当前位置:网站首页>Principle understanding and application of hash table and consistent hash
Principle understanding and application of hash table and consistent hash
2022-07-27 03:43:00 【Aries_ Ro】
hash Table consistency hash
Here's the catalog title
Hashtable
Hashtable (hash) Also known as hash table, it is a data structure , According to key Calculation key Position in the table ; yes key Mapping relationship with the storage address ( Such as :Hash(key)=address) .
In the node of the hash table key and value Is stored together ; As shown below
struct node {
void *key;
void *val;
struct node *next;
};
The hash table has several factors :hash function 、 Load factor
hash function
hash A function is a mapping relationship of addresses Hash(key)=address ;
however hash The function may put two or more different key Map to the same address , This situation is called Hash Collisions ( perhaps hash Collision );
Several classic hash function :
murmurhash1,murmurhash2,murmurhash3,siphash( redis6.0 Use of ,rust And most languages siphash Algorithm to achieve hashmap ),cityhash All have Strong random distribution ;
Load factor
Load factor Is to describe hash Conflict The intensity of .
Load factor =( The number of elements stored in the array / Data length ); Used to describe the storage density of hash tables ;
The smaller the load factor , The less conflict , The greater the load factor , The greater the conflict ;
Conflict handling
The linked list method
Linked list method is to use conflict elements Linked list link ; This is also a common way to deal with conflicts .
But there may be an extreme case , There are many conflict elements , The The conflict list is too long , The time complexity of finding data also becomes higher .
At this time, you can convert this linked list into Red and black trees 、 The smallest pile ; From the time complexity of the original linked list to the time complexity of the red black tree ;
Open addressing
Open addressing method is to store all elements in the array of hash table ,** No additional data structures ;** Generally used Linear probe How to solve this problem ;
- When inserting a new element , Use hash function to locate element position in hash table ;
- Check whether there is an element in the slot index in the array . If the slot is empty , The insert , otherwise 3;
- stay The first 2 Add a certain step length to the slot index of step detection, and then check ; Add a certain step length and divide into the following :
i+1,i+2,i+3,i+4, … ,i+n
i- 1 2 {1}^{2} 12,i+ 2 2 {2}^{2} 22 ,i- 3 2 {3}^{2} 32,1+ 4 2 {4}^{2} 42, … These two methods can temporarily resolve hash conflicts , But it will lead to similar hash Gather ; That is, the approximate value of its hash The value is also approximate , Then its array slot is also close to , formation hash Gather ; The first kind of congeneric aggregation conflict comes first , The second is simply to postpone the gathering conflict ; have access to Double hash To solve the problems above hash Aggregation phenomenon :
STL Application of hash table in
stay STL in unordered_map 、unordered_set 、unordered_multimap
、unordered_multiset The underlying implementation of the four data structures is Hashtable ;
Different from ordinary hash tables :
Ordinary hash table : There will be a linked list on a hash value
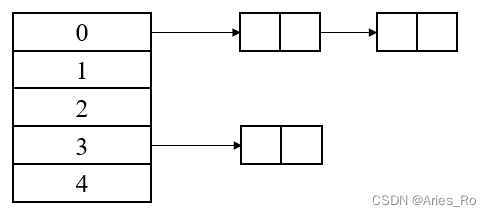
STL Medium “ Hashtable ”

STL The open chain method is also used to solve hash Conflict , But it is not a hash value, a linked list , It is Whole hash Table is A linked list ( It should be for better implementation STL Iterators in , Only then has this kind of structure ). Inserting a new data will adopt the chain header interpolation , If the sending hash conflicts, the linked list will be used to insert data into the node .
Hashtable VS Binary tree
Both hash table and balanced binary tree can query whether a string exists from massive data .
The time complexity of adding, deleting, modifying and checking balanced binary tree is O(logn) ; namely 100 Ten thousand nodes , Compare at most 20 Time ;10 Billion nodes , Compare at most 30 Time ;
The purpose of balance is to add, delete and modify , Ensure that the next search can stably eliminate half of the data ;
summary : Balanced binary tree through node comparison , Both guarantee Orderly , You can also exclude half of the elements each time to achieve the purpose of rapid indexing ; The lookup time complexity of hash table is O(1), But the order of data cannot be guaranteed . So both have their own advantages and disadvantages .
Distributed consistency hash
background : Distributed consistency hash The algorithm organizes the hash space into a Virtual ring , The number of nodes of the ring is 2 32 {2}^{32} 232;
Algorithm for : hash(ip) % 2 32 {2}^{32} 232, In the end, you'll get one [0, 2 32 {2}^{32} 232-1] An unsigned integer between , This integer represents the number of the server ; Multiple servers are running in this way hash Map a point on the ring to identify the location of the server ; When a user operates a key, Generate a value by the same algorithm , Position a server clockwise along the ring , Then the key In this server .
As shown in the figure :

In the figure, we first pass hash(ip) %( 2 32 {2}^{32} 232) Calculate the location of four servers , Re pass hash(ip) %( 2 32 {2}^{32} 232) Calculate the user's location . For example, users 1 Where “ Yellow dot ”, Look for the nearest server clockwise 3, Then the user 1 Of key There are servers 3 in . Similarly, users 2 There are servers 2 in .
Application scenarios
Distribute data evenly among different servers , To share the pressure of the cache server ;
The change in the number of cache servers should not affect cache invalidation ;
Hash offset
The result of hash algorithm is random , There is no guarantee that the server nodes are evenly distributed over the hash ring , This is it. Hash offset ;
Uneven distribution will cause uneven request access , This leads to uneven pressure on the server ; As shown in the figure :

Many users are saved on the server 1 in , The server 1 The pressure . And the server 3 It may be easier .
To solve the problem of hash offset , Introduced Virtual node The concept of .
Virtual node
Theoretically , The more nodes on the hash ring , The more evenly distributed the data ; To solve the problem of hash offset , Multiple hash nodes can be calculated for each service node ( The new hash node is the virtual node );
The usual way is , hash(“IP:PORT:seqno”)%( 2 32 {2}^{32} 232) ; For example, put the above server 3 Add several virtual nodes ( The new virtual nodes will also be randomly distributed on the hash ring , Not necessarily with service 3 adjacent ), Add servers 3 The amount of work , Thus, the server 1 The amount of work .
Delete and add nodes
Suppose you delete the server 2, It was originally stored on the server 2 Users of 2, It will be taken out and found the server clockwise again 1 node , Save on the server 1 in .

If you add a server node , The added server node will be found counterclockwise to all user nodes between the previous server and saved in the new server node .
边栏推荐
- 【树链剖分】2022杭电多校2 1001 Static Query on Tree
- Vector to SVG method
- Wechat applet generation Excel
- The diagram of user login verification process is well written!
- 【常用搜索问题】111
- Network security / penetration testing tool awvs14.9 download / tutorial / installation tutorial
- Characteristics and experimental suggestions of abbkine abfluor 488 cell apoptosis detection kit
- Permutation and binary (Ji, DA) (day 84)
- Indexing best practices
- easyui中textbox在光标位置插入内容
猜你喜欢

基于OpenCV的轮廓检测(1)
flask_restful中reqparse解析器继承

redis秒杀案例,跟着b站尚硅谷老师学习

【无标题】JDBC连接数据库读超时

【1206. 设计跳表】

The application and significance of digital twins are the main role and conceptual value of electric power.

Vector to SVG method

MySQL has a nonexistent error

关于使用hyperbeach出现/bin/sh: 1: packr2: not found的解决方案
Graphic SQL, this is too vivid!
随机推荐
Volatile keyword and its function
JMeter distributed pressure measurement
flask_restful中reqparse解析器继承
MySQL has a nonexistent error
Contour detection based on OpenCV (1)
数字孪生应用及意义对电力的主要作用,概念价值。
DNS record type and explanation of related terms
Safe-arc/warner power supply maintenance xenon lamp power supply maintenance analysis
Take you to know what Web3.0 is
MySQL underlying data structure
Database usage security policy
Permutation and binary (Ji, DA) (day 84)
一种分布式深度学习编程新范式:Global Tensor
Reading notes of Kazuo Inamori's advice to young people
关于使用hyperbeach出现/bin/sh: 1: packr2: not found的解决方案
flask_ Reqparse parser inheritance in restful
redis入门练习
Member array and pointer in banyan loan C language structure
数据库使用安全策略
Network security / penetration testing tool awvs14.9 download / tutorial / installation tutorial