当前位置:网站首页>ICML 2022 | sparse double decline: can network pruning also aggravate model overfitting?
ICML 2022 | sparse double decline: can network pruning also aggravate model overfitting?
2022-07-23 16:19:00 【PaperWeekly】

author | Zheng He
Company | Beijing university of aeronautics and astronautics
Research direction | Deep learning
This article shares our new work in network pruning 「Sparse Double Descent: Where Network Pruning Aggravates Overfitting」. This paper is mainly influenced by the parameterization of the model (over-parameterization) And lottery hypothesis (lottery tickets) Inspiration from two aspects of research , The generalization performance of pruned sparse neural network is explored and analyzed .
One word conclusion : The generalization ability of sparse neural networks is affected by sparsity , As the sparsity increases , The test accuracy of the model will decline first , After rising , Finally, it fell again .

Paper title :
Sparse Double Descent: Where Network Pruning Aggravates Overfitting
The conference :
ICML 2022
Thesis link :
https://arxiv.org/abs/2206.08684
Code link :
https://github.com/hezheug/sparse-double-descent

Research motivation
According to the viewpoint of traditional machine learning , It is difficult for the model to minimize the deviation and variance of prediction at the same time , Therefore, it is often necessary to weigh the two , To find the most suitable model . This is the widely spread deviation - Variance equilibrium (bias-variance tradeoff) curve : As the model capacity increases , The error of the model on the training set keeps decreasing , However, the error in the test set will first decrease and then increase .

▲ deviation - Variance equilibrium (bias-variance tradeoff) curve
Although the traditional view is that too many model parameters will lead to over fitting , But the magic is , In the practice of deep learning , Large models tend to perform better .
This year, some scholars found , The relationship between the test error of the deep learning model and the model capacity , It's not U Type curve , It's what you have Double drop (Double Descent) Characteristics , namely As the model parameters become more , The test error decreases first , Go up again , Then fall for the second time [1,2].

▲ Double descent curve [2]
in other words , The neural network with over parameters will not have serious over fitting , Instead, it may have better generalization performance !
Why on earth is this ?
The lottery hypothesis (lottery tickets)[5] It provides a new way to explain this phenomenon . The lottery hypothesis holds that , A randomly initialized dense network ( Uncut initial network ), contains Sparse subnet with good performance , This sub network is from Original initialization (winning ticket) Training when , It can achieve the accuracy comparable to the original dense network , It may even converge faster ( And if you let this sub network start training from a new initialization value , The effect is often much worse than the original network ).
When there are more network parameters , The greater the probability that it contains such a sub network with good performance , That is, the higher the probability of winning the lottery . From this point of view , In a parametric neural network , There may only be quite a few parameters that really work on Optimization and generalization , The remaining parameters exist only as redundant backups , Even if it is cut off, it will not have a decisive impact on model training .
The lottery hypothesis seems to indicate , We can safely cut out redundant parameters in the model , Don't worry about whether it will cause adverse effects . There are other documents , Based on the principle of simple and optimal Occam razor , It is believed that the pruned sparse network will have better generalization ability [4]. Current pruning literatures also emphasize that their algorithms can cut a large number of parameters , Still maintain the accuracy comparable to the original model .
But think of the double decline phenomenon , We can't help but reflect on a basic problem : Are the pruning parameters really completely redundant ? Isn't the double descent with better parameters tenable on sparse neural networks ? To find the answer to this question , We refer to deep double descent [2] Set up , A large number of experiments have been carried out on sparse neural networks .

Double descent phenomenon in sparse neural networks
Through the experiment , We were surprised to find that , The so-called " redundancy " The parameters of are not completely redundant . When the parameter quantity gradually decreases , When the sparsity gradually increases , Even if the accuracy of model training has not been affected , Its test accuracy may have begun to decline significantly . At this time , The model is more and more over fitting noise .
If we further increase the sparsity of the model , It can be found that after passing a certain inflection point , The training accuracy of the model began to decline rapidly , The test accuracy began to rise , At this time, the robustness of the model to noise is gradually improved . As for when the test accuracy reaches the highest point , If you continue to reduce the parameters of the model , It will affect the learning ability of the model . here , The accuracy of model training and testing decreases at the same time , It becomes difficult to learn .

▲ Sparse double descent phenomenon on different data sets . Left :CIAFR-10, in :CIFAR-100, Right :Tiny ImageNet
Besides , We also found that different standards were used to prune , Even if the parameters of the obtained model are the same , Its model capacity / The complexity is different . For example, for the same inflection point , The model with weight based pruning has higher sparsity , Random pruning corresponds to low sparsity . It shows that random pruning destroys the expression ability of the model more , You can only cut fewer parameters to achieve the same effect .

▲ Sparse double descent phenomenon under different pruning Standards . Left : Weight based pruning , in : Gradient based pruning , Right : Random pruning
Although most of our experiments use the lottery hypothesis retrain The way , But also tried several other different methods . Interestingly , Even fine-tuning after pruning (Finetuning) A significant double decrease can also be observed . It can be seen that the sparse double descent phenomenon is not limited to training a sparse network from initialization , Even using the parameter values trained before pruning will have similar results .
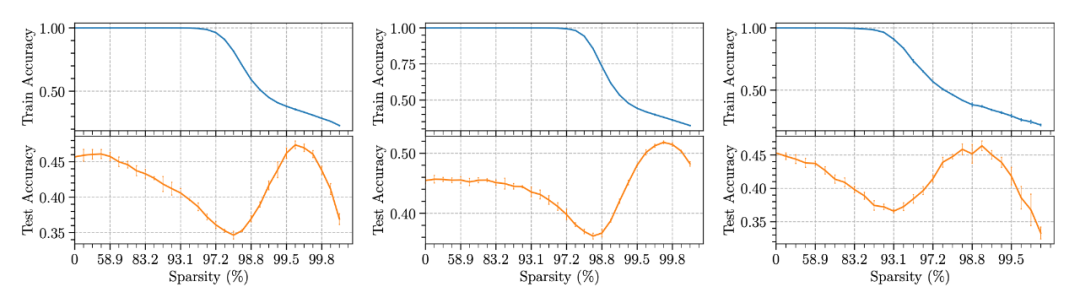
▲ Different retrain Sparse double descent phenomenon under method . Left :Finetuning, in :Learning rate rewinding, Right :Scratch retraining
We also adjusted the proportion of label noise , To observe the change of double decline phenomenon . Be similar to deep double descent, Increase the proportion of label noise , The starting point that will reduce the accuracy of model training , Move towards higher model capacity ( That is, lower sparsity ). And on the other hand , The higher the label noise ratio , In order to achieve robustness to noise , More parameters need to be cut to avoid over fitting .

▲ Sparse double drop phenomenon under different label noise ratios . Left :20%, in :40%, Right :80%

How to explain the generalization performance and double decline phenomenon of sparse neural networks ?
Here we mainly examine two possible explanations . The first is Minimum point flat vacation (Minima Flatness Hypothesis). Some articles point out that , Pruning can add disturbance to the model , This disturbance makes it easier for the model to converge to a flat minimum [5]. Because the smallest point is flatter , Generally, it will have better generalization ability , therefore [5] It is considered that pruning affects the generalization of the model by affecting the flatness of the minimum point .
that , Can the change of the flatness of the minimum explain the sparse double decline ? We are right. loss Visualize as shown in the figure , Indirectly compared under different sparsity , The flatness of the minimum point of the model .

▲ A one-dimensional loss visualization
Unfortunately , As the sparsity increases ,loss The curve becomes steeper and steeper ( Unevenness ). There is no correlation between the flatness of the minimum point and the test accuracy .
The other is Learning distance hypothesis (Learning Distance Hypothesis). It has been proved by theoretical work , The complexity of the deep learning model is related to the initialization of parameters l2 distance ( Learning distance ) Is closely linked [6]. The smaller the learning distance , It indicates that the model stays closer to initialization , Like the model parameters obtained when stopping early , At this time, there is not enough complexity to remember the noise ; conversely , Then it shows that the model changes more in the parameter space , At this time, the complexity is higher , Easy to overfit .
that , Can the change of learning distance reflect the double downward trend ?
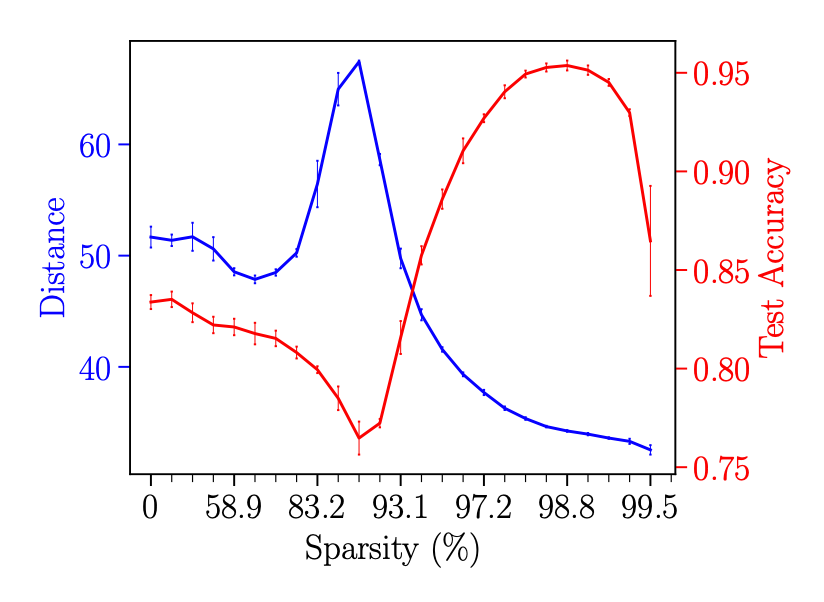
▲ Curve of model learning distance and test accuracy
As shown in figure shows , When the accuracy decreases , The overall learning distance is on the rise , And the highest point just corresponds to the lowest point of accuracy ; And when the accuracy increases , The learning distance decreases accordingly . The change of learning distance is basically consistent with the trend of sparse double decline ( Although when the test accuracy drops for the second time , Because there are too few parameters that can be trained , Learning distance is difficult to rise again ).

The difference and connection with lottery hypothesis
We also conducted the lottery hypothesis winning ticket A comparative experiment with re random initialization . Interestingly , In the double descent scenario , The initialization method of lottery hypothesis is not always better than the effect of network reinitialization .

▲ Initialization with lottery hypothesis (Lottery) And re random initialization (Reinit) Comparison of
As can be seen from the figure ,Reinit Compared with Lottery Global shift left , in other words Reinit The method is inferior to Lottery Of . This also verifies the idea of the lottery hypothesis on the other hand : Even if the structure of the model is exactly the same , From different initialization training , The performance of the model may also vary considerably .

Postscript
In the process of doing this research , We observed some magical 、 Counterintuitive experimental phenomena , And try to analyze and explain . However , The existing theoretical work cannot fully explain the reasons for these phenomena . For example, the accuracy of training is close 100% when , The test accuracy will gradually decline with pruning . Why does the model not forget the complex features in the data at this time , On the contrary, the noise is more seriously over fitted ?
We also observe that the learning distance of the model will first increase and then decrease with the increase of sparsity , Why does pruning lead to such changes in model learning distance ? And the double decline phenomenon of deep learning model often needs to increase the label noise on the input before it can be observed [2], What is the mechanism behind deciding whether the double dip occurs ?
There are still many unanswered questions . Now we are also carrying out a new theoretical work , In order to explain one or several of them . I hope we can get rid of the fog as soon as possible , Find out the essential reason behind this phenomenon .

Reference link
[1] Belkin, M., Hsu, D., Ma, S., & Mandal, S. (2018). Reconciling modern machine learning and the bias-variance trade-off.stat,1050, 28.
[2] Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B., & Sutskever, I. Deep double descent: Where bigger models and more data hurt. ICLR 2020.
[3] Frankle J., & Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. ICLR 2019.
[4] Hoefler, T., Alistarh, D., Ben-Nun, T., Dryden, N., & Peste, A. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. arXiv preprint arXiv:2102.00554, 2021.
[5] Bartoldson, B., Morcos, A. S., Barbu, A., and Erlebacher, G. The generalization-stability tradeoff in neural network pruning. NIPS, 2020.
[6] Nagarajan, V. and Kolter, J. Z. Generalization in deep networks: The role of distance from initialization. arXiv preprint arXiv:1901.01672, 2019.
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- Summary of server performance tuning experience
- [paper study] source mixing and separation robot audio steganography
- ICML 2022 | 稀疏双下降:网络剪枝也能加剧模型过拟合?
- Leetcode high frequency question: the array can be changed into a non descending state after at least several operations
- [cloud native] continuous integration and deployment (Jenkins)
- 剑指 Offer II 115. 重建序列 : 拓扑排序构造题
- Please initialize the log4j system properly.
- SharedPreferences数据储存
- 云原生(十一) | Kubernetes篇之Kubernetes原理与安装
- Exclusive interview | open source Summer Star Niu Xuewei
猜你喜欢

Software testing weekly (No. 81): what can resist negativity is not positivity, but concentration; What can resist anxiety is not comfort, but concrete.
Unity notes ilruntime access

Mysql—六大日志

After Effects 教程,如何在 After Effects 中创建动画?
![[paper study] source mixing and separation robot audio steganography](/img/e1/55e8f6a3e754d728fe6b685a08fdbc.png)
[paper study] source mixing and separation robot audio steganography

Comparison of functional characteristics and parameters of several solar panel battery charging management ICs cs5363, cs5350 and cs5328

Mysql客户端到服务端字符集的转换

2022 blue hat cup preliminary WP
CA数字证书

关于初始化page入参的设计思路

随机推荐
MySQL - six logs
手机使用多了可能会丢掉工作
JS filter / replace sensitive characters
来自大佬洗礼!2022头条首发纯手打MySQL高级进阶笔记,吃透P7有望
Harbor image warehouse
“1+1>10”:无代码/低代码与RPA技术的潜在结合
满足多种按键的高性价比、高抗干扰触摸IC:VK3606D、VK3610I、VK3618I 具有高电源电压抑制比
Mysql—六大日志
Go 接口:深入内部原理
关于初始化page入参的设计思路
Don't want dto set. Dto can be written like this
Php:filter pseudo protocol [bsidescf 2020]had a bad day
How to solve the problem of forgetting the Oracle password
MySQL - master-slave replication
[suctf 2018]multisql (MySQL precompiled)
Umijs - data transmission between main and sub applications of Qiankun
反转链表画图演示
上课作业(5)——#576. 饥饿的牛(hunger)
JSP之自定义jstl标签
Bean Validation核心组件篇----04