当前位置:网站首页>Data management: business data cleaning and implementation scheme
Data management: business data cleaning and implementation scheme
2022-06-24 00:40:00 【A cicada smiles】
One 、 Business background
In the process of system business development , We all face such a problem : Facing the rapid expansion of business , Many versions didn't have time to consider the overall situation at that time , As a result, many business data storage and management are not standardized , For example, common problems :
- The address is entered , Instead of three levels of linkage ;
- There is no unified management data dictionary access interface ;
- The location and structure of data storage are unreasonable ;
- There are synchronization channels between databases of different services ;
And the analysis business usually has to face the global data , If there are a lot of the above , It will make the data very difficult to use , And then there will be a lot of problems : Data dispersion is not standardized , This leads to poor response performance , Low stability , At the same time, increase management costs .
As the business grows , The precipitation of data is more and more , It will be more difficult to use , Before data analysis , It takes a lot of time to clean the data .
Two 、 Overview of data cleaning
1、 Basic plan

The core idea :
- read - wash - Write business library continuous service ;
- read - wash - Write to archive data asset library ;
Business data cleaning is not hard to understand in essence , That is to read the data source to be cleaned , After standardized cleaning service , Then put the data to the specified data source , But the actual operation is absolutely dazzling .
2、 Container migration
The way data is stored is itself a variety of options , The first problem with cleaning data is : Migration of data containers ;
- Read data source : file 、 cache 、 Database etc. ;
- Temporary container : Cleaning process stores node data ;
- Write data source : The container for data injection after cleaning ;
So the first step of cleaning data is to determine how many data sources to adapt to the whole process , Do a good job in the basic function design and architecture of services , This is the foundation of the cleaning service ;
3、 Structured management
The cleaning data read may not be structured data based on library table management , Or in the process of data processing in the intermediate temporary container storage , In order to facilitate the next operation to get the data , We need to do simple structure management for data ;
for example : Generally, the service performance of reading files is very poor , When the data is read, in the process of cleaning , Once the process breaks down , You may need to reread the data , At this point, it is unreasonable to read the file again , Once the data in the file is read out , It should be converted to a simple structure and stored in a temporary container , Easy to get again , Avoid revisiting the process of processing files IO flow ;
Several business scenarios of common data structure management :
- Data container replacement , Need to restructure ;
- Dirty data structure deletion or multi field merging ;
- File data (Json、Xml etc. ) Turn the structure ;
Be careful : The structure management here may not be a simple library table structure , It could also be based on library table storage JSON Structure or something , Mainly to facilitate the use of cleaning process , And the writing of the final data .
4、 Standardized content
Standardized content is the basic principle of data cleaning service , Or some business norms , This one is completely determined by demand , It also involves some basic methods of cleaning data ;
In terms of the needs of the business itself , Several common cleaning strategies may be as follows :
Unified management based on dictionary : For example, common address entry , If value
Pudong New Area XX road XX District, So it's going to be cleaned forShanghai - Pudong New Area -XX road XX District, This kind of region must be based on dictionary management table , In fact, in the system, many field attributes are based on the dictionary to manage the value boundary and specification , This is good for the use of data 、 Search for 、 Analysis etc. ;Data analysis archives : For example, user real name authentication is required in a certain business module , If the authentication is successful , Based on cell phone number + The user information read by the ID card changes very little , In particular, the relevant data based on ID number decomposition , These data can be used as user profile data , Do data asset management ;
Business data restructuring : Generally, analysis is based on global data , This involves the management of data separation and combination , In this way, some data structures may need to be moved , Or merge data structures in different business scenarios , This is an overall analysis , It's easier to capture valuable information data ;
But for data cleaning itself , There are also some basic strategies :
- The growth of Data Infrastructure 、 Delete 、 Merger, etc ;
- The transformation of data types , Or length processing ;
- Numerical transformation in data analysis 、 Missing data make up or discard ;
- Normalization of the data value itself , Repair, etc ;
- Unified string 、 date 、 Time stamp and other formats ;
There is no standardized specification in the strategy of data cleaning , It all depends on the business requirements after data cleaning , For example, poor data quality , If it is seriously missing, it may be discarded directly , It may also be based on a variety of strategies to make up for , It all depends on the application scenario of the result data .
3、 ... and 、 Service Architecture
1、 foundation design
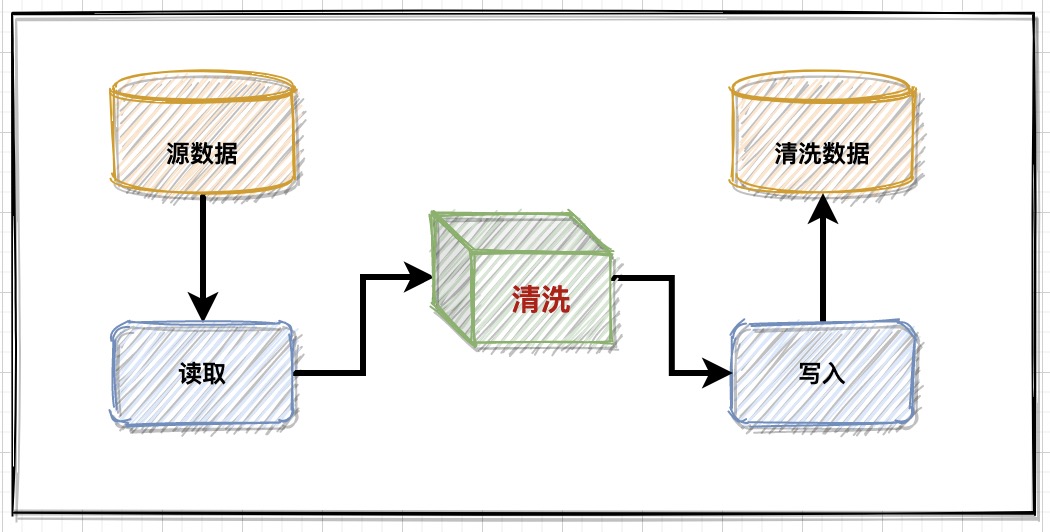
Usually in data cleaning services , It's about reading data - wash - Write the basic link to do the architecture , There's no complicated logic in each scenario itself :
Data source read
Data source reading is one of the two key problems : adapter , Different storage methods , To develop different reading mechanisms ;
- database :MySQL、Oracle etc. ;
- File type :XML、CSV、Excel etc. ;
- middleware :Redis、ES Index, etc. ;
Another key issue is data reading rules : It's about reading speed , size , Successively, etc ;
- If the data file is too large, it may need to be cut ;
- If there is time sequence between data , Read in sequence ;
- According to the cleaning service capacity , Evaluate read size ;
2、 Interaction between services
In fact, how services interact , How to manage the flow rules of data on the whole cleaning link , It needs to be considered according to the throughput of different service roles , The basic interaction logic is two : Direct adjustment 、 asynchronous ;

Direct adjustment : If the processing capacity of each service node is the same , It can be adjusted directly , This way, the process is relatively simple , And it can catch the exception for the first time , Make corresponding compensation treatment , But in fact, the cleaning service has a lot of rules to deal with , Naturally, it takes a lot of time ;
asynchronous : Each service is decoupled , Through asynchronous way to promote each node service execution , For example, after reading the data , Call the cleaning service asynchronously , When the data cleaning is complete , Call the data write service asynchronously , At the same time, inform the data reading service to read the data again , In this way, there is a gap between the resources of each service , Reduce service pressure , In order to improve efficiency, we can do some preprocessing in different services , This kind of process design is more reasonable , But the complexity is high .
Data cleaning is a meticulous and energy consuming work , According to different needs , Continuous optimization of services and precipitation of common functions .
3、 Process management
It is necessary to manage the data cleaning process , There are usually two things to consider : Node status 、 Node data ;

Cleaning nodes : This is the key record node , If there are too many cleaning rules , Batch processing , It is particularly important to record the data and status of each key process after successful processing ;
Reading and writing node : Selective storage according to data source type , For example, file type ;
Forwarding node : Record forwarding status , Common success or failure states ;
For the key node result record , It can quickly execute the retrial mechanism when the cleaning link fails , Which node is abnormal , You can quickly build re executed data , For example, reading files A The data of , But the cleaning process failed , Then you can quickly try again based on the data record of the read node ;
If the amount of data is too large , You can delete the successful data periodically , Or directly notify the deletion after the data is successfully written , Reduce the excessive occupation of resources by the maintenance and cleaning link itself .
4、 Instrumental precipitation
In the link of data cleaning , You can continuously precipitate and extend some tool code :
- Data source adaptation , Common libraries and file types ;
- Document cutting , Processing of large files ;
- Transforming unstructured data into structured table data ;
- Data type conversion and verification mechanism ;
- Concurrent pattern design , Multithreading ;
- Cleaning rules policy configuration , Dictionary data management ;
It is difficult to generalize the business and rules of data cleaning , But the architecture design of cleaning service , It is necessary to encapsulate and precipitate the tools in the link , So that you can focus your time and energy on the business itself , In this way, facing different business scenarios , It can be faster and more efficient .
5、 Link test
The link of data cleaning is relatively long , So it is necessary to test the link , Basically, it can be tested from two extremes :
- defect : All missing except unnecessary data ;
- complete : All data property values exist ;
These two scenarios are to verify the availability and accuracy of the cleaning link , Reduce the possibility of an exception .

Read the label
【Java Basics 】【 Design patterns 】【 Structure and algorithm 】【Linux System 】【 database 】
【 Distributed architecture 】【 Microservices 】【 Big data components 】【SpringBoot Advanced 】【Spring&Boot Basics 】
【 Data analysis 】【 Technology map 】【 In the workplace 】
边栏推荐
- Andorid 开发艺术探索笔记(2),跨平台小程序开发框架
- Shutter control layout
- Android AIDL:跨进程调用Service (AIDL Service),kotlininvoke函数
- 【第25天】给定一个长度为 n 的数组,统计每个数出现的次数 | 计数哈希
- Detailed process from CPU fetching to sending control and microprogram control principle
- Shuttle global levitation button
- skywalking 安装部署实践
- Vulnerability recurrence - redis vulnerability summary
- Android 3年外包工面试笔记,有机会还是要去大厂学习提升,作为一个Android程序员
- Index principle and filling factor in database
猜你喜欢

苹果Iphone14搭载北斗导航系统,北斗VS GPS有哪些优势?

Accompanist组件库中文指南 - Glide篇,劲爆
![[digital signal] spectrum refinement based on MATLAB analog window function [including Matlab source code 1906]](/img/b3/ad289400e9c74f6f1f533a7d560d5c.jpg)
[digital signal] spectrum refinement based on MATLAB analog window function [including Matlab source code 1906]

Revit API: schedule viewschedule
Detailed process from CPU fetching to sending control and microprogram control principle

How to write peer-reviewed papers

【小程序】实现双列商品效果

C语言:关于矩阵右移问题
![[image detection saliency map] calculation of fish eye saliency map based on MATLAB distortion prompt [including Matlab source code 1903]](/img/36/134c573c2198ca6c88a7c179189f1a.jpg)
[image detection saliency map] calculation of fish eye saliency map based on MATLAB distortion prompt [including Matlab source code 1903]

牛学长周年庆活动:软件大促限时抢,注册码免费送!
随机推荐
【小程序】相对路径和绝对路径的表示符
[technique of planting grass] spit blood and clean up, and take you to collect goose feathers in a fancy way! Do not spread!!!
【ICPR 2021】遥感图中的密集小目标检测:Tiny Object Detection in Aerial Images
C语言:百马百担问题求驮法
Kitten paw: FOC control 15-mras method of PMSM
C language: sorting with custom functions
苹果Iphone14搭载北斗导航系统,北斗VS GPS有哪些优势?
Android 7,2021最新Android面试笔试题目分享
阿里巴巴面试题:多线程相关
Android AIDL:跨进程调用Service (AIDL Service),kotlininvoke函数
Interview notes for Android outsourcing workers for 3 years. I still need to go to a large factory to learn and improve. As an Android programmer
纯js实现判断ip是否ping通
Experience summary of 9 Android interviews, bytes received, Ali, advanced Android interview answer
Shutter control layout
同行评议论文怎么写
Android 3年外包工面试笔记,有机会还是要去大厂学习提升,作为一个Android程序员
Is it safe to open an account for shares of tongdaxin?
Google Earth engine (GEE) - verification results used by NDVI, NDWI and NDBI to increase classification accuracy (random forest and cart classification)
小猫爪:PMSM之FOC控制15-MRAS法
Is it safe to open an account online? What conditions need to be met?