Reading comprehension task , Position the answer correctly , The reference The context may be longer , Some difficult reading comprehension problems may require machines An appropriate degree of reasoning . The overall feeling is that reading comprehension seems normal QA The difficulty of the task increases, and the version task .
In the application BERT After the pre training model , Often the task has been greatly improved , Here are two examples .
3.1 QA Mission
Paper: End-to-End Open-Domain Question Answering with BERTserini
Pattern : retrieval (BM25)+ Answer judgement (SQuAD Data sets fine-tuning BERT)
The effect is improved : Compared with the previous SOTA Method , Promoted 30% above
3.2 Reading comprehension task
Paper: A BERT Baseline for the Natural Questions
Pattern : Single stage , Reading comprehension task , The task is more difficult than SQuAD
The effect is improved : Compared with the previous SOTA Method , Short answer Type promotion 50% above , Long answer Type promotion 30% above
Two 、BERT Applied to information retrieval (IR)
application BERT,IR Problem model and solution process and QA The task is very similar , But because of different tasks , So there are still some differences , There are three main points :
(1) Two text “ The correlation ” and “ Semantic similarity ” The connotation of representation is different ;“ The correlation ” More emphasis on the precise matching of literal content , and “ Semantic similarity ” It covers another meaning : Despite the literal mismatch , But deep semantic similarity .QA Tasks are important for both , Maybe more semantic similarity , And general IR The task focuses more on the relevance of text matching .
(2) QA The answer to the task is likely to be just a short language segment , namely QA The processing object of the task tends to be short text ; And yes IR In terms of tasks ( For example, we search a scanned book ), Documents are generally long , Key fragments may be scattered in Different parts of the document . because BERT The longest input is allowed 512 A unit of , So how to deal with long documents , about IR It's more important for ;
(3) about QA In terms of tasks , Maybe the information contained in the text is enough to make a judgment , So no additional feature information is needed ; And for IR Mission , Just text You may not be able to effectively judge the relevance of queries and documents , Many other factors also seriously affect IR quality , such as Link analysis , User behavior data etc. . For non text information ,BERT These information cannot be well integrated and reflected .
1. BERT Effect in short document retrieval
Paper: PASSAGE RE-RANKING WITH BERT
The effect is improved : Compared with the previous SOTA Method , Promoted 27%
Paper: Investigating the Successes and Failures of BERT for Passage Re-Ranking
The effect is improved : be relative to BM25, Promoted 20% above ( In a short document )
For short document retrieval , Use BERT after , Generally, the performance is greatly improved .
2. BERT Exploration in long document retrieval
For long document retrieval tasks , because BERT Too long input cannot be accepted at the input , There is a problem of how to shorten long documents .
Other processes are basically the same as short document retrieval .
How to solve the problem of long documents in search ? You can refer to the ideas of the following papers .
2.1 Some ideas in the paper
Paper: Simple Applications of BERT for Ad Hoc Document Retrieval
The author used... In the field of information retrieval for the first time BERT
The main research content is :
(1) First, it is proved that for BERT Come on , Short document retrieval and QA The problem is essentially the same task , The training model is better than the previous SOTA The model has been upgraded 20% about .
(2) Used TREC 2004 Robust Data sets ( contain 250 Newsline corpus topics , The largest Newsline corpus ) Research long document retrieval .
(3) The idea of long document retrieval :( Not the author slapping his head , See the following figure for the source of ideas )
Infer each sentence in the candidate document , Choose the top one with high score k A sentence ;
Score it against the original document ( Such as BM25 score ) Combine with linear interpolation .
I understand it is actually a kind of Extract the topic of the article Thought 
The top n Sentence score :
S c o r e d = a ⋅ S d o c + ( 1 − a ) ⋅ ∑ i = 1 n w i ⋅ S i Score_d=a·S_{doc}+(1-a)·\sum^n_{i=1}w_i·S_i Scored=a⋅Sdoc+(1−a)⋅i=1∑nwi⋅Si
S d o c S_{doc} Sdoc: Score of original document , S i S_i Si:BERT Before you get it i i i Sentences with scores , a a a and w i w_i wi: Hyperparameters , Tuning through cross validation .
(4) By the above methods , take Long document retrieval is converted to short document retrieval , According to another 、2. The method mentioned above .
2.2 Questions and ideas
The problem is coming. , how fine-tune?
- Lack of sentences Similarity judgment
- Evaded the question , Use the existing sentence data set to fine tune , Improved effect 10% about
Further reflection :
The fine-tuning data in the paper uses external data , The fine-tuning model does not fit the current data well . Whether it can be or not? Sample positive and negative samples from the segmented short sentences , Such fine-tuning data is also derived from long text , Can the effect of the model be improved ?
边栏推荐
- 做一个文艺的测试/开发程序员,慢慢改变自己......
- Transmission download list, download file migration machine guide
- Quartus:17.1版本的Quartus安装Cyclone 10 LP器件库
- R language plot visualization: plot to visualize the residual analysis diagram of the regression model, the scatter diagram of the predicted value and residual corresponding to the training set and th
- [mindspore] [mode] spontaneous_ The difference between mode and graph mode
- Restructuredtext grammar summary for beginners
- LP liquidity pledge mining system development detailed procedure
- [hero planet July training leetcode problem solving daily] 24th line segment tree
- codeforces round #797 ABCDEFG
- 在混合云中管理数据库:八个关键注意事项
猜你喜欢

Redis6.2 SYSTEMd startup prompt redis service: Failed with result ‘protocol‘.
你还在使用System.currentTimeMillis()?来看看StopWatch吧
![[leetcode weekly replay] game 83 biweekly 20220723](/img/db/c264c94ca3307d4363d3cf7f5d770b.png)
[leetcode weekly replay] game 83 biweekly 20220723

What can testers do when there is an online bug?

Soft test --- fundamentals of programming language (Part 2)
![[mindspore ascend] [running error] graph_ In mode, run the network to report an error](/img/81/9e96182be149aef221bccb63e1ce96.jpg)
[mindspore ascend] [running error] graph_ In mode, run the network to report an error

The new version of Alibaba Seata finally solves the idempotence, suspension and empty rollback problems of TCC mode

如果实现与在线CAD图中的线段实时求交点

Quartus:17.1版本的Quartus安装Cyclone 10 LP器件库

Simple operation K6
随机推荐
SQL rewriting Series 6: predicate derivation
Restructuredtext grammar summary for beginners
[leetcode weekly replay] 303rd weekly 20220724
Two numbers that appear only once in the array
Dynamic programming-01 knapsack rolling array optimization
Wine wechat initialization 96% stuck
c语言:深度刨析函数栈帧
Oracle is not null cannot filter null values
Be an artistic test / development programmer and slowly change yourself
Tencent low code platform is officially open source! You can drag and drop and generate mobile phone projects and PC projects! Get private benefits
Paper time review MB2: build a behavior model for autonomous databases
云计算三类巨头:IaaS、PaaS、SaaS,分别是什么意思,应用场景是什么?
Shell echo command
技术操作
LP liquidity pledge mining system development detailed procedure
Deep and direct visual slam
Nodejs package
Pointers and arrays
EF core: self referencing organizational structure tree
Log4j configuration file