当前位置:网站首页>一文彻底搞懂My SQL索引知识点
一文彻底搞懂My SQL索引知识点
2022-06-22 08:20:00 【念去去千里烟波】
本文转载自:一文搞懂MySQL索引所有知识点(建议收藏)_敖丙-CSDN博客_mysql索引知识点
修改了部分错别字。保留了图片水印。
索引介绍
索引是什么
- 官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
- 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
- 我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。
索引的优势和劣势
优势:
可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
- 被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些。
- 如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多。
劣势:
- 索引会占据磁盘空间
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
索引类型
主键索引
索引列中的值必须是唯一的,不允许有空值。
普通索引
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
唯一索引
索引列中的值必须是唯一的,但是允许为空值。
全文索引
只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。字段长度比较大时,如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。 MyISAM和InnoDB中都可以使用全文索引。
空间索引
MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。MySQL在空间索引这方面遵循OpenGIS几何数据模型规则。
前缀索引
在文本类型如CHAR,VARCHAR,TEXT类列上创建索引时,可以指定索引列的长度,但是数值类型不能指定。
其他(按照索引列数量分类)
单列索引
组合索引
组合索引的使用,需要遵循最左前缀匹配原则(最左匹配原则)。一般情况下在条件允许的情况下使用组合索引替代多个单列索引使用。
索引的数据结构
Hash表
Hash表,在Java中的HashMap,TreeMap就是Hash表结构,以键值对的方式存储数据。我们使用 Hash表存储表数据Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等值查询时效率很高,时间复杂度为O(1);但是不支持范围快速查找,范围查找时还是只能通过扫描全表方式。
显然这种并不适合作为经常需要查找和范围查找的数据库索引使用。
二叉查找树
二叉树,我想大家都会在心里有个图。

二叉树特点:每个节点最多有2个分叉,左子树和右子树数据顺序左小右大。
这个特点就是为了保证每次查找都可以这折半而减少IO次数,但是二叉树就很考验第一个根节点的取值,因为很容易在这个特点下出现我们并发想发生的情况“树不分叉了”,这就很难受很不稳定。

显然这种情况不稳定的我们再选择设计上必然会避免这种情况的
平衡二叉树
平衡二叉树是采用二分法思维,平衡二叉查找树除了具备二叉树的特点,最主要的特征是树的左右两个子树的层级最多相差1。在插入删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很高、右子树很矮的情况。
使用平衡二叉查找树查询的性能接近于二分查找法,时间复杂度是 O(log2n)。查询id=6,只需要两次IO。
就这个特点来看,可能各位会觉得这就很好,可以达到二叉树的理想的情况了。然而依然存在一些问题:
- 时间复杂度和树高相关。树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。磁盘每次寻道时间为10ms,在表数据量大时,查询性能就会很差。(1百万的数据量,log2n约等于20次磁盘IO,时间20*10=0.2s)
- 平衡二叉树不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率不高。
B树:改造二叉树
MySQL的数据是存储在磁盘文件中的,查询处理数据时,需要先把磁盘中的数据加载到内存中,磁盘IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作。访问二叉树的每个节点就会发生一次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度。那如何降低树的高度呢?
假如key为bigint=8字节,每个节点有两个指针,每个指针为4个字节,一个节点占用的空间16个字节(8+4*2=16)。
因为在MySQL的InnoDB存储引擎一次IO会读取的一页(默认一页16K)的数据量,而二叉树一次IO有效数据量只有16字节,空间利用率极低。为了最大化利用一次IO空间,一个简单的想法是在每个节点存储多个元素,在每个节点尽可能多的存储数据。每个节点可以存储1000个索引(16k/16=1000),这样就将二叉树改造成了多叉树,通过增加树的叉树,将树从高瘦变为矮胖。构建1百万条数据,树的高度只需要2层就可以(1000*1000=1百万),也就是说只需要2次磁盘IO就可以查询到数据。磁盘IO次数变少了,查询数据的效率也就提高了。
这种数据结构我们称为B树,B树是一种多叉平衡查找树,如下图主要特点:
- B树的节点中存储着多个元素,每个内节点有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值从大到小排列。也就是说,在所有的节点都储存数据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。
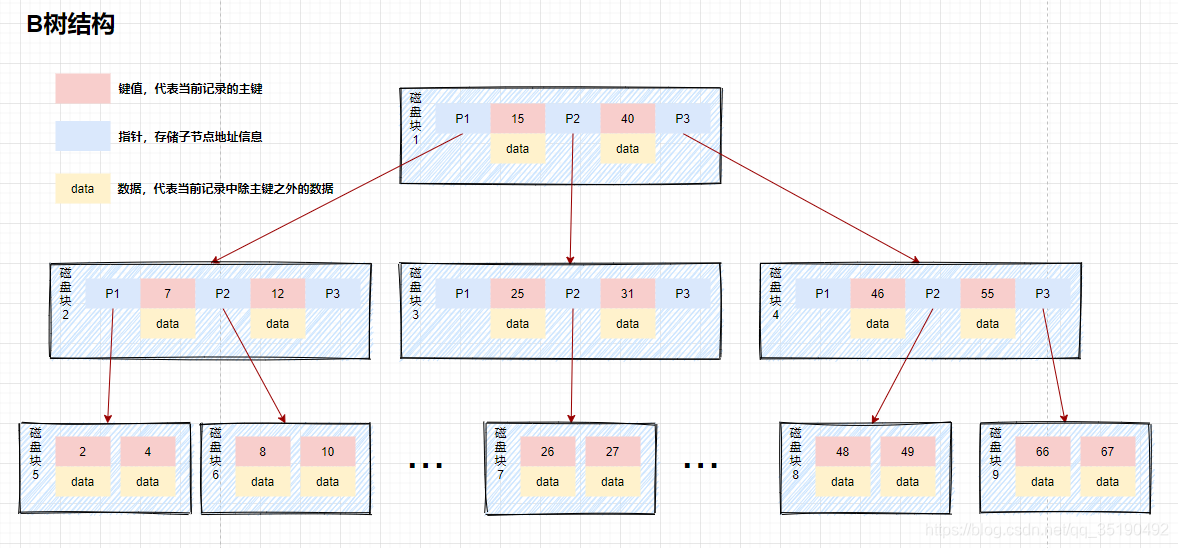
举个例子,在b树中查询数据的情况:
假如我们查询值等于10的数据。查询路径磁盘块1->磁盘块2->磁盘块5。
第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左路,到磁盘寻址磁盘块2。
第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<10,到磁盘中寻址定位到磁盘块5。
第三次磁盘IO:将磁盘块5加载到内存中,在内存中从头遍历比较,10=10,找到10,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。
相比二叉平衡查找树,在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少。同时,由于我们的比较是在内存中进行的,比较的耗时可以忽略不计。B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
过程如图:

看到这里一定觉得B树就很理想了,但是前辈们会告诉你依然存在可以优化的地方:
- B树不支持范围查询的快速查找,你想想这么一个情况如果我们想要查找10和35之间的数据,查找到15之后,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
- 如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。
B+树:改造B树
B+树,作为B树的升级版,在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题
- B树:非叶子节点和叶子节点都会存储数据。
- B+树:只有叶子节点才会存储数据,非叶子节点至存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。

B+树的最底层叶子节点包含了所有的索引项。从图上可以看到,B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,所以放索引的磁盘块所存放的索引数量是会跟这增加的,所以相对于B树来说,B+树的树高理论上情况下是比B树要矮的。也存在索引覆盖查询的情况,在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。
举个例子:
- 等值查询:
假如我们查询值等于9的数据。查询路径磁盘块1->磁盘块2->磁盘块6。
- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,9<15,走左路,到磁盘寻址磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<9<12,到磁盘中寻址定位到磁盘块6。
- 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,在第三个索引中找到9,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。(这里需要区分的是在InnoDB中Data存储的为行数据,而MyIsam中存储的是磁盘地址。)
过程如图:

- 范围查询:
假如我们想要查找9和26之间的数据。查找路径是磁盘块1->磁盘块2->磁盘块6->磁盘块7。
- 首先查找值等于9的数据,将值等于9的数据缓存到结果集。这一步和前面等值查询流程一样,发生了三次磁盘IO。
- 查找到15之后,底层的叶子节点是一个有序列表,我们从磁盘块6,键值9开始向后遍历筛选所有符合筛选条件的数据。
- 第四次磁盘IO:根据磁盘6后继指针到磁盘中寻址定位到磁盘块7,将磁盘7加载到内存中,在内存中从头遍历比较,9<25<26,9<26<=26,将data缓存到结果集。
- 主键具备唯一性(后面不会有<=26的数据),不需再向后查找,查询终止。将结果集返回给用户。

可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
Mysql的索引实现
介绍完了索引数据结构,那肯定是要带入到Mysql里面看看真实的使用场景的,所以这里分析Mysql的两种存储引擎的索引实现:MyISAM索引和InnoDB索引
MyIsam索引
以一个简单的user表为例。user表存在两个索引,id列为主键索引,age列为普通索引
CREATE TABLE `user`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;

MyISAM的数据文件和索引文件是分开存储的。MyISAM使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。
主键索引
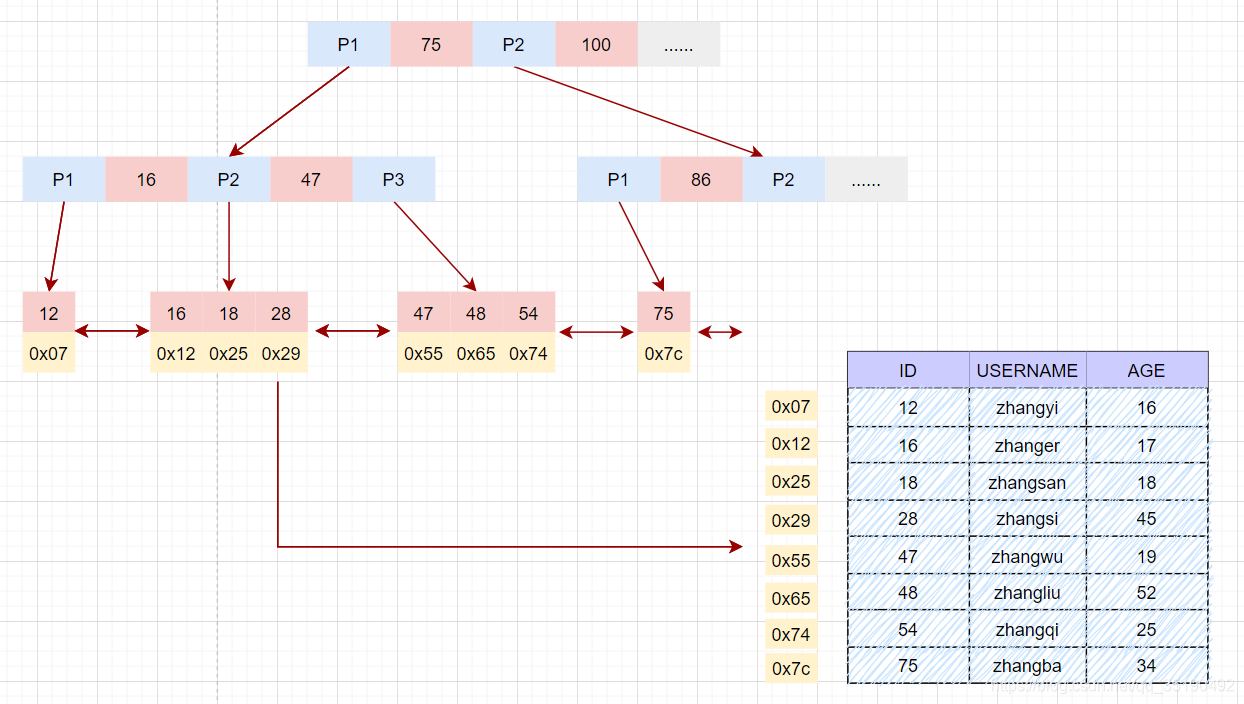
表user的索引存储在索引文件user.MYI中,数据文件存储在数据文件 user.MYD中。
简单分析下查询时的磁盘IO情况:
根据主键等值查询数据:
select * from user where id = 28;
- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于30的索引项。(1次磁盘IO)
- 从索引项中获取磁盘地址,然后到数据文件user.MYD中获取对应整行记录。(1次磁盘IO)
- 将记录返给客户端。
磁盘IO次数:3次索引检索+记录数据检索。

根据主键范围查询数据:
select * from user where id between 28 and 47;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
检索到叶节点,将节点加载到内存中遍历比较16<28,18<28,28=28<47。查找到值等于28的索引项。
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28<47=47,根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。

**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
辅助索引
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
InnoDB索引
主键索引(聚簇索引)
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据都是该行的主键值。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
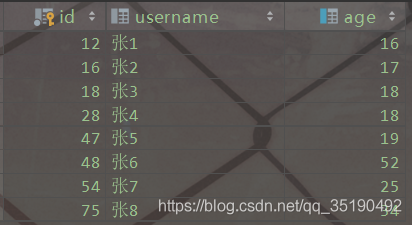
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。

等值查询数据:
select * from user_innodb where id = 28;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)
磁盘IO数量:3次。
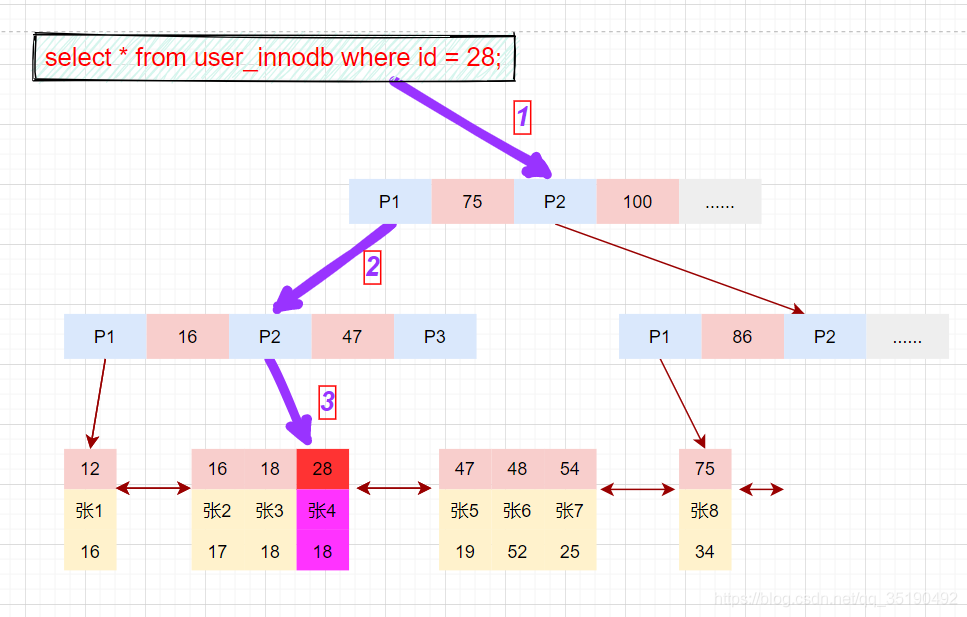
辅助索引
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。

底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select * from t_user_innodb where age=19;

根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
组合索引
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` varchar(10) DEFAULT NULL,
`d` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;

组合索引的数据结构:
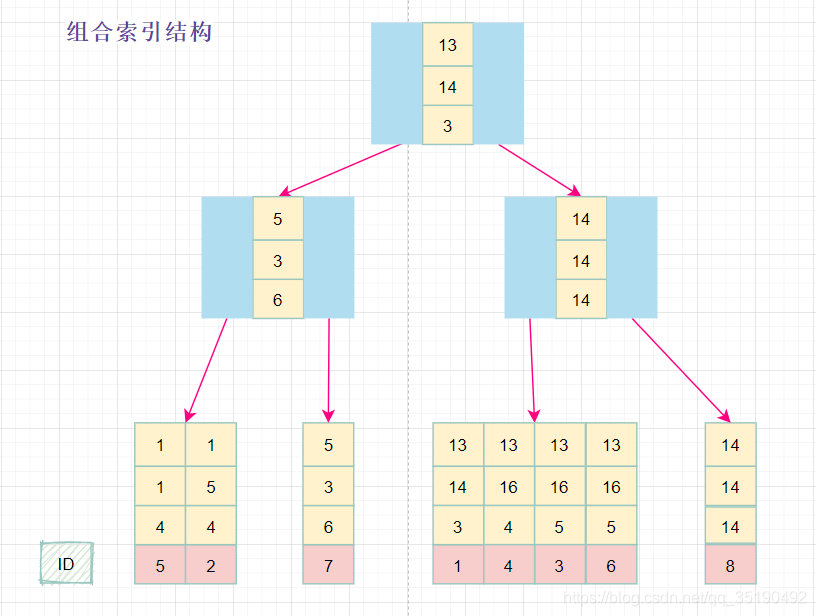
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;

最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配。
覆盖索引
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:

总结
看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如:
避免回表
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们称为回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…)
如果在一个场景下,select id,name,sex from user where name ='zhangsan';这个语句在业务上频繁使用到,而user表的其他字段使用频率远低于它,在这种情况下,如果我们在建立 name 字段的索引的时候,不是使用单一索引,而是使用联合索引(name,sex)这样的话再执行这个查询语句是不是根据辅助索引查询到的结果就可以获取当前语句的完整数据。这样就可以有效地避免了回表再获取sex的数据。
这里就是一个典型的使用覆盖索引的优化策略减少回表的情况。
联合索引的使用
联合索引,在建立索引的时候,尽量在多个单列索引上判断下是否可以使用联合索引。联合索引的使用不仅可以节省空间,还可以更容易的使用到索引覆盖。试想一下,索引的字段越多,是不是更容易满足查询需要返回的数据呢。比如联合索引(a_b_c),是不是等于有了索引:a,a_b,a_b_c三个索引,这样是不是节省了空间,当然节省的空间并不是三倍于(a,a_b,a_b_c)三个索引,因为索引树的数据没变,但是索引data字段的数据确实真实的节省了。
联合索引的创建原则,在创建联合索引的时候因该把频繁使用的列、区分度高的列放在前面,频繁使用代表索引利用率高,区分度高代表筛选粒度大,这些都是在索引创建的需要考虑到的优化场景,也可以在常需要作为查询返回的字段上增加到联合索引中,如果在联合索引上增加一个字段而使用到了覆盖索引,那我建议这种情况下使用联合索引。
联合索引的使用
- 考虑当前是否已经存在多个可以合并的单列索引,如果有,那么将当前多个单列索引创建为一个联合索引。
- 当前索引存在频繁使用作为返回字段的列,这个时候就可以考虑当前列是否可以加入到当前已经存在索引上,使其查询语句可以使用到覆盖索引。
边栏推荐
- 解析认知理论对创客教师实训的作用
- I spring and autumn web Penetration Test Engineer (elementary) learning notes (Chapter 1)
- Mt4/mql4 getting started to be proficient in EA tutorial lesson 7 - common functions of MQL language (VII) - index value taking function
- Seven challenges faced by CIO in 2022 and Solutions
- Mt4/mql4 getting started to mastering EA tutorial lesson 4 - common functions of MQL language (IV) - common functions of K-line value
- steam教育文化传承的必要性
- Enumerations, custom types, and swaggerignore in swagger
- Example of multipoint alarm clock
- swagger中的枚举、自定义类型和swaggerignore
- Calculation days ()
猜你喜欢

Mt4/mql4 getting started to proficient in foreign exchange EA automatic trading tutorial - common functions of MQL language

Website sharing of program ape -- continuous update

Learn data warehouse together - Zero

Five skills to be an outstanding cloud architect

Carry out effective maker education courses and activities

Spark Yarn内存资源计算分析(参考)--Executor Cores、Nums、Memory优化配置

Record once · fluent file buffer

steam教育文化传承的必要性

培养以科学技能为本的Steam教育

Web Knowledge 1 (server +servlet)
随机推荐
Prompt installremove of the Service denied when installing MySQL service
Coding complexity C (n)
Bee read write separation Usage Summary
Multiple ways for idea to package jars
JSON usage example
Powerful database design tool PowerDesigner
Thread status (timed wait, lock blocking, infinite wait (key))
计算天数()
FastCorrect:语音识别快速纠错模型丨RTC Dev Meetup
安装 MySQL 服务时提示 InstallRemove of the Service Denied
Summary of basic knowledge of Oracle database SQL statements I: Data Definition Language (DDL)
How to select the appropriate partition key, routing rule and partition number
steam教育文化传承的必要性
Svn submits subfolder questions
Calculation of water charge
Mysql5.7 master-slave mode reference
Web Knowledge 1 (server +servlet)
Summary of sub database and sub table 2
Example of multipoint alarm clock
I spring and autumn web Penetration Test Engineer (elementary) learning notes (Chapter 3)