当前位置:网站首页>用于命名实体识别的模块化交互网络
用于命名实体识别的模块化交互网络
2022-07-30 20:31:00 【JakeSun】
Modularized Interaction Network for Named Entity Recognition
用于命名实体识别的模块化交互网络

Abstract
当前的NER存在一定的缺陷:序列标注的NER模型识别长实体时表现不佳,因为序列标注只关注词级信息。边界检测和类型检测可以相互协作,两个子任务之间共享信息可以互相加强。本文提出了一种新的模块化交互网络模型(MIN),该模型能够同时利用segment-level和word-level依赖关系,并加入交互机制来支持边界检测和类型预测之间的共享信息。
1. Introduction
NER的目标是检测文本文本中实体的边界和实体的类型。本文作者在实验中发现边界检测和类型检测两个任务是相关的,因此提出了本文的方法:共享边界检测和类型检测的信息进行NER。
Emmy Rossum was from New York University.
如果University是一个实体边界,那么将对应的实体类型预测为ORG更准确。 类似的,如果知道一个实体具有ORG类型,那么预测University是实体New York University的结束边界,而不是York会更正确。
然后,基于序列标注的模型将边界和类型视为标签,因此这些信息不能在任务之间共享。
为了解决基于序列标注的模型在识别长实体的问题,以及基于片段的模型中利用片段内的词级依赖关系的问题。
本文在边界模型中加入了指针网络作为解码器,用来获取每个单词的片段级信息。 将segment-level信息和关于每个单词的对应的word-level信息连接起来,作为基于序列标注的模型的输入。 使用两个不同的编码器从两个子任务中提取它们的上下文表示,并提出了一种相互促进的交互机制,并将这些信息融合到NER模型中进行多任务训练。
2. Proposed Model

2.1 NER Module
采用rnn-bilstm-crf作为backbone。
2.1.1 Word Representation
输入句子:=<>,其中由word-level embedding和character-level embedding表示。

和分别是预训练的word embedding和由BiLSTM得到的。
2.1.2 BiLSTM Encoder
将<>馈送到BiLSTM中,得到所有words的hidden sequence <>:

在NER Module中,本文融合了Boundary Module和Type Module表示,并不是简单的将hidden sequence拼接,而是使用门控函数控制信息流数量。除此之外,本文还融合了Boundary Module中的Segment information,用于支持长实体的识别。

其中表示boundary module和type module的hidden sequence。表示boundary module的segment information。表示使用interaction mechanism之后来自两个模块的hidden sequence。表示在门控函数的控制下,输入NER module的hidden sequence。
NER Module的最终hidden representations:

2.1.3 CRF Decoder
对于输入句子:<>,预测标签序列得分为:<$y_1,...,y_n>,定义如下:

其中表示 to 的分数。表示句子中第i个单词为标签的score。
CRF模型描述了集合Y中所有可能的标签序列的预测标签y的概率:

2.2 Boundary Module
boundary module不仅需要为ner module提供上下文边界信息,还要提供segment information。
本文使用一个BiLSTM作为编码器提取不同的context boundary information。本文使用带有指针网络的神经递归网络进行检测实体段信息。
boundary模型处理实体中的开始边界词,指向相应的结束边界词,跳过实体中的其他实体单词,非实体词指向一个指定的位置。由于实体长度的变化,该模型缺乏批量训练的能力。
另外,实体中的每个单词的segment information与起始边界词相同,如果错误的检测到起始边界词,那么段内的所有词的segment information都将错误,本文改进了这个训练过程,用一种新的方法获取每个单词的segment信息。
训练起始边界词指向相应的结束边界词,句子中的其他单词指向不活动的前哨兵词(inactive)。
使用BiLSTM作为编码器,获得明显的boundary hidden sequences:

在hidden sequence 的最后一个位置填充一个哨兵向量inactive,这个哨兵向量作为不活动单词的标识(不是实体词的指向)。
使用LSTM作为解码器,在每个时间步j出生成解码后的状态,为了给LSTM的输入添加额外的信息,本文使用current(),previous(h_{i+1}^{Bdy}$)三个隐藏状态的和代替word embedding作为解码器的输入:

Note:第一个词和最后一个词没有前面一个词和后面一个词的hidden states,本文使用zero vector表示。
之后,本文使用biaffine注意机制在时间步长j为每个可能的boundary position i 生成特征表示,并使用softmax函数求出单词的概率,用于确定以单词开头,以单词结尾的entity segment的概率:

本文使用作为单词开头,以单词作为结尾的segment information置信度。然后将概率w_jH^{Seg}$:

其中表示以单词开始,以单词结尾的segment information 表示。表示segment information of boundary module。
2.3 Type Module
对于type module,本文使用于NER模型中相同的网络结构。在给定共享输入<>的情况下,使用BiLSTM来提取不同的上下文类型信息<>,然后使用CRF来标记类型标签。
2.4 Interaction Mechanism
如上所示,边界信息和类型信息可以相互增强。本文在每个子任务标签上使用self-attention机制获得明确的label representations,然后,将这些representation和相应子任务的contextual information连接起来,得到label-enhanced contextual information,将经过self-attention的向量和本身向量进行拼接。对于第i个label-enhanced boundary contextual representation ,本文首先使用biaffine attention来控制与label-enhanced type contextual information <>的attention scores。
然后,将第i个label-enhanced boundary representation 和interaction representation 拼接起来。
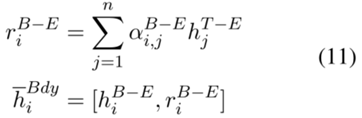
相似的,可以通过考虑边界信息得到更新的类型表示。
2.5 Joint Training


3 Experiments
3.1 Results

当与没有使用任何语言模型或外部知识的模型进行比较时,本文的MIN模型在查准率、召回率和F1分数方面优于所有比较的基线模型,并在CoNLL2003、WNUT2017、JNLPBA数据集上分别提高了0.75%,4.77%,3.26%。BiLSTM-Pointer的模型普遍低于其他模型,这是因为它没有利用片段内的词级依赖关系,并且在边界检测和类型预测期间还存在边界错误传播问题。
4 启示
将边界信息和类型信息进行交互,在具有语言模型的基础上取得的结果确实够高。 没有找到代码,但是论文的模型部分写的真的好,可以尝试复现。 欢迎关注微信公众号: 「自然语言处理CS」,一起来交流NLP。
边栏推荐
- Android studio连接MySQL并完成简单的登录注册功能
- [Ask] SQL statement to calculate the sum of column 2 by deduplicating column 1?
- Recommended system: cold start problem [user cold start, item cold start, system cold start]
- SQLyog注释 添加 撤销 快捷键
- mysql8安装步骤教程
- CDH集群spark-shell执行过程分析
- 都在说软件测试没前途,饱和了?为何每年还会增加40万测试员?
- HarmonyOS Notes ------------- (3)
- OSS simply upload pictures
- HJ85 最长回文子串
猜你喜欢





随机推荐
基于人脸的常见表情识别(2)——数据获取与整理
halcon——轮廓线
如何制作deb包
MySQL 视图(详解)
明解C语言第五章习题
2021年软件测试面试题大全
360杜跃进:太空安全风险加剧,需打造一体化防御体系
倾斜文档扫描与字符识别(opencv,坐标变换分析)
KEIL problem: [keil Error: failed to execute 'C:\Keil\ARM\ARMCC']
2022年SQL经典面试题总结(带解析)
[Typora] This beta version of Typora is expired, please download and install a newer version.
WPS怎么独立窗口显示?wps单独窗口显示怎么操作?
Mysql——字符串函数
Ordinary int main(){} does not write return 0; what will happen?
Apple Silicon配置二进制环境(一)
mysql 递归函数with recursive的用法
MySQL的DATE_FORMAT()函数将Date转为字符串
肖特基二极管厂家ASEMI带你认识电路中的三大重要元器件
推荐系统-模型:FNN模型(FM+MLP=FNN)
HMS Core Discovery第16期回顾|与虎墩一起,玩转AI新“声”态