当前位置:网站首页>MapReduce execution principle record
MapReduce execution principle record
2022-06-26 03:52:00 【I love meat】
Mapreduce Basic principles this chapter omits
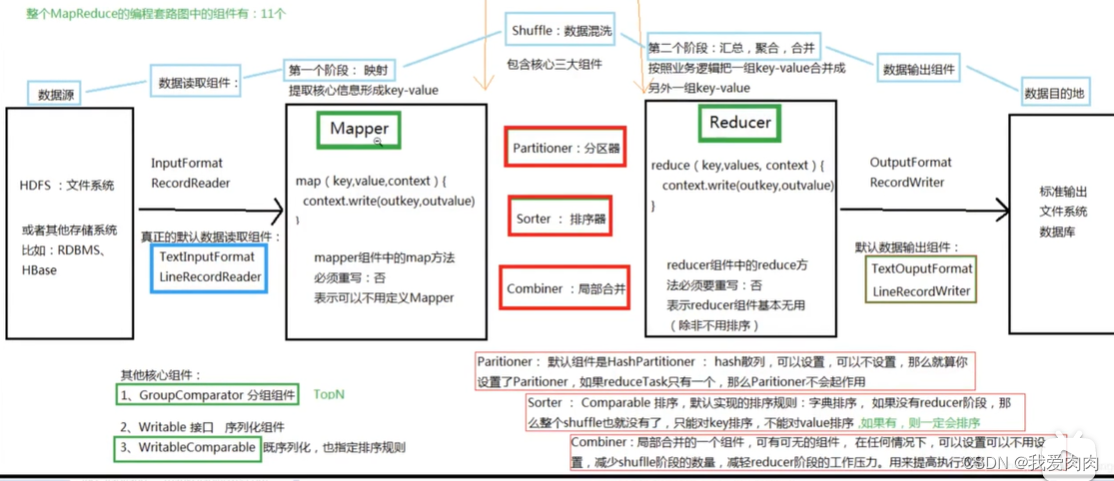

Some notes :
1 One file Slice multiple split, One split Corresponding to one Maptask. The same one map The output partition corresponds to a reducetask
2 map The data is written to the memory at full percent 80 when , Start writing data to disk . Don't stop when you reach the task , You can continue to write to both memory and disk at the same time .
If you haven't finished reading it all, you can't write it down 80, At this time, the disk file is also written but only written once
3 Most of the ( Not all )map It will start when the execution is completed reduce 了 ,
redcue Write to disk if memory is insufficient , Finally, it is merged into a large disk file to execute reduce Business logic
4 reduce Stage read map Output documents , It determines which data to read by reading the index file
5 Why Data sorting ->
because reduce Phases need to be grouped , take key The same is put together for the specification .map The phases are sorted together to reduce reduce Stage memory sort pressure .
For example, in the same partition reduce Aggregation operation , You only need to traverse one at a time key You can successfully aggregate . Out of order, you need to traverse all the files
6 map spill Three small files are merged into one large file
7 In the memory is the fast row , Merge files are grouped side by side
8 map End data has index file ,reduce There is no index file on the end , because reduce The end data is orderly
( in addition Spark Then for the case that is not a pre aggregation operator and the number of downstream partitions is very small , No memory sort , Improve performance )
Source version 2.7.7

Submit tasks
1 Client resolution MR Mission , Generate some necessary components : The startup script ,job.xml,jar package ( The submission is stored in HDFS In the temporary directory )
2 Submit a task to RM A proxy object , to RM Send an event program to submit the application . The event contains (jobid,submitDir)
3 RM Allocate one NodeManager Start the master program MRAppMaster,MRAppMaster Start assigning other NodeManger start-up YarnChild Program execution ,
MRAppMaster and YarnChild Keep in touch with each other ,
If all the programs are successfully executed, the main program will notify MR and client.MR Then release resources ,client The execution is judged to be successful
MRAppMaster amount to Spark Driver,YarnChild amount to Spark executor

Ring buffer
NodeManager Received MRAppMaster Start after command JVM process , from HDFS Pull various resources to execute MapTask/ReduceTask
Call partition component , to mapTask Output key-value Mark the partition , Write ring buffer ( Buffer zone 100mb, It has reached percent 80 Write to disk )
Default 100mb, With equator As a boundary , Write data on the right , Write fixed on the left 4 Byte data index .
When it is 100% 80, Start writing to disk , The memory is deleted every time the data falls on the disk .
When writing to disk , Re percent 20 Memory delimitation equator Continue writing memory , If the memory is full again , The disk is blocked before it is written , Up to percent 80 Restore when the disk is written .
MR A major reason for stability : Apply for memory only once and use it all the time , Will not keep applying for new memory space
Memory is only constantly overwritten with writes , There is no recycling
Before data is written to disk , Will be carried out in quicksort Quick sort , That's percent 80 In memory data location exchange
1 Sort by partition number first
2 In the partition , according to key Sort


Map Merge files

Reduce End shuffle
Reduce End
Memory is still 100mb, The threshold for triggering write to disk is 0.66, The available memory threshold is 0.7
Reading data , If key The same is placed in an intermediate container , Read on to the next key Different or not until next ( Because the data is orderly )

边栏推荐
- MapReduce执行原理记录
- Redux thunk simple case, advantages, disadvantages and thinking
- 优化——多目标规划
- 动态线段树leetcode.715
- Introduction of mybatis invalid
- 外包干了四年,人直接废了。。。
- Quanergy welcomes Lori sundberg as chief human resources officer
- An error occurred using the connection to database 'on server' 10.28.253.2‘
- ABP framework Practice Series (II) - Introduction to domain layer
- mysql存储过程
猜你喜欢
![MySQL advanced Chapter 1 (installing MySQL under Linux) [2]](/img/24/0795ebd2a0673d48c5e0f9d18842d1.png)
MySQL advanced Chapter 1 (installing MySQL under Linux) [2]

Open Camera异常分析(一)

开源!ViTAE模型再刷世界第一:COCO人体姿态估计新模型取得最高精度81.1AP
MySQL addition, deletion, query and modification (Advanced)

ABP framework Practice Series (I) - Introduction to persistence layer
![[Flink] Flink source code analysis - creation of jobgraph in batch mode](/img/8e/1190eec23169a4d2a06e1b03154d4f.jpg)
[Flink] Flink source code analysis - creation of jobgraph in batch mode

Slide the menu of uni app custom components left and right and click switch to select and display in the middle
Open camera anomaly analysis (I)

Analysis of camera memory memory leakage (II)

. Net core learning journey
随机推荐
判断两个集合的相同值 ||不同值
WebRTC系列-网络传输之6-Connections裁剪
Procédures stockées MySQL
Prism framework project application - Navigation
【好书集锦】从技术到产品
2022.6.24-----leetcode.515
Uni app custom navigation bar component
2020 summary: industrial software development under Internet thinking
Navicat16 wireless trial
2022.6.23-----leetcode.30
[Flink] Flink source code analysis - creation of jobgraph in batch mode
"Renegotiation" agreement
2022.6.25 - leetcode. Un doigt d'épée. 091.
Analysis of camera memory memory leakage (II)
Open source! Vitae model brushes the world's first again: the new coco human posture estimation model achieves the highest accuracy of 81.1ap
R语言与机器学习
bubble sort
JS to achieve the effect of text marquee
Run multiple main functions in the clion project
Ieda suddenly cannot find compact middle packages