当前位置:网站首页>Li Hongyi, machine learning 3. Gradient descent
Li Hongyi, machine learning 3. Gradient descent
2022-07-26 15:05:00 【Hua Weiyun】
One 、 Source of error
error (Error) There are two main sources : deviation (Bias) And variance (Variance).
Error It reflects the accuracy of the whole model ,Bias It reflects the error between the output of the model on the sample and the real value , The accuracy of the model itself ,Variance It reflects the error between each output of the model and the expected output of the model , That is, the stability of the model .
1.1 Under fitting and over fitting

▲ deviation v.s. variance
Simple model ( On the left ) It is the error caused by large deviation , This situation is called under fitting , And complex models ( On the right ) It is the error caused by too large variance , This situation is called over fitting .
- If the deviation of the model in the training set is too large , That is, under fitting . resolvent : Redesign the model ; Consider more powers 、 More complex models .
- If the model gets a small error on the training set , But we get a big error in the test set , This means that the model may have a large variance , It's over fitting . resolvent : Add more data ; Regularization processing .
1.2 Model selection
It is mainly a trade-off between bias and variance , Minimize the total error .
- Cross validation (Cross Validation): Divide the training set into two parts , Part of it is a training set , Part as validation set . Train the model with the training set , Then compare... On the validation set , Choose the best model , Then train the best model with all the training sets .
- N- Crossover verification (N-fold Cross Validation): Divide the training set into N Share , Will this N Training sets train separately , Then find out Average error , choice Average The model with the least error , All training sets will be used to train the model with the minimum average error .
Two 、 gradient descent
Why gradient descent method is needed ?
1. Gradient descent method is a kind of iterative method , It can be used to solve the least squares problem .
2. In solving the model parameters of machine learning algorithm , When there are no constraints , There are mainly gradient descent method , Least square method .
3. When solving the minimum value of loss function , It can be solved iteratively by gradient descent method , The loss function of the minimum value and the parameters of the model are obtained .
4. If we need to find the maximum of the loss function , You can iterate through the gradient rise method , Gradient descent method and gradient rise method can be converted to each other .
5. In machine learning , Gradient descent method mainly includes random gradient descent method and batch Gradient descent method .
—— machine learning : Why gradient descent method is needed
In the third step of the problem , The gradient descent method is used to optimize the model , That is to solve the following optimization problem :
- : Loss function (Loss Function)
- : Parameters (parameters)( Represents a set of parameters , There may be more than one )
The goal is : Find a set of parameters To minimize the loss function .( Use the gradient descent method to solve this problem )
2.1 Adjust the learning rate
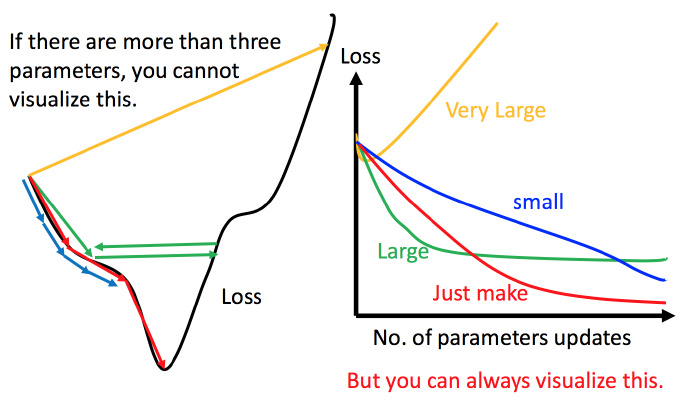
▲ Carefully adjust the learning rate
When the parameter is one-dimensional or two-dimensional , The learning rate can be adjusted through visualization , But it is difficult to visualize high-dimensional situations .
resolvent : The effect of parameter change on the loss function is visualized .
2.2 Gradient descent optimization
- SGD(Stochastic Gradient Descent, Stochastic gradient descent )
Learning principles : Select a piece of data , Just train a piece of data
shortcoming ∶
① It is sensitive to parameters , Attention should be paid to parameter initialization
② Easy to fall into local minima
③ When there is more data , Long training time
④ Every step of the iteration , All the data in the training set
- Adagrad(Adaptive gradient, Adaptive gradient )
Learning principles : Add the squares of the respective historical gradients of each dimension , Then, when updating, divide by the historical gradient value
So the learning rate of each parameter is related to its gradient , Then the learning rate of each parameter is different
shortcoming : Vulnerable to past gradients , This leads to a rapid decline in the learning rate , The ability to learn more knowledge is getting weaker and weaker , Will stop learning ahead of time . - RMSProp(root mean square prop, Root mean square )
Learning principles ∶ The attenuation factor is introduced on the basis of adaptive gradient , When the gradient accumulates , Would be right “ In the past ” And “ Now? ” Make a balance , Adjust the attenuation through super parameters .
Suitable for dealing with non-stationary targets ( That is, time related ), about RNN The effect is very good . - Adam(Adaptive momentum optimization, Adaptive momentum optimization )
It is the most popular optimization method in deep learning , It combines adaptive gradients Handle sparse gradients And root mean square Good at handling non-stationary targets The advantages of , It is suitable for large data sets and high-dimensional space .
2.3 Feature scaling
The distribution range of different characteristics varies greatly , Use feature scaling to make the range of different inputs the same .
So that different features have a considerable impact on the output , It is convenient to update parameters efficiently .
As shown in the figure below , For each dimension ( Green box ) Calculate the average , Remember to do ; Also calculate the standard deviation , Remember to do . Then use the The... In the first example Inputs , Subtract the average , Then divide by the standard deviation , The result is that all dimensions are 0, All variances are 1.
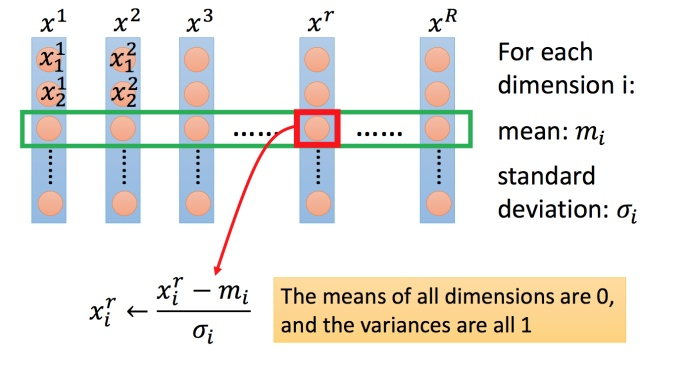
▲ Method of feature scaling
3、 ... and 、 Limitation of gradient descent
- It is easy to fall into local extremum (local minimal);
- Stuck is not extreme , But the differential value is 0 The place of ( Stagnation point );
- The differential value is close to 0 Just stop , But it's just gentle here , It's not the extreme point .

▲ Limitation of gradient descent
Four 、 summary
Datawhale Team learning , Li Hongyi 《 machine learning 》Task3. Gradient Descent( gradient descent ). Mainly including error sources 、 Judgment of under fitting and over fitting 、 gradient descent 、 Adjust the learning rate 、 Optimization of gradient descent method and limitation of gradient descent .
边栏推荐
- VBA upload pictures
- Classic line style login interface
- BSN IPFs (interstellar file system) private network introduction, functions, architecture and characteristics, access instructions
- Where is the foreign literature needed to write the graduation thesis?
- Pokemon card evolution jsjs special effect
- JS creative range select drag and drop plug-ins
- Notes (5)
- BSN IPFS(星际文件系统)专网简介、功能、架构及特性、接入说明
- Database expansion can also be so smooth, MySQL 100 billion level data production environment expansion practice
- Usage of nn.conv2d and nn.convtranspose2d functions in pytorch
猜你喜欢

RPN: region proposal networks

Which software must be used by scientific researchers to read literature?

Environment regulation system based on Internet of things (esp32-c3+onenet+ wechat applet)

Siamfc: full convolution twin network for target tracking

【LeetCode每日一题】——268.丢失的数字
![[Huawei online battle service] how can new players make up frames when the client quits reconnection or enters the game halfway?](/img/5b/02a71384c62e998d40d6ce7a98082a.png)
[Huawei online battle service] how can new players make up frames when the client quits reconnection or enters the game halfway?
![[2022 national game simulation] Bai Loujian - Sam, rollback Mo team, second offline](/img/e1/0574dd4eb311e79afdb1d071f59c4d.png)
[2022 national game simulation] Bai Loujian - Sam, rollback Mo team, second offline

晋拓股份上交所上市:市值26亿 张东家族企业色彩浓厚

C nanui related function integration

Advanced MySQL v. InnoDB data storage structure
随机推荐
Establishment of SSO single sign on environment based on CAS
Create root permission virtual environment
postman 环境变量设置代码存放
RPN: region proposal networks
selenium 代码存放
9. Learn MySQL delete statement
How to get 5L water in a full 10L container, 7L or 4L empty container
jmeter分布式
php反序列化部分学习
基于CAS的SSO单点服务端配置
Okaleido tiger is about to log in to binance NFT in the second round, which has aroused heated discussion in the community
什么是传输层协议TCP/UDP???
Leetcode summary
RPN:Region Proposal Networks (区域候选网络)
李宏毅《机器学习》丨3. Gradient Descent(梯度下降)
哪里有写毕业论文需要的外文文献?
益方生物上市首日跌16%:公司市值88亿 高瓴与礼来是股东
AMB | 迈向可持续农业:根际微生物工程
SA-Siam:用于实时目标跟踪的孪生网络
Postman environment variable setting code storage