当前位置:网站首页>High frequency interview 𞓜 Flink Shuangliu join
High frequency interview 𞓜 Flink Shuangliu join
2022-06-26 15:22:00 【Big data Arsenal】

Hello everyone , I'm a veteran .
Talk to you today Flink Double current Join problem . This is a high-frequency interview site , It is also a real scene often encountered in work .
How to ensure Flink Double current Join accuracy and timeliness 、 except window join What other implementations exist 、 How on earth can the interviewer be impressed by the answer .. You will find the answer in the text .

1 Introduction
1.1 database SQL Medium JOIN
Let's look at the database first SQL Medium JOIN operation . Order query as shown below SQL, By adding... To the order form id And order details order_id relation , Get the product information under all orders .
select
a.id as ' Order id',
a.order_date as ' Order time ',
a.order_amount as ' Order amount ',
b.order_detail_id as ' Order details id',
b.goods_name as ' Name of commodity ',
b.goods_price as ' commodity price ',
b.order_id as ' Order id'
from
dwd_order_info_pfd a
right join
dwd_order_detail_pfd b
on a.id = b.order_id
This is a very simple paragraph SQL Code , I won't go into details . Here we mainly introduce SQL Medium JOIN type , Here's what I'm using right join , Right connection .
left join: Keep all the data in the left table and the associated data in the right table , The non associated data in the right table is set to NULLright join: Keep all the data in the right table and the associated data in the left table , The left table sets the non associated data NULLinner join: Keep the left table associated data and the right associated datacross join: Preserve Cartesian product of left and right table data
Line by line Association matching based on association key value , Filter table data and generate final results , It is provided for downstream data analysis .
stop here and now , About databases SQL Medium JOIN The principle will not be repeated , If you are interested, you can study by yourself , Let's turn our attention to the big data field .

1.2 Offline scenario JOIN
Suppose there is such a scenario :
It is known that Mysql Order table and order details in the database , And satisfy the one to many relationship , Statistics T-1 Product distribution details of all orders within days .
Smart people must have given the answer , you 're right ~ It's up there SQL:
select a.*, b.*
from
dwd_order_info_pfd a
right join
dwd_order_detail_pfd b
on a.id = b.order_id
Now modify the following conditions : It is known that both the order table and the order details are Billion level data , Find the analysis results under the same scenario .
To do ? At this time, the relational database seems not suitable ~ Start zooming in : Use Big data computing engine To solve .
in consideration of T-1 Statistical scenarios have very low requirements for timeliness , have access to Hive SQL To deal with it , Bottom run Mapreduce Mission . If you want to improve the running speed , Switch to Flink or Spark Calculation engine , Use memory computing .

As for inquiry SQL Same as above , And encapsulate it into a scheduled scheduling task , Wait for the system to be dispatched . If the result is not correct , Because the data source and data static state unchanged , It's a big deal , It looks like it feels like All's well that ends well ~
But not for long , At this time, the product enemy has given you an irresistible demand : I want real-time statistics !!
2 Real time scene JOIN
Or the scene above , At this point, the data source is changed to real time Order flow and real time Order flow , such as Kafka Of the two topic, It is required to make real-time statistics on the distribution details of goods under all orders every minute .

Now the situation seems to be getting more complicated , A brief analysis :
data source . Real time data flow , Unlike static flow , Data flows in real time and changes dynamically , The computing program needs to support the real-time processing mechanism . Relevance . Mentioned earlier static stateData is executed multiple times join operation , The data that can be associated between the left table and the right table is very constant ; andReal time data flow( Left and right tables ) If the timing of entry is inconsistent , The data that can be associated will not be associated or errors will occur .Delay . Real time statistics , Provide minute or even second level response results .
Because stream data join The particularity of , In the meet Real time processing mechanism 、 Low latency 、 Strong correlation Under the premise of , It seems that a sound data scheme needs to be developed , To achieve real streaming data JOIN.
2.1 Plan ideas
We know that the relationship between order data and order details is one to many , That is, one order data corresponds to multiple commodity details , After all, buying a commodity also costs so much postage , It's better to pack and buy .. One detail data only corresponds to one order data .
such , Double current join The strategy can consider the following ideas :
When the data flow is order data . Unconditional reservation , Whether it is currently associated with detailed data or not , Are reserved for follow-up join Use . When the data flow is detailed data . After being associated with its order data , Can say goodbye 了 , Otherwise, it is reserved for the next encounter with the order data . Complete all order data and order detail data in the same period join, Clear storage status 
In the actual production scenario , More complex situations need to be considered , Include JOIN Process data loss and other abnormal conditions , Only for illustration here .
Okay , It seems that we already have a sloppy real-time stream JOIN The prototype of the plan .
It seems that we can prepare for a big fight ~ take it easy , Someone has helped us achieve it secretly :Apache Flink
3 Flink Double current of JOIN
Apache Flink Is a framework and distributed processing engine , Used for stateful computation of unbounded and bounded data flows .Flink Designed to run in all common cluster environments , Perform calculations at memory execution speed and at any size .
—— come from Flink Official website definition
Here we just need to know Flink It is just a real-time computing engine , It mainly focuses on how to realize dual flow JOIN.
3.1 Internal operating mechanism
Memory computing:Flink Task priority is calculated in memory , Save to a highly accessible disk when there is not enough memory , ProvideSecond levelDelay response .State strong consistency:Flink Use a consistent snapshot to save state , And regularly check the local state to the persistent storage to ensure the state consistency .Distributed execution:Flink Applications can be divided into numerous parallel tasks that are executed in a cluster , Almost unlimited use CPU、 Main memory 、 Disk and network IO.Built in advanced programming model:Flink The programming model is abstracted as SQL、Table、DataStream|DataSet API、Process four layers , And encapsulate it into an operator with rich functions , And that includesJOIN typeThe operator of .

Take a closer look at , The real-time streams we discussed in the previous chapter JOIN Are the prerequisites of the scheme met ?
Real time processing mechanism: Flink Born as a real-time computing engineLow latency: Flink Memory calculation second delayStrong correlation: Flink State consistency and join Class operator
Can't help sighing , This Flink It's really strong ~
Be curious , Let's go and have a look Flink Double current join The true meaning of !!
3.2 JOIN Implementation mechanism
Flink Double current JOIN There are two main categories . One is based on native State Of Connect Operator operation , The other is window based JOIN operation . Which is based on window JOIN It can be subdivided into window join and interval join Two kinds of .
Realization principle : The underlying principles depend on Flink Of State State storage, By storing data in State To make a connection join, Final output .

See light suddenly , Flink It was through State State to cache wait join Real time streaming of .
Here's a question for you :
use redis Can storage ,state Storage compared to redis The difference between storage ?
More details are welcome to discuss , Add personal wechat : youlong525 Pull you into the group , And free Flink PDF receive ~
Back to the point , How do these methods achieve dual flow JOIN Of ? Let's move on .
Be careful : The following content will be more like
written words+CodeIn the form of , Avoid boredom , I put a bunch of original sketches ~
4 be based on Window Join Double current of JOIN Implementation mechanism
seeing the name of a thing one thinks of its function , In this way Flink Of Window mechanism Realize double flow join. Easy to understand , Allocate the elements in the two real-time streams to the same time window Join.
Underlying principle : Two real-time stream data are cached in Window Statein , When a window triggers a calculation , perform join operation .
4.1 join operator
Have a look first Window join One of the implementation methods join operator . This involves Flink Windows in (window) Concept , therefore Window Join According to the window type, it can be subdivided into 3 Kind of :
Tumbling Window Join ( Scroll the window )

Sliding Window Join ( The sliding window )
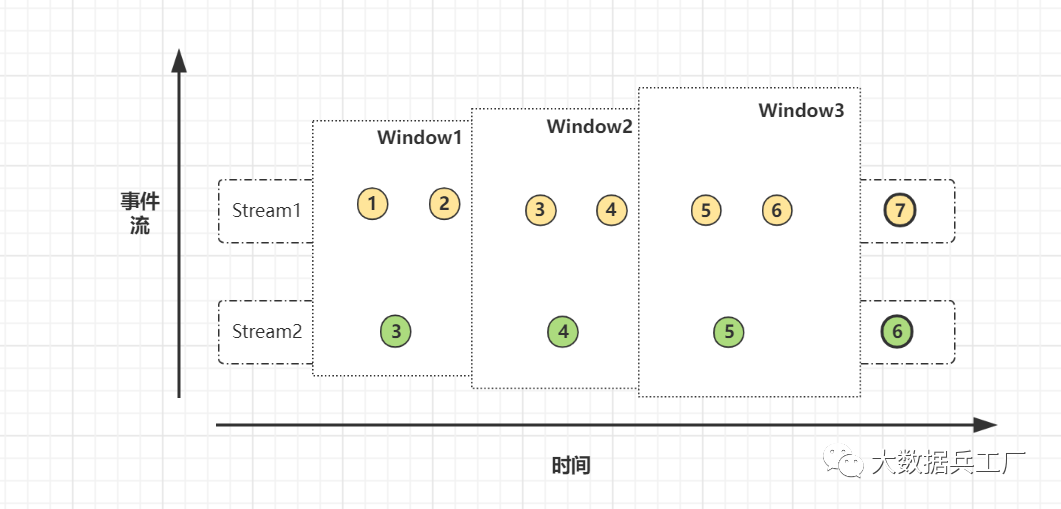
Session Widnow Join( Session window )

The data of the two streams are displayed in the... According to the associated primary key ( rolling 、 slide 、 conversation ) In the window inner join, Bottom based State Storage , It supports two time characteristics: processing time and event time , Look at the source :

Source code core summary :windows window + state Storage + double for Loop execution join()
Now let's pull the timeline back a little , stay Real time scene JOIN Where we received this demand : Make statistics on the distribution of product details under all orders in every minute .
OK, Use join Let's have a try . We define 60 Second scrolling window , Pass the order flow and order details flow through order_id relation , The following procedure is obtained :
val env = ...
// kafka Order flow
val orderStream = ...
// kafka Order flow
val orderDetailStream = ...
orderStream.join(orderDetailStream)
.where(r => r._1) // Order id
.equalTo(r => r._2) // Order id
.window(TumblingProcessTimeWindows.of(
Time.seconds(60)))
.apply {(r1, r2) => r1 + " : " + r2}
.print()
The whole code is actually very simple , In summary :
Define two input real-time streams A、B A Stream call join(b flow ) operator Association definition : where by A Stream correlation key ,equalTo by B Stream correlation key , It's all orders id Definition window window (60s interval ) apply Method to define the logical output
So as long as the program runs stably , It can continuously calculate the order distribution details per minute , It seems to have solved the problem ~
Don't be happy too soon , Don't forget the join The type is inner join. Review your knowledge :inner join This means that only the data associated with two streams is preserved .
In this way, the data not related to the two streams are lost ? Don't worry ,Flink There's another window join operation : coGroup operator .
4.2 coGroup operator
coGroup The operator is also based on window Window mechanism , however coGroup Operator ratio Join Operators are more flexible , The left stream or right stream data can be matched and output according to the logic specified by the user .
let me put it another way , We achieve this by specifying the output of the two streams left join and right join Purpose .
Now let's look at the same scenario coGroup How operators are implemented left join:
# Look at here java Writing
orderDetailStream
.coGroup(orderStream)
.where(r -> r.getOrderId())
.equalTo(r -> r.getOrderId())
.window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.apply(new CoGroupFunction<OrderDetail, Order, Tuple2<String, Long>>() {
@Override
public void coGroup(Iterable<OrderDetail> orderDetailRecords, Iterable<Order> orderRecords, Collector<Tuple2<String, Long>> collector) {
for (OrderDetail orderDetaill : orderDetailRecords) {
boolean flag = false;
for (Order orderRecord : orderRecords) {
// There are corresponding records in the right stream
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), orderDetailRecords.getGoods_price()));
flag = true;
}
if (!flag) {
// There is no corresponding record in the right stream
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), null));
}
}
}
})
.print();
Here are a few points :
join Replace operator with coGroup operator The two streams still need to be in one window And define the association conditions apply Method , The right value is judged here : If there is a value, connect and output , Otherwise, the right side is set to NULL.
You can say that , Now we have completely finished the window double flow JOIN.
As long as you provide me with the specific window size , I can pass join or coGroup Operators churn out all kinds of tricks join, And it is very simple to use .
But if at this time our dear product puts forward a small condition :
The rush hour , The commodity data will not be written in time in a certain period , The time may be earlier or later than the order , Also calculate the order item distribution details per minute , B: no problem! ~
Of course there are problems : If the two streams are out of step , Windows are also used to control join That's weird ~ It's easy not to wait join The stream window closes automatically .
not so bad , That's true. Flink Provides Interval join Mechanism .
5 be based on Interval Join Double current of JOIN Implementation mechanism
Interval Join According to the time interval when the right stream is offset from the left stream (interval) As an associated window , Complete in the offset interval window join operation .
It's a little hard to understand , Let me draw a picture :
stream2.time ∈ (stream1.time +low, stream1.time +high)
Satisfy data flow stream2 In the data stream stream1 Of interval(low, high) Offset intra interval correlation join.interval The bigger it is , More data on the Association , beyond interval The data of is no longer associated .
Realization principle :interval join It's also the use of Flink Of state Store the data , But at this time there is state Failure mechanism ttl, Trigger data cleaning operation .
Here comes another question :
state Of ttl How to set the mechanism ? Unjustified ttl Set whether the memory will burst ?
I will explain it in depth in the following articles State Of ttl Mechanism , Welcome to discuss ~
Let's take a look at interval join The code implementation process of :
val env = ...
// kafka Order flow
val orderStream = ...
// kafka Order flow
val orderDetailStream = ...
orderStream.keyBy(_.1)
// call intervalJoin relation
.intervalJoin(orderDetailStream._2)
// Set the upper and lower time limits
.between(Time.milliseconds(-30), Time.milliseconds(30))
.process(new ProcessWindowFunction())
class ProcessWindowFunction extends ProcessJoinFunction...{
override def processElement(...) {
collector.collect((r1, r2) => r1 + " : " + r2)
}
}
The order flow flows into the program , Wait (low,high) Order details flow data within the time interval join, Otherwise, proceed to the next stream .
From the code we find that ,interval join Need to be in two KeyedStream Above , namely keyBy(), And in between() Method to specify the upper and lower bounds of the offset interval .
It should be noted that interval join What we have achieved is also inner join, At present, only the event time is supported .
6 be based on Connect Double current of JOIN Implementation mechanism
In front of the use of Window join perhaps Interval Join To achieve dual flow join When , I found something in common :
Either way ,Flink The interior will join The process
Transparency, All the implementation details are encapsulated in the operator .
What is it? ? It's... In programming languages abstract Concept ~ Hide the underlying details , External exposure is unified API, Big simplify Program code .
But this will lead to a problem : If the program reports an error or the data is abnormal , How to quickly perform tuning and troubleshooting , Look directly at the source code ? Unrealistic ..
Here is an introduction based on Connect operator Implementation of the dual stream JOIN Method , We can control Shuangliu by ourselves JOIN Processing logic , While maintaining the timeliness and accuracy of the process .
6.1 Connect Operator principle
The two one. DataStream perform connect operation , Convert it to ConnectedStreams, Generated Streams Different methods can be called to execute on two real-time streams , And the state can be shared between two streams .

On the picture we can see , Two data streams are connect after , Just put it in the same stream , Their own data and forms are still maintained internally , The two streams are independent of each other .
[DataStream1, DataStream2] -> ConnectedStreams[1,2]
such , We can do it in Connect At the bottom of the operator ConnectedStreams Write code based on , Self realization of dual flow JOIN Logical processing of .
6.2 Technical realization
1. call connect operator , according to orderid Grouping , And use process Operators handle the two streams respectively .
orderStream.connect(orderDetailStream)
.keyBy("orderId", "orderId")
.process(new orderProcessFunc());
2.process Method for state programming , Initialize order 、 Order details and timer ValueState state .
private ValueState<OrderEvent> orderState;
private ValueState<TxEvent> orderDetailState;
private ValueState<Long> timeState;
// Initialization status Value
orderState = getRuntimeContext().getState(
new ValueStateDescriptor<Order>
("order-state",Order.class));
····
3. Save for each incoming data stream state Status and create timer . When another stream arrives in the time window join And the output , Delete timer when finished .
@Override
public void processElement1(Order value, Context ctx, Collector<Tuple2<Order, OrderDetail>> out){
if (orderDetailState.value() == null){
// The detailed data has not arrived , First put the order data into the status
orderState.update(value);
// Set up the timer ,60 Seconds later
Long ts = (value.getEventTime()+60)*1000L;
ctx.timerService().registerEventTimeTimer(
ts);
timeState.update(ts);
}else{
// Detailed data has arrived , Direct output to the mainstream
out.collect(new Tuple2<>(value,orderDetailS
tate.value()));
// Delete timer
ctx.timerService().deleteEventTimeTimer
(timeState.value());
// Empty state , Note that the order details status is cleared
orderDetailState.clear();
timeState.clear();
}
}
...
@Override
public void processElement2(){
...
}
4. The data stream that does not arrive in time triggers the timer to output to the side output stream , The left stream arrives first and the right stream does not , Then the left stream is output , On the contrary, right continuous flow is output .
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple2<Order, OrderDetail>> out) {
// Realize left connection
if (orderState.value() != null){
ctx.output(new OutputTag<String>("left-jo
in") {},
orderState.value().getOrderId());
// Realize the right connection
}else{
ctx.output(new OutputTag<String>("right-jo
in") {},
orderDetailState.value().getOrderId());
}
orderState.clear();
orderDetailState.clear();
timeState.clear();
}
The general idea : Realize the association between order data and order detail data based on data time , Timeout or missing is output by the side output stream .
stay
connectFor order flow and order detail flow , First create a timer and savestatestate , In the windowjoin, Otherwise, enter the side output stream .
7 Double current JOIN Optimization and summary of
Why my Shuangliu join When the time comes, it doesn't trigger , There has been no output
Check the
watermarkIs it reasonable to set ,Data timeIs it much larger than watermark And window time , As a result, the window data is often empty
state How long is the data stored , Will the memory explode
state Bring with you
ttl Mechanism, You can set ttl Expiration strategy , Trigger Flink Cleanup expired state data . Suggest... In the programstate data structureManually after use clear fall .
My Shuangliu join What about tilting
join Tilt the tripod axe : Filter exception key、 Split tables to reduce data 、 Break up key Distribution . Of course, I suggest adding memory ! Add memory ! Add memory !!
Want to achieve multi stream join What do I do
At present, it cannot be realized at one time , You can consider... First union And then do it again ; Or do it first connnect Operate again join operation , Only recommend ~
join Process delay 、 Will the data not associated be lost
Generally speaking, not ,join Procedures can use side output streams to store delayed streams ; If there are exceptions such as node network ,Flink checkpoint It can also ensure that data is not lost .
One day
interviewer : Flink Double current join Understand? ? Briefly talk about its implementation principle .
A gentleman : Flink Double current JOIN yes ...
The end of this paper .

E N D
【 give the thumbs-up 】【 Focus on 】 A wave to take away
Provide big data & AI premium content
The background to reply 【 Add group 】 Neverlost
边栏推荐
- 使用RestCloud ETL Shell组件实现定时调度DataX离线任务
- [tcapulusdb knowledge base] tcapulusdb system user group introduction
- Program analysis and Optimization - 8 register allocation
- Advanced operation of MySQL database basic SQL statement tutorial
- 夏令营来啦!!!冲冲冲
- Redis-集群
- MongoDB系列之Window环境部署配置
- Unity C# 网络学习(八)——WWW
- Sikuli automatic testing technology based on pattern recognition
- Function: crypto JS encryption and decryption
猜你喜欢

Restcloud ETL extracting dynamic library table data

The heavyweight white paper was released. Huawei continues to lead the new model of smart park construction in the future
RestCloud ETL抽取動態庫錶數據實踐

Comparative analysis of restcloud ETL and kettle

【ceph】cephfs的锁 笔记

【TcaplusDB知识库】TcaplusDB单据受理-建表审批介绍

功能:crypto-js加密解密

【TcaplusDB知识库】TcaplusDB系统用户组介绍
Mr. Du said that the website was updated with illustrations
[tcapulusdb knowledge base] Introduction to tcapulusdb general documents

随机推荐
Cluster addslots establish a cluster
【TcaplusDB知识库】TcaplusDB常规单据介绍
[tcapulusdb knowledge base] tcapulusdb system user group introduction
Optimizing for vectorization
SAP sales data actual shipment data export sales
TS common data types summary
English grammar_ Adjective / adverb Level 3 - original sentence pattern
The tablestack function of the epidisplay package of R language makes a statistical summary table (descriptive statistics of groups, hypothesis test, etc.), does not set the by parameter to calculate
R language uses the aggregate function of epidisplay package to split numerical variables into different subsets based on factor variables, calculate the summary statistics of each subset, and use agg
Execution of commands in the cluster
PHP file upload 00 truncation
Mongodb series window environment deployment configuration
R language GLM function logistic regression model, using epidisplay package logistic The display function obtains the summary statistical information of the model (initial and adjusted odds ratio and
【TcaplusDB知识库】TcaplusDB单据受理-创建业务介绍
ETL过程中数据精度不准确问题
[tcapulusdb knowledge base] Introduction to tcapulusdb general documents
MySQL数据库基本SQL语句教程之高级操作
clustermeet
[tcapulusdb knowledge base] tcapulusdb operation and maintenance doc introduction
【毕业季·进击的技术er】 什么是微信小程序,带你推开小程序的大门