当前位置:网站首页>How to realize parallel replication in MySQL replication
How to realize parallel replication in MySQL replication
2022-07-01 23:37:00 【Yisu cloud】
MySQL Replication How to implement parallel replication in
This article mainly introduces “MySQL Replication How to implement parallel replication in ”, In daily operation , I believe a lot of people are MySQL Replication There are doubts about how to implement parallel replication in , Xiao Bian consulted all kinds of materials , Sort out simple and easy-to-use operation methods , I hope to answer ”MySQL Replication How to implement parallel replication in ” Your doubts help ! Next , Please follow Xiaobian to learn !
Traditional single thread replication instructions
as everyone knows ,MySQL stay 5.6 Before the release , There are two threads on the slave node of master-slave replication , Namely I/O Threads and SQL Threads .
I/O The thread is responsible for receiving binary logs Event write in Relay Log.
SQL Thread reads Relay Log And play it back in the database .
The above methods occasionally cause delay , Then, what are the possible conditions that may cause the delay of the master and slave nodes ?
1. Main database performs large transactions ( Such as : Large table structure change operation ).
2. The main database is changed in large quantities ( Such as : A large number of insert 、 to update 、 Delete operation ).
3.ROW In synchronous mode , The primary database large table has no primary key and is frequently updated .
4. The database parameter configuration is unreasonable , There is a bottleneck in the slave node performance ( Such as : The setting from the node transaction log is too small , Cause frequent disk brushing ).
5. The network environment is unstable , From the node IO Thread reads binlog There is a delay 、 Reconnection .
6. The master-slave hardware configuration is different , The hardware resource usage of the slave node has reached the upper limit .( such as : Master node SSD disc , From the node SAS disc )
The above reasons for delay can be roughly classified .
1. Hardware problems ( Include disk IO、 The Internet IO etc. )
2. Configuration problems .
3. Database design issues .
4. The main database is changed in large quantities , From the node SQL Single thread processing is not timely .
summary
By analyzing the above reasons, we can see that to reduce the master-slave delay , In addition to improving the hardware conditions , The other is the need DBA Focus on database design and configuration issues , Finally, it is necessary to improve the concurrent processing capability of the slave node , Changing from single thread playback to multi thread parallel playback is a better method , The key point is how to solve the problem of data conflict and confirmation of fault recovery location point under the premise of multi-threaded recovery .
MySQL5.6 Parallel replication based on Library level
In the case of multiple databases in the instance , Can open multiple threads , Each thread corresponds to a database . In this mode, the slave node will start multiple threads . Threads fall into two categories
CoordinatorandWorkThread.
Thread division executes logic
Coordinator Threads are responsible for determining whether transactions can be executed in parallel , If it can be done in parallel, the transaction will be distributed to WorkThread Threads execute , If the judgment cannot be executed , Such as DDL, Across the library operation etc. , Just wait for all worker After thread execution , Again by Coordinator perform .
Key configuration information
slave-parallel-type=DATABASE
The scheme is insufficient
This parallel replication mode , Only in instances where there are multiple DB And DB Only when the transactions of are relatively busy will there be a high degree of parallelism , However, in daily maintenance, the transaction processing of a single instance is relatively concentrated in one DB On . By observing the delay, it can be found that the delay is mainly based on the hotspot table . It is a good way to provide table based parallelism .
MySQL5.7 Parallel replication based on group commit
Group submission instructions
Simply put, it is in the double 1 Set up , After the transaction is committed, the disk flushing operation is changed to merge multiple transactions into a group of transactions, and then perform Unified Disk flushing , This process lowers the disk IO The pressure of the . Details reference
Lao Ye teahouseTweets about group submissionshttps://mp.weixin.qq.com/s/rcPkrutiLc93aTblEZ7sFg
A group of transactions are committed at the same time, which means that there is no conflict between transactions in the group , Therefore, the transactions in the group can be executed concurrently on the slave node , The problem is how to distinguish whether transactions are in the same group , So in binlog Two new parameter messages appear in last_committed and sequence_number
How to judge whether a transaction is in a group ?
analysis binlog You can see there's more in it
last_committedandsequence_numberTwo parameter information , amonglast_committedThere is duplication .
sequence_number# This value refers to the sequence number of the transaction commit , Monotone increasing .last_committed# This value has two meanings ,1. The same value means that these transactions are in the same group ,2. This value is also the maximum number representing the last set of transactions .
[[email protected] GreatSQL]# mysqlbinlog mysql-bin.0000002 | grep last_committedGTID last_committed=0 sequence_number=1GTID last_committed=0 sequence_number=2GTID last_committed=2 sequence_number=3GTID last_committed=2 sequence_number=4GTID last_committed=2 sequence_number=5GTID last_committed=2 sequence_number=6GTID last_committed=6 sequence_number=7GTID last_committed=6 sequence_number=8
Database configuration
slave-parallel-type=LOGICAL_CLOCK
The scheme is insufficient
There is a deficiency in group based synchronization , That is, when the transaction busy degree of the primary node is low , Results in group submission in the time period fsync The amount of disk flushing transactions is less , As a result, the parallelism of playback from the library is not high , There may even be only one transaction in a group , In this way, the multithreading of slave nodes is basically unnecessary , You can set the following two parameters , Let the master node delay the submission .
binlog_group_commit_sync_delay # Time to wait for late submission ,binlog Wait for a while after submitting fsync. Let each group More things to do , Artificially improve the parallelism .
binlog_group_commit_sync_no_delay_count # Maximum number of transactions to be committed , If the waiting time is not up , The number of transactions reached , Right now fsync. Commit as soon as the desired parallelism is reached , Try to minimize the waiting delay .
MySQL8.0 be based on writeset Parallel replication of
writeset A method to judge whether a transaction can be played back in parallel based on the conflict of transaction results , He is made up of
binlog-transaction-dependency-trackingParameter control , By defaultWRITESETMethod .
View key parameters
| Command-Line Format | --binlog-transaction-dependency-tracking=value |
|---|---|
| System Variable | binlog_transaction_dependency_tracking |
| Scope | Global |
| Dynamic | Yes |
| SET_VAR Hint Applies | No |
| Type | Enumeration |
| Default Value | COMMIT_ORDER |
| Valid Values | COMMIT_ORDER WRITESET WRITESET_SESSION |
Parameter configuration item description
COMMIT_ORDER# Use 5.7 Group commit The way in which the transaction depends .WRITESET# Determine transaction dependencies by writing collections .WRITESET_SESSION# Use write set , But the same session Transactions in cannot have the same last_committed.
writeset It's a HASH An array of types , It records the updated information of the transaction , adopt
transaction_write_set_extractionJudge whether the record updated by the current transaction conflicts with the record updated by the historical transaction , After judgment, the corresponding treatment method shall be adopted .writeset The maximum stored value is determined bybinlog-transaction-dependency-history-sizecontrol .
It should be noted that , When set to
WRITESETorWRITESET_SESSIONWhen , Transaction commit is out of order , Can be set byslave_preserve_commit_order=1Force sequential submission .
binlog_transaction_dependency_history_size
Set the maximum number of row hashes saved in memory , Used to cache row information modified by previous transactions . Once this hash number is reached , Will clear the history .
| Command-Line Format | --binlog-transaction-dependency-history-size=# |
|---|---|
| System Variable | binlog_transaction_dependency_history_size |
| Scope | Global |
| Dynamic | Yes |
| SET_VAR Hint Applies | No |
| Type | Integer |
| Default Value | 25000 |
| Minimum Value | 1 |
| Minimum Value | 1000000 |
transaction_write_set_extraction
This mode supports three algorithms , By default XXHASH64, When the slave node is configured writeset When copying , This configuration cannot be configured as OFF. This parameter is already in MySQL 8.0.26 Abandoned in , It will be deleted later .
| Command-Line Format | --transaction-write-set-extraction[=value] |
|---|---|
| Deprecated | 8.0.26 |
| System Variable | binlog_transaction_dependency_history_size |
| Scope | Global, Session |
| Dynamic | Yes |
| SET_VAR Hint Applies | No |
| Type | Enumeration |
| Default Value | XXHASH64 |
| Valid Values | OFF MURMUR32 XXHASH64 |
Database configuration
slave_parallel_type = LOGICAL_CLOCKslave_parallel_workers = 8binlog_transaction_dependency_tracking = WRITESETslave_preserve_commit_order = 1
Here we are , About “MySQL Replication How to implement parallel replication in ” That's the end of my study , I hope we can solve your doubts . The combination of theory and practice can better help you learn , Let's try ! If you want to continue to learn more related knowledge , Please continue to pay attention to Yisu cloud website , Xiaobian will continue to strive to bring you more practical articles !
边栏推荐
- excel如何打开100万行以上的csv文件
- 物联网技术应用属于什么专业分类
- Switch to software testing, knowing these four points is enough!
- ConcurrentSkipListMap——跳表原理
- SWT / anr problem - SWT causes low memory killer (LMK)
- Experience of practical learning of Silicon Valley products
- 转行软件测试,知道这四点就够了!
- 股票开户哪个证券公司最好,有安全保障吗
- URL introduction
- Current situation and future development trend of Internet of things
猜你喜欢
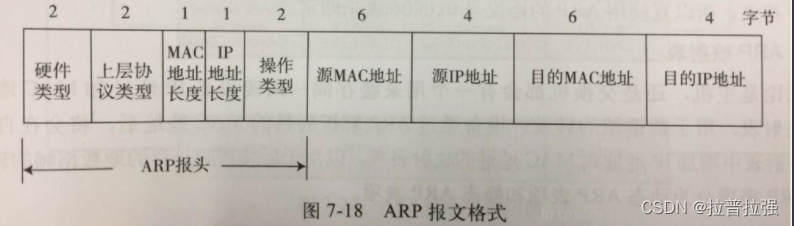
ARP message header format and request flow

2022 crane driver (limited to bridge crane) examination questions and simulation examination

Redis RDB快照

Redis master-slave synchronization

安全协议重点
2022年最佳智能家居开源系统:Alexa、Home Assistant、HomeKit生态系统介绍
The best smart home open source system in 2022: introduction to Alexa, home assistant and homekit ecosystem
PyCharm调用matplotlib绘图时图像弹出问题怎么解决

Material Design组件 - 使用BottomSheet展现扩展内容(一)

华为HMS Core携手超图为三维GIS注入新动能
随机推荐
const // It is a const object...class nullptr_t
Yunxin small class | common cognitive misunderstandings in IM and audio and video
algolia 搜索需求,做的快自闭了...
深度学习 | 三个概念:Epoch, Batch, Iteration
Matplotlib common charts
The third part of the construction of the defense system of offensive and defensive exercises is the establishment of a practical security system
Zero foundation tutorial of Internet of things development
每日三题 6.28
Depth first search and breadth first search of graph traversal
Li Kou today's question -241 Design priorities for operational expressions
golang中的iota
2021 robocom world robot developer competition - semi finals of higher vocational group
What is the difference between memory leak and memory overflow?
TS初次使用、ts类型
2021 robocom world robot developer competition - preliminary competition of higher vocational group
Notes on problems - /usr/bin/perl is needed by mysql-server-5.1.73-1 glibc23.x86_ sixty-four
Notes to problems - file /usr/share/mysql/charsets/readme from install of mysql-server-5.1.73-1 glibc23.x86_ 64 c
[LeetCode] 最后一个单词的长度【58】
2022年最佳智能家居开源系统:Alexa、Home Assistant、HomeKit生态系统介绍
力扣今日题-241. 为运算表达式设计优先级