当前位置:网站首页>MapReduce执行原理记录
MapReduce执行原理记录
2022-06-26 03:25:00 【我爱肉肉】
Mapreduce基础原理本篇略过
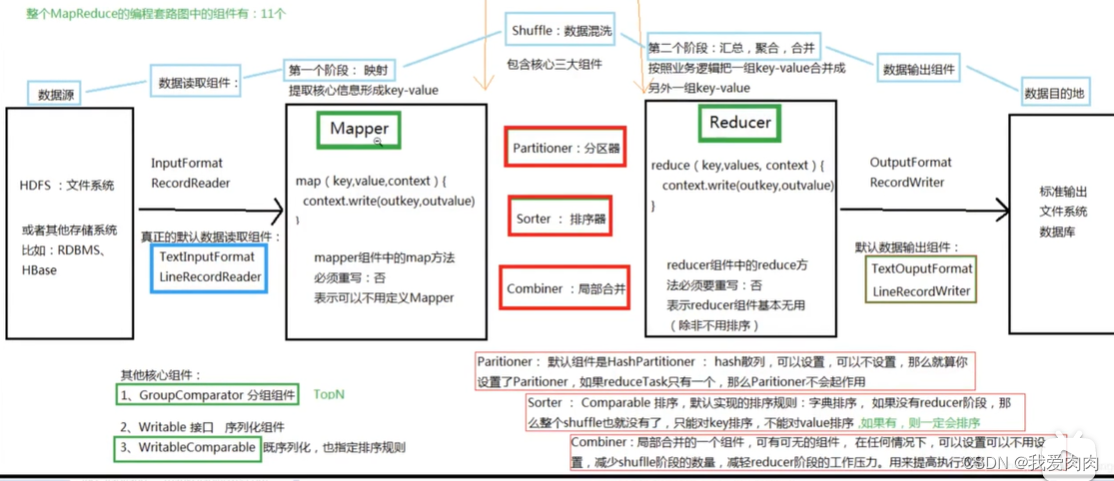

一些注意点:
1 一个file会切片多个split,一个split对应一个Maptask。同样一个map输出的分区对应一个reducetask
2 map数据写入内存满百分之80时,则开始数据写磁盘。达到任务不停止,可以同时继续写内存也写磁盘。
如果全部读完也没写满百分之80,则此时也写但只写入磁盘文件一次
3 大部分(不是所有)map执行完成时就会启动reduce了,
redcue内存不足则写磁盘,最后合并为一个大磁盘文件执行reduce业务逻辑
4 reduce阶段读取map产出的文件时,是通过读取索引文件确定读取哪些数据
5 Why 数据排序 ->
因为reduce阶段需要分组,将key相同的放在一起进行规约。map阶段一起排序减轻reduce阶段内存排序压力。
例如同一个分区内做reduce聚合操作,只需要一次顺序遍历一个key就可以成功聚合。乱序则需要遍历全部文件
6 map spill三个小文件时就会合并一次大文件
7 内存中是快排,合并文件是归并排
8 map端数据有索引文件,reduce端没有索引文件,因为reduce端数据都是有序的
(另外Spark则对不是预聚合算子且下游分区数量很小的情况下,则不会内存排序,提高性能)
源码版本2.7.7

提交任务
1 客户端解析MR任务,生成一些必要组件:启动脚本,job.xml,jar包(提交存放在HDFS临时目录中)
2 提交任务给RM一个代理对象,给RM发送一个事件程序提交了应用程序。事件中包含(jobid,submitDir)
3 RM分配一个NodeManager开启主控程序MRAppMaster,MRAppMaster启动分配其他NodeManger启动YarnChild程序执行,
MRAppMaster和YarnChild彼此互相保持心跳联系,
程序全部执行成功则主程序同时通知MR和client。MR则释放资源,client则判定执行成功
MRAppMaster相当于Spark Driver,YarnChild相当于Spark executor

环形缓冲区
NodeManager接收到MRAppMaster命令后启动JVM进程,从HDFS拉取各种资源执行MapTask/ReduceTask
调用分区组件,给mapTask输出的key-value打上分区标记,写入环形缓冲区(缓存区100mb,已满百分之80则写磁盘)
默认100mb,以equator为界,右边写数据,左边写固定4字节的数据索引。
当写满百分之80,开始写磁盘,数据每落完磁盘则删除内存。
写磁盘时,重新百分之20内存划定equator继续写内存,如果内存再次写满,而磁盘还没写完则阻塞,直到百分之80磁盘写完则恢复。
MR稳定的一大原因:只申请一次内存后一直使用,不会不停申请新内存空间
内存只有不断的覆盖写,没有垃圾回收
数据写磁盘前,会进行quicksort快速排序,也就是百分之80内存内数据位置的交换
1 先按照分区号排序
2 再分区内,按照key排序


Map合并文件

Reduce端shuffle
Reduce端
内存依然100mb,触发写磁盘阈值是0.66,可用内存阈值是0.7
读取数据中,如果key一样则放置一个中间容器中,一直读到下一个key不同或没有下一个为止(因为数据都是有序的)

边栏推荐
- Where is it safe to open a fund account?
- [hash table] a very simple zipper hash structure, so that the effect is too poor, there are too many conflicts, and the linked list is too long
- Kotlin uses viewpager2+fragment+bottomnavigationview to implement the style of the switching module of the bottom menu bar.
- After Ali failed to start his job in the interview, he was roast by the interviewer in the circle of friends (plug)
- View of MySQL
- Navicat16 wireless trial
- MySQL advanced Chapter 1 (installing MySQL under Linux) [2]
- String到底能不能改变?
- Uni app QR code scanning and identification function
- 解决uniapp插件robin-editor设置字体颜色和背景颜色报错的问题
猜你喜欢

When the tiflash function is pushed down, it must be known that it will become a tiflash contributor in ten minutes

评价——层次分析

计组笔记——CPU的指令流水

After Ali failed to start his job in the interview, he was roast by the interviewer in the circle of friends (plug)

MySQL开发环境

Classic model – RESNET

redux-thunk 简单案例,优缺点和思考
面试阿里测开岗失败后,被面试官在朋友圈吐槽了......(心塞)

How to prepare for a moving wedding
MySQL development environment
随机推荐
USB driver -debug
Some mobile phones open USB debugging, and the solution to installation failure
Uni app swiper rotation chart (full screen / card)
智能制造学习记录片和书籍
Group note data representation and operation check code
Prism framework
Various errors in kitti2bag installation
usb peripheral 驱动 - 枚举
Uni app custom drop-down selection list
MySQL开发环境
Where is it safe to open a fund account?
Nepal graph learning Chapter 3_ Multithreading completes 6000w+ relational data migration
2022.6.20-----leetcode. seven hundred and fifteen
Todolist incomplete, completed
Add an "open search description" to the site to adapt to the browser's "site search"“
WebRTC系列-网络传输之7-ICE补充之偏好(preference)与优先级(priority)
Kotlin uses viewpager2+fragment+bottomnavigationview to implement the style of the switching module of the bottom menu bar.
"Renegotiation" agreement
Request object, send request
链路监控 pinpoint