当前位置:网站首页>support vector machine
support vector machine
2022-06-21 10:33:00 【I'm afraid I'm not retarded】
Support vector machine (SVM)
Support vector machine SVM Introduce
What is support vector machine
So-called " Support vector " It refers to the training sample points at the edge of the interval area ,” machine “ Refers to the algorithm .
Is to find the spacing surface with the largest spacing , In fact, it solves the problem of optimal classifier design .
So the hyperplane is decided ( Hyperplane equation ) The key to your location , That is, some sample data with bits at the edge of the sample set .
Problem analysis :
- Purpose : Find an optimal classifier , In other words , Find a hyperplane , Maximize the classification interval
- Optimization of the Objective function : Classification interval . The classification interval needs to be maximized
- Optimization of the object : Classification hyperplane ( The decision plane ). By adjusting the position of the classification hyperplane , Maximize spacing , Achieve optimization goals
Related concepts of support vector machine
hyperplane
hyperplane (Hyperplane) yes n Codimension in a dimensional Euclidean space is equal to 1 The linear subspace of , It is a straight line in two-dimensional space , Three dimensional space is a two-dimensional plane .
In other words, it is easier to understand : One n Space of dimension , Its hyperplane is a n-1 Space of dimension .
interval
The interval is actually twice the vertical distance from the point corresponding to the support vector to the classification hyperplane , That is to say :W = 2d
optimization problem
To find the support vector ( That is, the sample points on the hyperplane corresponding to the dotted line ), The distance from the support vector to the classification decision surface is required d Maximum , That is, it can meet the requirements of the optimal classifier ( For linearly separable records ).
Find a set of variables ω,γ Make interval W = 2d Maximum .
Kernel functions and relaxation variables
In the case of linear indivisibility
In the case of linear nonseparable, we can no longer directly use the previously obtained linearly separable hyperplane , Instead, consider mapping the sample to a higher dimensional space , We hope to be linearly separable in this high dimensional space , You can use the idea of linear separability , Construct a classification hyperplane .
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-JXgxoRzl-1626877649260)(D:\QianFeng\ Blog \ machine learning \ Alibaba cloud classroom \ Detailed explanation of machine learning algorithm \image- Linear nonseparable mapping .png)]
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2lhqr3dy-1626877649264)(D:\QianFeng\ Blog \ machine learning \ Alibaba cloud classroom \ Detailed explanation of machine learning algorithm \imag- Linear nonseparable mapping 2.png)]
( Theoretically ) If the original space is finite , That is, the number of attributes is limited , There must be a high dimensional special space to make the samples linearly separable .
Kernel function
Support vector machine through a nonlinear change Φ(x), Map the input space to the high-dimensional feature space . If only the inner product operation is used to solve the support vector machine , And there is a function in the low dimensional output space K(x,x’), He happens to be equal to this inner product in high-dimensional space , namely K(x,x') = <Φ(x).Φ(x')>, Then there is no need to calculate the complex nonlinear transformation , By function K(x,x’) The inner product of nonlinear variation is obtained directly , simplified calculation . function K(x,x') be called Kernel function
Classification and selection of kernel functions
Common kernel function types
- Linear Kernel: Linear kernel
- Polynomial Kernel: Polynomial kernel
- Gaussian radial basis Kernel(RBF): Gaussian radial basis kernel
- Sigmoid Kernel
Select kernel function :
- There are no clear and workable guidelines
- Select kernel function by prior knowledge
- Using cross validation , Try different kernels , Choose the one with the least error
- Mixed kernel function method , Mix different kernel functions to use
- The most common is RBF, The second is the linear kernel
Linear indivisibility caused by outliers
The linearly nonseparable samples are mapped to a high dimensional space , The probability of finding the classification hyperplane is greatly increased . There may still be some situations that are difficult to deal with , For example, the structure of the sample data itself is not nonlinear , However, due to the noise, some points far away from the normal position ( Outliers Ourlier) May have a great impact on the model .( Outliers affect the classification hyperplane )
Relax variables ( How to deal with outliers that affect the classification hyperplane )
Because we need to consider outliers , Constraints should be appropriately relaxed .
SVM Many classification
SVM It is designed for binary classification problems , However, the multi classification problem can be realized by constructing appropriate multi classifiers :
direct method : Modify the objective function directly , The parameter solution of multiple classification surfaces is combined into an optimization problem .
indirect method : By effectively combining multiple dichotomies SVM classifier , So as to realize multi classification .
One to many : Divide the samples into certain types of samples and other types of samples , Train to get K individual SVM, Classify the unknown samples into the class with the largest classification function value
- advantage : Training K individual SVM, The number of less , Fast classification
- shortcoming : All samples for each training , And the number of negative samples is much larger than that of positive samples , Adding new categories requires retraining all models
One on one : Design one for any two samples SVM, need
k(k-1)/2A classifier , When classifying an unknown sample , Take the category that gets the most votes among all classifiers .- advantage : You don't need to train all the models , Just focus on the new model
- shortcoming : Too many models , Training 、 The prediction time is quite long .
When classifying an unknown sample , Take the category that gets the most votes among all classifiers .
- advantage : You don't need to train all the models , Just focus on the new model
- shortcoming : Too many models , Training 、 The prediction time is quite long .
边栏推荐
- The bilingual live broadcast of Oriental selection is popular, and the transformation of New Oriental is beginning to take shape
- 触摸按键控制器TTP229-BSF使用心得[原创cnblogs.com/helesheng]
- 从零开始做网站10-后台管理系统开发
- 一行代码加速 sklearn 运算上千倍
- 领导:谁再用redis过期监听实现关闭订单,立马滚蛋!
- TC software outline design document (mobile group control)
- 获取配置文件properties中的数据
- 应用配置管理,基础原理分析
- About Alipay - my savings plan - interest rate calculation instructions
- 中部“第一城”,网安长沙以何安网?
猜你喜欢

Classification of ram and ROM storage media

ESP8266/ESP32 +1.3“ or 0.96“ IIC OLED指针式时钟

Celsius 的暴雷,会是加密领域的“雷曼时刻”吗?

一行代码加速 sklearn 运算上千倍

Brief introduction of quality control conditions before genotype filling

DSP gossip: how to save the compiled variables on the chip when the variables are defined in the code
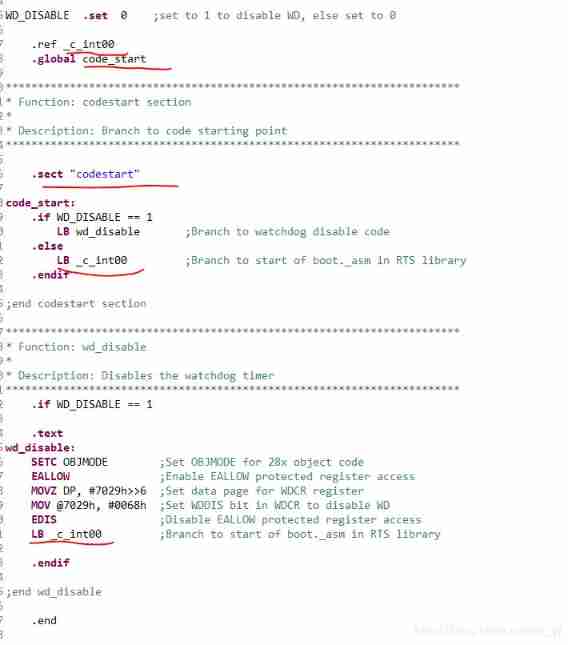
DSP online upgrade (1) -- understand the startup process of DSP chip

应用配置管理,基础原理分析

使用shapeit进行单倍型分析

108. detailed use of Redux (case)
随机推荐
从零开始做网站11-博客开发
ES复合查询工作量评估
知识点滴 - 什么是加速移动网页(AMP)?
[cloud native | kubernetes] kubernetes configuration (XV)
中国国际电子商务中心与易观分析联合发布:2021年4季度全国网络零售发展指数同比增长0.6%
Embedded software project process and project startup instructions (example)
Definition of annotations and annotation compiler
js正则-梳理
程序员新人周一优化一行代码,周三被劝退?
leetcode:715. Range 模块【无脑segmentTree】
JS regular - comb
Eig and Saudi Aramco signed a memorandum of understanding to expand energy cooperation
109. use of usereducer in hooks (counter case)
AI越进化越跟人类大脑像!Meta找到了机器的“前额叶皮层”,AI学者和神经科学家都惊了...
聊聊大火的多模态项目
从零开始做网站10-后台管理系统开发
Classification of ram and ROM storage media
Odd number of characters exception
ArCore支持的設備
Ccs7.3 how to erase only part of the flash sector when burning DSP on-chip flash (two projects of on-chip flash burning of a DSP chip)