当前位置:网站首页>16.过拟合欠拟合
16.过拟合欠拟合
2022-07-27 05:13:00 【派大星的最爱海绵宝宝】
目录
过拟合和欠拟合
我们不知道模型函数,有时候观察也会有误差,,把所有误差合并到一个因子上,y = w * x + b + ε,~N(0.01,1)
一.衡量不同类型的模型
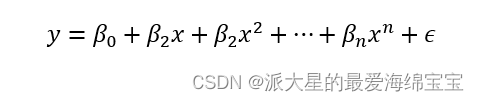
对于常数多项式、一次方多项式,和n次方多项式,增加到n次方时,表达的分布情况更加复杂,对一种很复杂抽象的映射可以学习到,即表达能力(model capacity)变强了
二.under-fitting欠拟合
情况1:estimated<Ground-truth
under-fitting,我们用的模型的复杂度会小于真实数据的复杂度,会使模型的表达能力不够。
train accuracy和loss令人不满意,理想的acc和loss如图所示,过拟合后,可能acc不再上升,loss也会下不去。
test accuracy也会不满意。
三.over-fitting过拟合
情况2:estimated>Ground-truth
over-fitting:我们用的模型的复杂度会大于真实数据的复杂度,会尝试降低每个点的loss,我们的模型会更接近每一个点。换成另一个词是generalization performance泛化能力。
现实生活中,更多的是over-fitting,
会使train情况特别好,当test与train不同时,会造成test的accuracy特别低。
四.怎么检测over-fitting
train-test
把一个dataset划分成train set和test set。在test上也做一个acc和loss的检测,如果train上很好test上很差,则是过拟合现象。
做测试的目的是看有没有过拟合,我要选取在过拟合之前的最好的模型的参数,test是防止过拟合的。
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
这里的train是全部数据集,我们这里的test不是真正的test,而validation set,都是用来挑选模型参数。如果三者同时出现,有不同的功能。
data和target是用来做backward的,每个epoch都会test一次,test的目的是提前知道是否已经overfitting了,如果已经overfitting,会选取最好的一次状态,一般会选取test accuracy最高的点作为最终的状态。
参数train的值是ture的话意思是训练集,false的话是测试集。
train-val-test
固定划分
train_db是60k,把train_db从前到后划分成50k和10k,得到三个set
print('train:',len(train_db),'test:',len(test_db))
train_db,val_db=torch.utils.data.random_split(train_db,[50000,10000])
print('db1:',len(train_db),'db2:',len(val_db))
train_loader=torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,
shuffle=True
)
val_loader=torch.utils.data.DataLoader(
val_db,
batch_size=batch_size,
shuffle=True
)

k-fold cross validation
把60k划分成n份,每次取(n-1)/n来做train,取剩下的1/n做validation set。
validation set用来挑选模型参数,test set的performance仅仅用来评价。总共60k,50k是train set,10k是validation set,第二个epoch再随机切割一下,随即挑选50k是train set,10k是validation set。这样做的好处就是每个数据集都有可能参与到backbroke中,每个数据都有能可能是validation set或train set,防止模型记忆。
通过validation set找到最好的参数,把这个参数带入到test set中。两者的区别是数据集不同。
五.怎么减少over-fitting
1.more data增加更多的数据
代价最大
2.constraint model complexity降低模型复杂度
shallow
选用不深,表达能力不强的模型
regularization
使权重很小接近于0,但不等于0。给定的网络结构,你不知道模型的复杂度,也不知道数据集的大小,此时会优先选择表达能力较大的模型,
中括号[ ]内的式子,使得预测值pred和真实值y更加的接近。θ是网络参数,例如w1,b1等,使得θ的泛数更接近于0,可较少模型的复杂度 。λ是超参数,需要人为调整,功能类似于learning-rate。
L2-regularization:
device=torch.device('cuda:0')
net=MLP().to(device)
optimizer=optim.SGD(net.parameters(),lr=learning_rate,weight_decay=0.01)
criteon=nn.CrossEntropyLoss().to(device)
L1-regularization:
需要人为去完成。
regularization_loss=0
for param in model.parames():
regularization_loss+=torch.sum(torch,abs(param))
classify_loss=criton(lohits,target)
loss=classify_loss+0.01*regularization_loss
optimizer.zero_gard()
loss.backward()
optimizer.step()
对网络所有参数进行迭代,0.01是λ。最后的loss输出。
3.dropout
迫使有效的w越小越好,在前向传播过程中,有一定的概率断掉其中一条路,假如有10k的连接,可能每次只使用了5k,下次7k,每一次train使用到的参数量会减小。
在任何需要加dropout的层数之间加上dropout。
net_dropped=nn.Sequential(
torch.nn.Linear(784, 200),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(200, 200),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch. nn.Linear(200, 10),
)
两个200层全连接层之间是dropout,断掉50%。
在pytorch和tf中的区别
torch.nn.Dropout(p=dropout_prob)
p=1,意味着线都有可能断掉,p=0.1,意味着线断掉的概率比较小
tf.nn.dropout(keep_prob)
p=1,意味着所有的连接保持住,p=0.1,意味着断掉的概率为0.99
train和test中
在test时没有dropout这个行为,所有的连接都会使用,在validation中需要人为的把dropout取消掉,否则performance会小。
4.data argumention做数据增强
5.early stopping
使用validati set做一个提前的终结。
training set accuracy会一直上升,test set accuracy会在达到临界点后下降,通过validati set获得最好的参数,在这个临界点的地方直接停止不再继续,此时可以看作一个early stopping。
根据本人的经验值和模型的预估值判断
步骤:
通过validati set选择参数
监控validati的性能performance
在val performance的最高点停止
边栏推荐
- Sequel Pro下载及使用方法
- 解决MySQL JDBC数据批量插入慢的问题
- vscode打造golang开发环境以及golang的debug单元测试
- Face brushing payment will never be out of date, but will continue to change
- 常用adb命令汇总 性能优化
- golang怎么给空结构体赋值
- Day 17.The role of news sentiment in oil futures returns and volatility forecasting
- 2020年PHP中级面试知识点及答案
- Which futures company do you go to and how do you open an account?
- GBASE 8C——SQL参考6 sql语法(6)
猜你喜欢

The LAF protocol elephant of defi 2.0 may be one of the few profit-making means in your bear market

How to choose a good futures company for futures account opening?

GBase 8c产品简介

个人收款码不得用于经营收款

建设创客教育运动中的完整体系

DDD领域驱动设计笔记

【好文种草】根域名的知识 - 阮一峰的网络日志

【MVC架构】MVC模型

Day 9. Graduate survey: A love–hurt relationship

Sealem Finance - a new decentralized financial platform based on Web3
随机推荐
记一次PG主从搭建及数据同步性能测试流程
You can't even do a simple function test well. What do you take to talk about salary increase with me?
Minio8.x version setting policy bucket policy
定点一键查询GUI编程的设计与开发
vscode打造golang开发环境以及golang的debug单元测试
GBASE 8C——SQL参考4 字符集支持
dpdk 网络协议栈 vpp OvS DDos SDN NFV 虚拟化 高性能专家之路
2021中大厂php+go面试题(2)
使用Docker部署Redis进行高可用主从复制
GBASE 8C——SQL参考6 sql语法(9)
Characteristics of hexadecimal
Amazon evaluation autotrophic number, how to carry out systematic learning?
Jenkins build image automatic deployment
Do you really know session and cookies?
Seven enabling schemes of m-dao help Dao ecology move towards mode and standardization
RK3288板卡HDMI显示uboot和kernel的logo图片
Seektiger's okaleido has a big move. Will the STI of ecological pass break out?
Move protocol launched a beta version, and you can "0" participate in p2e
In the future, face brushing payment can occupy a lot of market share
Minimum handling charges and margins for futures companies