当前位置:网站首页>Why can't Google search page infinite?
Why can't Google search page infinite?
2022-06-11 22:50:00 【Cicada bathes in the wind】

This is an interesting but little noticed problem .
When I use Google Search for MySQL When it comes to this keyword ,Google Provided only 13 Page search results , I changed it url The paging parameter of attempts to search for page 14 Page data , The following error message appears :

Baidu search also does not provide unlimited paging , about MySQL key word , Baidu search provides 76 Page search results .

Why not support infinite paging
Strong as Google Search for , Why not support infinite paging ? There are only two possibilities :
- Can't do
- It is not necessary to
「 Can't do 」 It's impossible , The only reason is 「 It is not necessary to 」.
First , When the first 1 Page search results do not have the content we need , We usually change keywords immediately , Instead of turning the page 2 page , Not to mention turning to 10 The page goes back . This is the first reason why it is unnecessary —— User demand is not strong .
secondly , The function of infinite paging is very performance consuming for search engines . You may feel strange , Turn to No 2 Page and turn to page 1000 The pages are all search , What's the difference ?
actually , A side effect of the design of high availability and high scalability of search engine is that it can not efficiently realize the unlimited paging function , Not being efficient means being able to , But the price is higher , This is a problem that all search engines will face , Professionally called 「 Deep paging 」. This is also the second reason why it is unnecessary —— High implementation cost .
Of course I don't know Google How to do the search of , So next I use ES(Elasticsearch) As an example to explain why deep paging is a headache for search engines .
Why take ES For example
Elasticsearch( Hereinafter referred to as" ES) The functions and Google And the functions provided by Baidu search are the same , And it is similar in the way of high availability and high scalability , Deep paging problems are caused by these similar optimization methods .
What is? ES
ES It's a full text search engine .
What the hell is a full-text search engine ?
Imagine a scene , You happen to hear a song with a particularly beautiful melody , I still feel the lingering sound after I go home , But you can only remember a few words in the lyrics :「 The edge of the umbrella 」. At this time, the search engine will work .
Using the search engine, you can get 「 The edge of the umbrella 」 All results of keywords , There is a term for these results , It's called documentation . And the search results are returned after sorting according to the relevance of documents and keywords . We get the definition of full-text search engine :
Full text search engine is Find relevant documents according to the contents of documents , And in accordance with the Correlation order A tool to return search results
Surfing the Internet for too long , We will gradually mistake the ability of the computer for our own ability , For example, we may mistakenly think that our brain is good at this kind of search . On the contrary , We are not good at full-text search .
for instance , If I say to you : In the Quiet Night . You may blurt out : abed, I see a silver light , The frost on the ground . look at the bright moon , Bow your head and think of your hometown . But if I ask you to say something with 「 month 」 The ancient poetry of , You must have worked hard on the membership fee .
Including the books we usually read , The directory itself is a search structure that conforms to the retrieval characteristics of our human brain , Let's go through the documentation ID Or the document title is a general sign to find a document , This structure is called Forward index .

Full text search engines are just the opposite , It is to find documents through the contents of documents , The flying flower order in the poetry conference is the full-text search engine of the human brain version .

The data structure that full-text search engines rely on is well-known Inverted index (「 inverted 」 This word means that this data structure is just the opposite of our normal way of thinking ), It is a concrete implementation of the containment relationship between words and documents .

Stop ! Can't go on , Finish the introduction in one sentence ES Well !
ESIs a Use inverted index data structure 、 Be able to find relevant documents according to their contents , And in accordance with the Correlation order Full text search engines that return search results
The secret of high availability —— copy (Replication)
High availability It is an indicator that enterprise level services must consider , High availability inevitably involves clustering and distribution , Fortunately ES Natural support cluster mode , It is very simple to build a distributed system .
ES High service availability requires that if one of the nodes is down , Can not affect the normal search service . This means that the data stored on the suspended node , Must be in Complete backups are left on other nodes . This is the concept of copy .

As shown in the figure above ,Node1 Master node ,Node2 and Node3 As a replica node, it saves the same data as the master node , In this way, the failure of any node will not affect the business search . Meet the high availability requirements of services .
But there's a fatal problem , Unable to realize system expansion ! Even if you add another node , It can not help the capacity expansion of the whole system . Because each node completely saves all the document data .
therefore ,ES Introduced slicing (Shard) The concept of .
PB The foundation stone of level quantity —— Fragmentation (Shard)
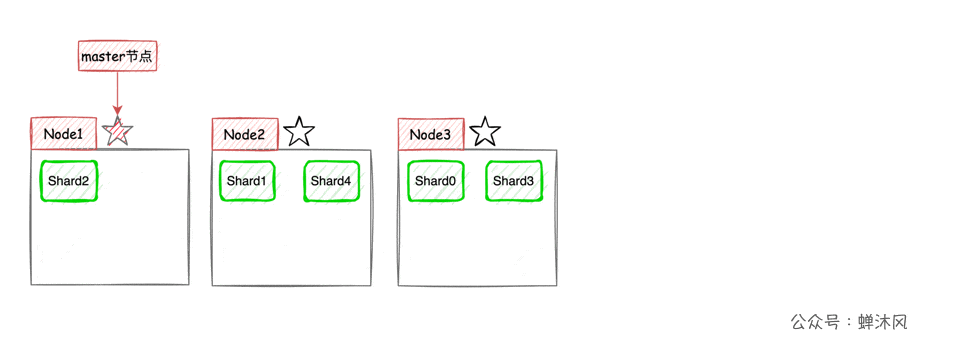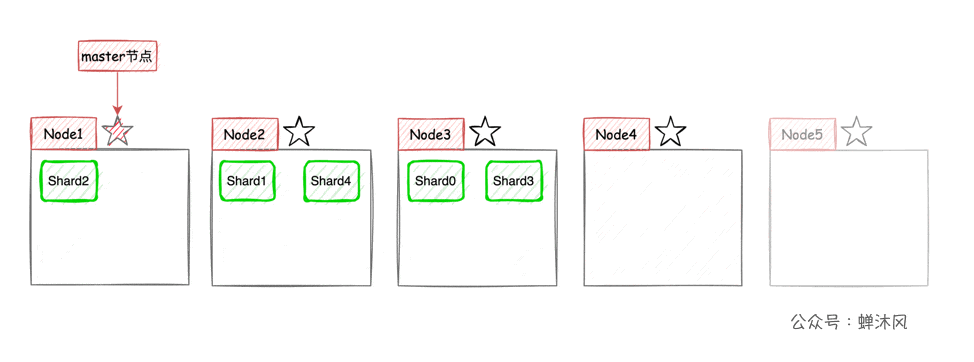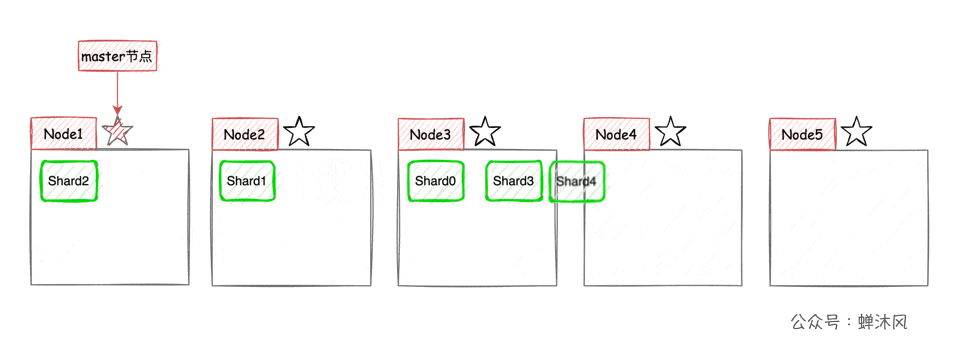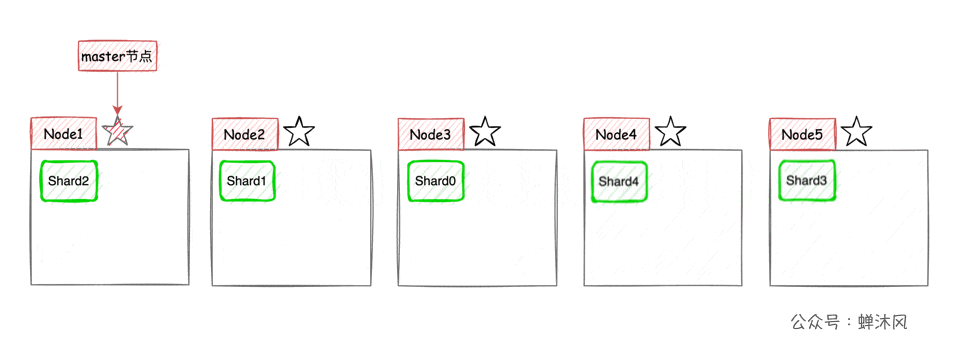
ES Put each index (ES A collection of documents in , amount to MySQL In the table ) Divide into several pieces , Slice will As evenly as possible Assign to different nodes . For example, a cluster now has 3 A node , The index is divided into 5 A shard , The distribution method is roughly ( Because how to distribute it equally depends on ES) As shown in the figure below .
thus , The horizontal expansion of the cluster is very simple , Now let's add... To the cluster 2 Nodes , be ES The partition will be automatically balanced to each node :
High availability + The elastic expansion
The copy and sharding functions work together to create ES Now High availability and Support PB Level data volume Two of the advantages of .
Now let's use 3 Nodes as an example , Show that the number of slices is 5, The number of copies is 1 Under the circumstances ,ES The partition arrangement on different nodes :

There is one caveat , In the example above, the primary partition and the corresponding replica partition do not appear on the same node , As for why , You can think about it for yourself .
Distributed storage of documents
ES How to determine which partition a document should be stored on ?

Through the above mapping algorithm ,ES Distribute the document data evenly in each partition , among routing The default is document id.
Besides , The contents of replica shards depend on the master shard for synchronization , The meaning of replica sharding is load balancing 、 The main partition position on the top that may hang up at any time , Become the new main partition .
Now the basics are over , Finally we can search .
ES The search mechanism of
A picture is worth a thousand words :
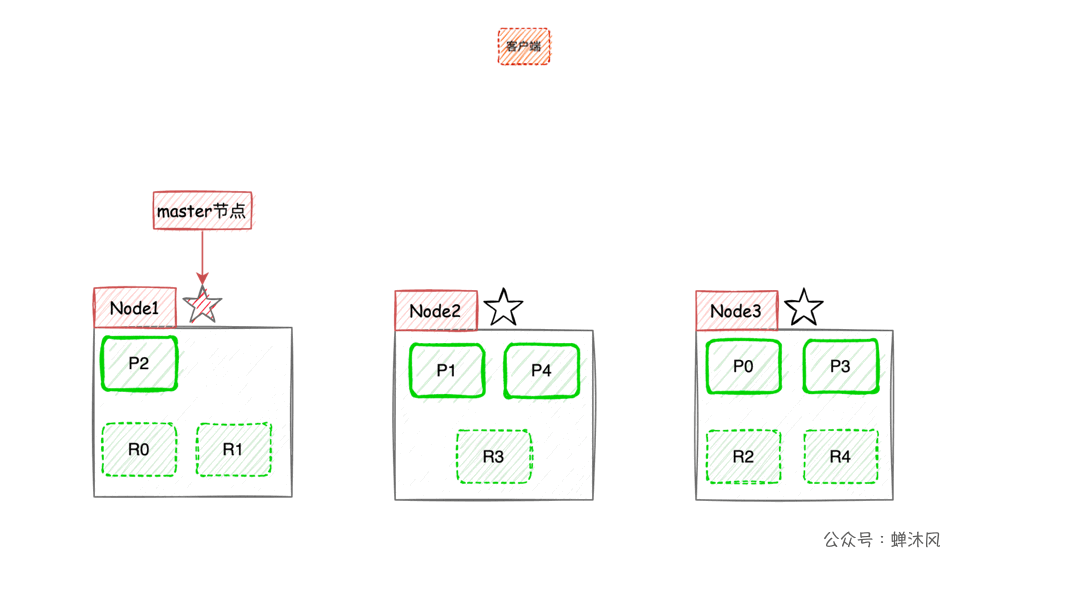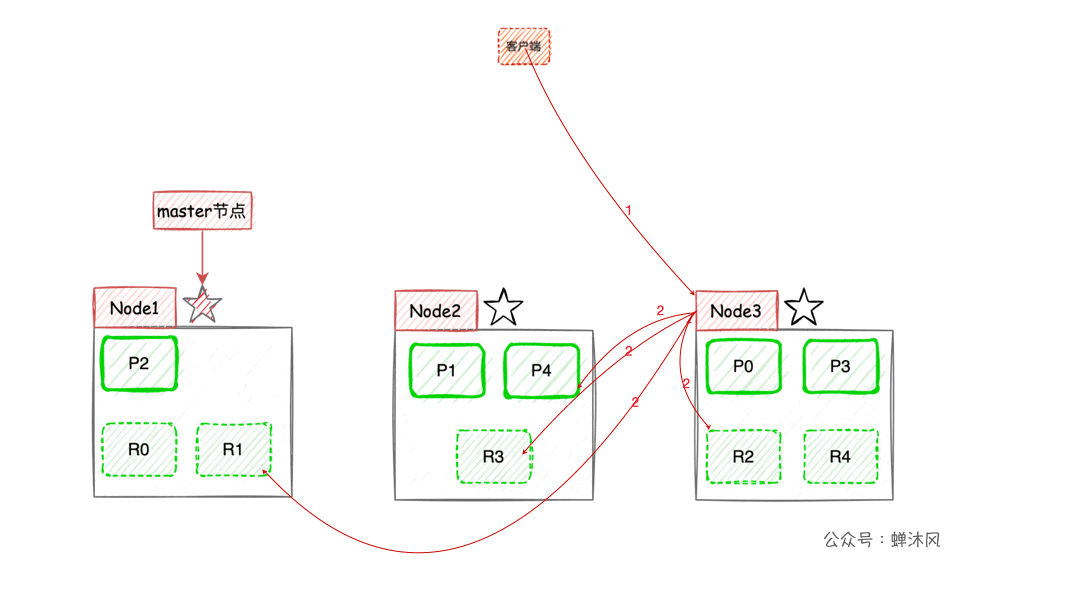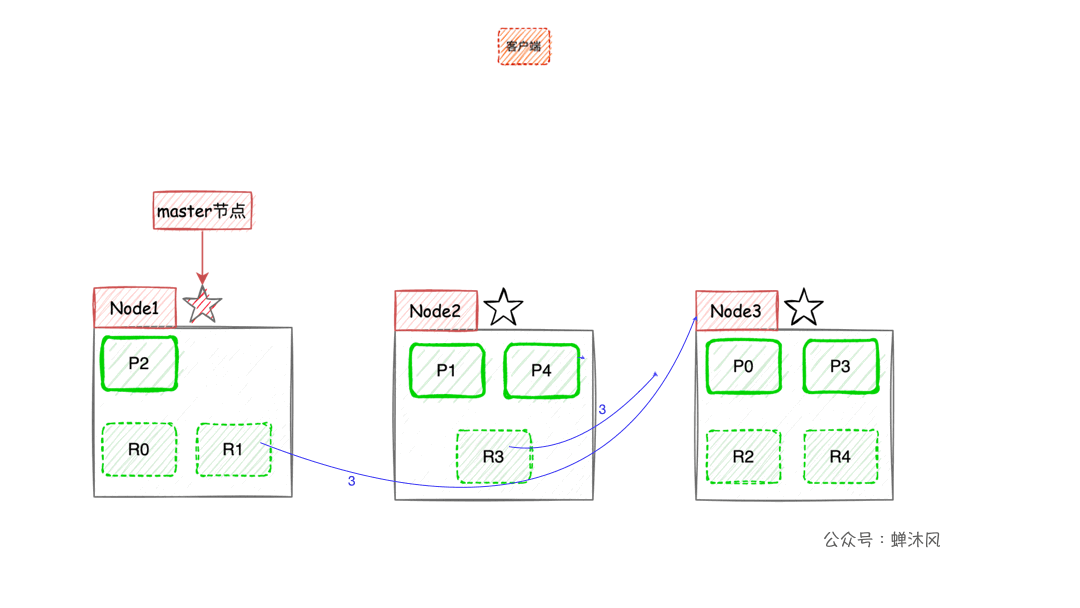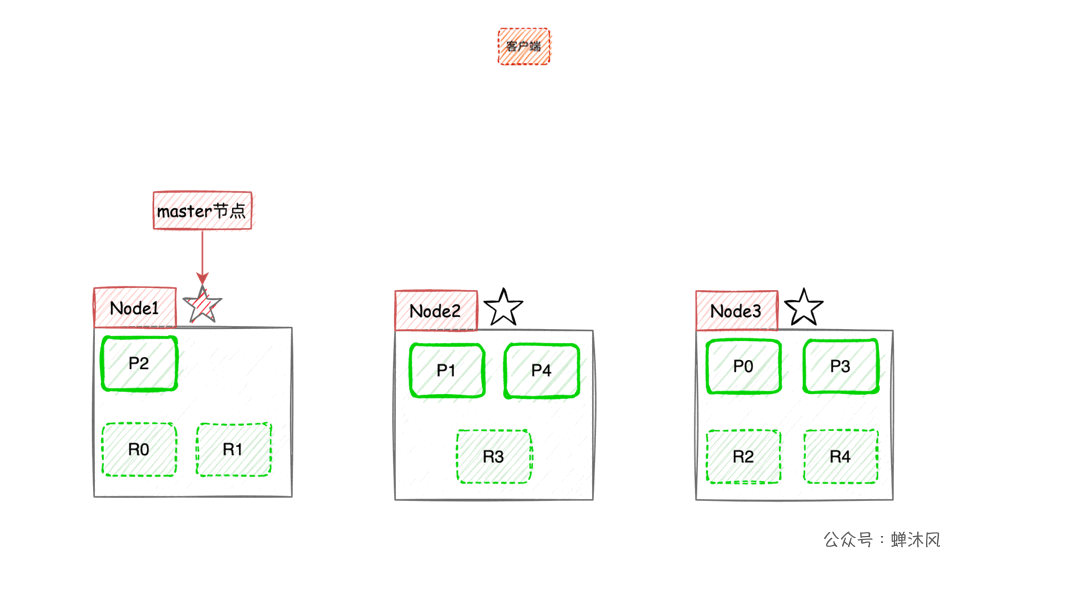
- When the client performs keyword search ,
ESA load balancing policy will be used to select a node as the coordination node (Coordinating Node) Accept the request , Let's assume that the choice isNode3node ; Node3The node will be in 10 The primary and secondary slices are randomly selected 5 A shard ( All partitions must be able to contain all contents , And can't repeat ), send out search request;- Selected 5 After the query is executed and sorted, the results are returned to
Node3node ; Node3Node consolidation 5 Results returned by sharding , After sorting again, get the result set of the corresponding page and return it to the client .
notes : actually
ESOur search is divided intoQuery StageandFetch StageTwo steps , stayQuery StageEach fragment returns the document Id And sort values ,Fetch StageAccording to the document Id Go to the corresponding partition to obtain the document details , The picture and text above simplify this , Please know .
Now consider client-side fetch 990~1000 When it comes to documentation ,ES How to give correct search results in the case of fragment storage .
obtain 990~1000 When it comes to documentation ,ES Under each partition, you need to obtain 1000 A document , Then from Coordinating Node Aggregate the results of all slices , Then sort the correlation , Finally, the correlation order is selected in 990~1000 Of 10 Documents .

The deeper the pages , Each node processes more documents , The more memory it takes up , The longer it takes , This is why search engine vendors usually do not provide deep paging , They don't have to waste performance on features that don't have strong customer demand .
official account : Cicadas bathe in the wind , Pay attention to me , Get more
End .
边栏推荐
- Is it safe for qiniu business school to send Huatai account? Really?
- IEEE-754 floating point converter
- leetcode 257. Binary Tree Paths 二叉树的所有路径(简单)
- Research Report on development trend and competitive strategy of global metallized high barrier film industry
- [technology sharing] after 16 years, how to successfully implement the dual active traffic architecture of zhubajie.com
- 点云读写(二):读写txt点云(空格分隔 | 逗号分隔)
- Learn to crawl for a month and earn 6000 a month? Don't be fooled. The teacher told you the truth about the reptile
- Three years of college should be like this
- IEEE浮点数尾数向偶舍入-四舍六入五成双
- 926. 将字符串翻转到单调递增
猜你喜欢

Meetup回顾|DevOps&MLOps如何在企业中解决机器学习困境?
![[data mining time series analysis] restaurant sales forecast](/img/9a/5b93f447e38fcb5aa559d4c0d97098.png)
[data mining time series analysis] restaurant sales forecast
想做钢铁侠?听说很多大佬都是用它入门的

Inventory | more than 20 typical security incidents occurred in February, with a loss of nearly $400million

Tkinter study notes (III)

16 | floating point numbers and fixed-point numbers (Part 2): what is the use of a deep understanding of floating-point numbers?
基于模板配置的数据可视化平台

volatile的解构| 社区征文

Simple example of logistic regression for machine learning

leetcode 中的位运算
随机推荐
每日一题-1317. 将整数转换为两个无零整数的和
动态规划之0-1背包问题(详解+分析+原码)
Exercise 9-5 address book sorting (20 points)
Want to be iron man? It is said that many big men use it to get started
16 | 浮点数和定点数(下):深入理解浮点数到底有什么用?
Getting started with message queuing MQ
Matlab point cloud processing (XXV): point cloud generation DEM (pc2dem)
Fastapi 5 - common requests and use of postman and curl (parameters, x-www-form-urlencoded, raw)
Unity中使用调用Shell的命令行
MATLAB点云处理(二十四):点云中值滤波(pcmedian)
volatile的解构| 社区征文
16 | floating point numbers and fixed-point numbers (Part 2): what is the use of a deep understanding of floating-point numbers?
华为设备配置HoVPN
MATLAB点云处理(二十五):点云生成 DEM(pc2dem)
Deconstruction of volatile | community essay solicitation
Dynamics 365 option set operation
Learn to crawl for a month and earn 6000 a month? Don't be fooled. The teacher told you the truth about the reptile
Matlab point cloud processing (XXIV): point cloud median filtering (pcmedian)
[technology sharing] after 16 years, how to successfully implement the dual active traffic architecture of zhubajie.com
分类统计字符个数 (15 分)