当前位置:网站首页>Stored procedure writing experience and optimization measures
Stored procedure writing experience and optimization measures
2022-08-05 07:27:00 【51CTO】
1. Suitable for readers: database development programmers, the database has a lot of data, project developers who are involved in the optimization of SP (stored procedure), and have a strong interest in the databasepeople.
2. Introduction: In the process of database development, complex business logic and database operations are often encountered. At this time, SP will be used to encapsulate database operations.If there are many SPs in the project and there is no certain specification for writing, it will affect the difficulty of system maintenance in the future and the incomprehension of the logic of large SPs. In addition, if the amount of data in the database is large or the project has high performance requirements for SPs, you will encounterOptimization problem, otherwise the speed may be very slow. After personal experience, an optimized SP is even hundreds of times more efficient than a poor SP.
3. Contents:
1. If developers use Table or View of other libraries, they must create a View in the current library to realize cross-library operations. It is best not to use "databse" directly.dbo.table_name", because sp_depends cannot display the cross-database table or view used by the SP, which is not convenient for verification.
2. Before submitting the SP, developers must have used set showplan on to analyze the query plan and have done their own query optimization checks.
3. For high program running efficiency and application program optimization, the following points should be paid attention to in the process of SP writing:
a) SQL usage specification:
i. Try as much as possibleAvoid large transaction operations and use the holdlock clause with caution to improve system concurrency.
ii. Try to avoid repeatedly accessing the same table or tables, especially tables with a large amount of data, you can consider extracting data into temporary tables based on conditions, and then making connections.
iii. Try to avoid using the cursor, because the efficiency of the cursor is poor, if the data operated by the cursor exceeds 10,000 rows, it should be rewritten; if the cursor is used, try to avoid doing it again in the cursor loopOperations on table joins.
iv. Pay attention to the writing of the where clause. The order of the statement must be considered. The order of the conditional clauses should be determined according to the index order and range size, and the field order should be consistent with the index order as much as possible.Small.
v. Do not perform functions, arithmetic operations or other expression operations on the left side of the "=" in the where clause, otherwise the system may not be able to use the index correctly.
vi. Try to use exists instead of select count(1) to determine whether there is a record. The count function is only used to count all the rows in the table, and count(1) is more efficient than count(*).
vii. Try to use ">=" instead of ">".
viii. Pay attention to the substitution between some or clauses and union clauses.
ix. Pay attention to the data types of joins between tables, and avoid joins between different types of data.
x. Note the relationship between parameters and data types in stored procedures.
xi. Pay attention to the data volume of insert and update operations to prevent conflicts with other applications.If the amount of data exceeds 200 data pages (400k), the system will perform lock escalation, and page-level locks will be upgraded to table-level locks.
b) Specifications for the use of indexes:
i. The creation of indexes should be considered in conjunction with the application. It is recommended that large OLTP tables do not have more than 6 indexes.
ii. Use index fields as query conditions as much as possible, especially clustered indexes. If necessary, index index_name can be used to force the specified index.
iii. Avoid table query when querying large tablesscan, and consider creating an index if necessary.
iv. When using an index field as a condition, if the index is a joint index, the first field in the index must be used as a condition to ensure that the system can use the index, otherwise the index will not be used.will be used.
v. Pay attention to the maintenance of the index, rebuild the index periodically, and recompile the stored procedure.
c) The usage specification of tempdb:
i. Try to avoid using distinct, order by, group by, having, join, and cumpute, because these statements will increase the burden of tempdb.
ii. Avoid frequent creation and deletion of temporary tables and reduce the consumption of system table resources.
iii. When creating a new temporary table, if a large amount of data is inserted at one time, select into can be used instead of create table to avoid logging and improve the speed; if the amount of data is not large, in order to ease the resources of the system table, it is recommended to create table first, and then insert.
iv. If the amount of data in the temporary table is large and an index needs to be established, the process of creating the temporary table and indexing should be placed in a separate sub-stored procedure, so as to ensure that the system can be used wellAn index into this temporary table.
v. If temporary tables are used, all temporary tables must be explicitly deleted at the end of the stored procedure, first truncate table, and then drop table, which can avoid long-time locking of system tables.
vi. Carefully use the connection query and modification of large temporary tables and other large tables to reduce the burden of system tables, because such operations will use tempdb system tables multiple times in one statement.
d) Reasonable use of algorithms:
According to the SQL optimization technology mentioned above and the SQL optimization content in the ASE Tuning manual, combined with practical applications, a variety of algorithms are used to compare, andGet the least resource-intensive, most efficient method.Specific ASE tuning commands can be used: set statistics io on, set statistics time on , set showplan on, etc.
边栏推荐
猜你喜欢
TRACE32——C源码关联1

图扑软件与华为云共同构建新型智慧工厂
爬虫之验证码
DeFi 前景展望:概览主流 DeFi 协议二季度进展
Mysql 死锁和死锁的解决方案
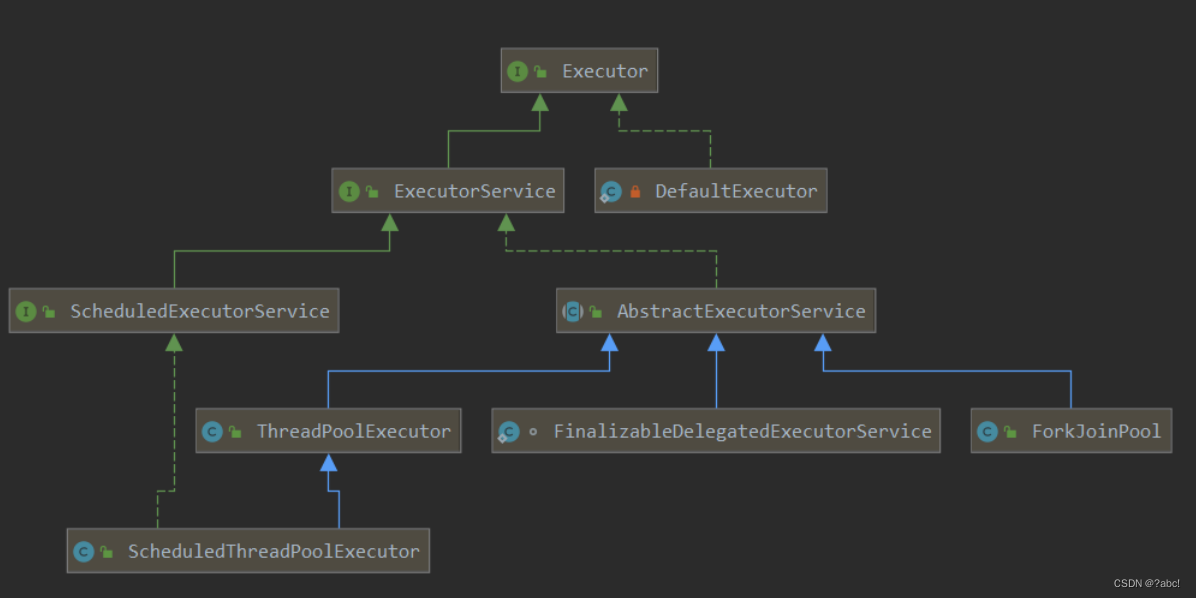
线程池的使用(结合Future/Callable使用)
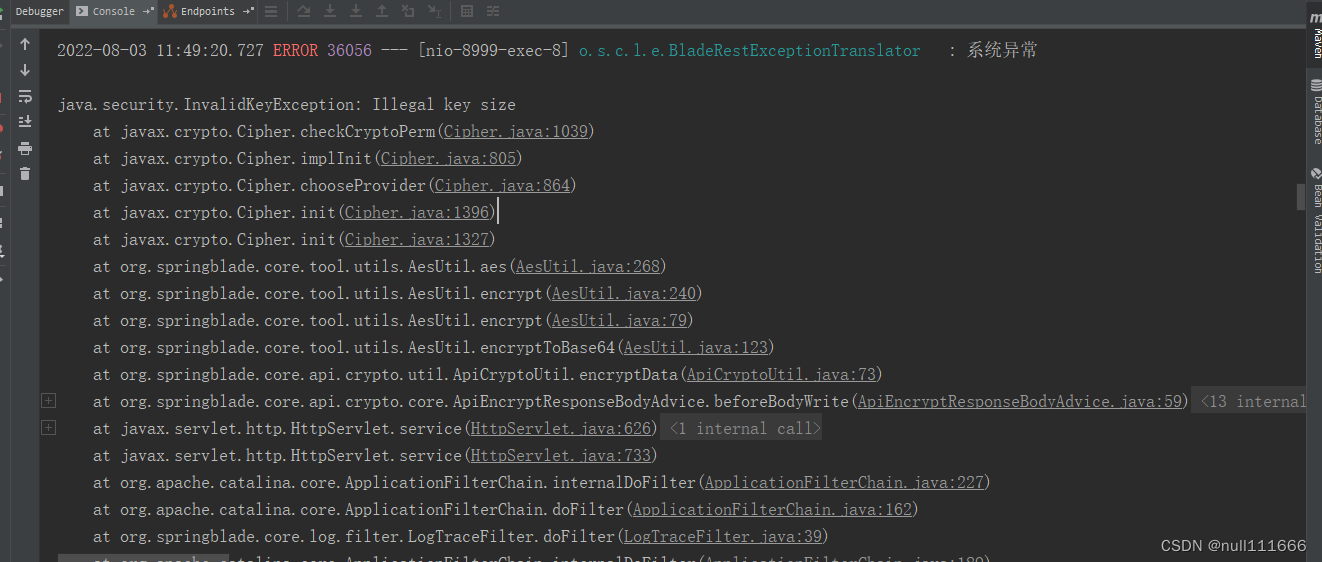
Illegal key size 报错问题
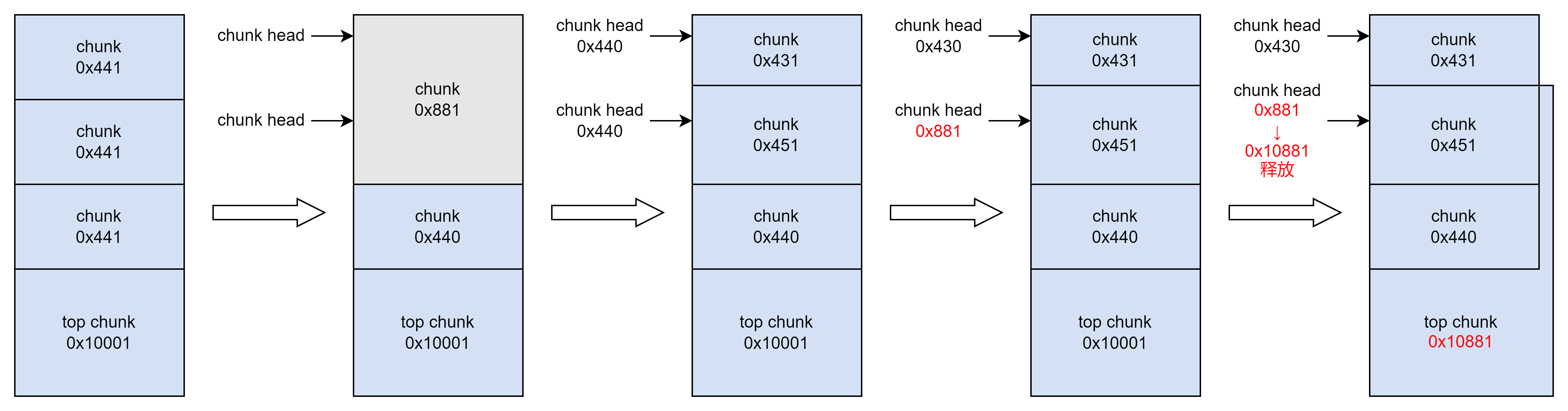
强网杯2022 pwn 赛题解析——house_of_cat

2022熔化焊接与热切割操作证考试题及模拟考试
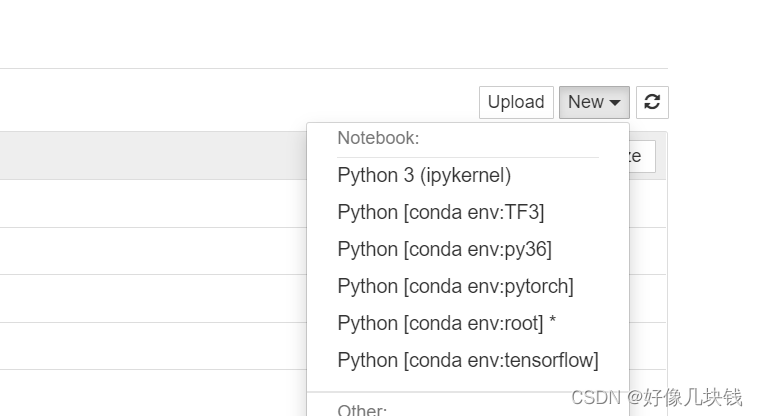
In the anaconda Promat interface, import torch is passed, and the error is reported in the jupyter notebook (only provide ideas and understanding!)
随机推荐
cmake 学习使用笔记(三)
Chapter3、色调映射
【win7】NtWaitForKeyedEvent
向美国人学习“如何快乐”
栈与队列的基本介绍和创建、销毁、出入、计算元素数量、查看元素等功能的c语言实现,以及栈的压入、弹出序列判断,栈结构的链式表示与实现
After working for 3 years, I recalled the comparison between the past and the present when I first started, and joked about my testing career
Tencent Internship Summary
Summary of Text Characterization Methods
2022熔化焊接与热切割操作证考试题及模拟考试
Hash these knowledge you should also know
"Automatic Data Collection Based on R Language"--Chapter 3 XML and JSON
php向mysql写入数据失败
【动态类型检测 Objective-C】
【instancetype类型 Objective-C】
moment的使用
标准C语言15
[上海]招聘.Net高级软件工程师&BI数据仓库工程师(急)
C# FileSystemWatcher
2022.8.2 模拟赛
Algorithm Supplements Fifteen Complementary Linked List Related Interview Questions