当前位置:网站首页>RepOptimizer: 其实是RepVGG2
RepOptimizer: 其实是RepVGG2
2022-06-29 11:02:00 【3D视觉工坊】
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨zzk
来源丨 GiantPandaCV
前言
在神经网络结构设计中,我们经常会引入一些先验知识,比如ResNet的残差结构。然而我们还是用常规的优化器去训练网络。
在本工作中,我们提出将先验信息用于修改梯度数值,称为梯度重参数化,对应的优化器称为RepOptimizer。我们着重关注VGG式的直筒模型,训练得到RepOptVGG模型,他有着高训练效率,简单直接的结构和极快的推理速度。
官方仓库:RepOptimizer
论文链接:Re-parameterizing Your Optimizers rather than Architectures
与RepVGG的区别
RepVGG加入了结构先验(如1x1,identity分支),并使用常规优化器训练。而RepOptVGG则是将这种先验知识加入到优化器实现中
尽管RepVGG在推理阶段可以把各分支融合,成为一个直筒模型。但是其训练过程中有着多条分支,需要更多显存和训练时间。而RepOptVGG可是 真-直筒模型,从训练过程中就是一个VGG结构
我们通过定制优化器,实现了结构重参数化和梯度重参数化的等价变换,这种变换是通用的,可以拓展到更多模型
 将结构先验知识引入优化器
将结构先验知识引入优化器
我们注意到一个现象,在特殊情况下,每个分支包含一个线性可训练参数,加一个常量缩放值,只要该缩放值设置合理,则模型性能依旧会很高。我们将这个网络块称为Constant-Scale Linear Addition(CSLA)
我们先从一个简单的CSLA示例入手,考虑一个输入,经过2个卷积分支+线性缩放,并加到一个输出中:

我们考虑等价变换到一个分支内,那等价变换对应2个规则:
初始化规则
融合的权重需为:
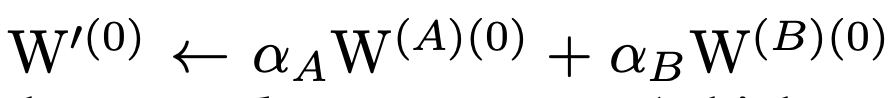
更新规则
针对融合后的权重,其更新规则为:
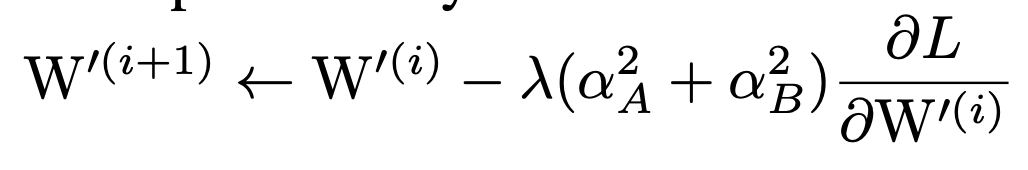
这部分公式可以参考附录A中,里面有详细的推导
一个简单的示例代码为:
import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
conv1 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv2 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv1.weight.data = torch.nn.Parameter(torch.tensor(np_w1))
conv2.weight.data = torch.nn.Parameter(torch.tensor(np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = alpha1 * conv1(torch_x) + alpha2 * conv2(torch_x)
loss = out.sum()
loss.backward()
torch_w1_updated = conv1.weight.detach().numpy() - conv1.weight.grad.numpy() * lr
torch_w2_updated = conv2.weight.detach().numpy() - conv2.weight.grad.numpy() * lr
print(torch_w1_updated + torch_w2_updated)import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
fused_conv = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
fused_conv.weight.data = torch.nn.Parameter(torch.tensor(alpha1 * np_w1 + alpha2 * np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = fused_conv(torch_x)
loss = out.sum()
loss.backward()
torch_fused_w_updated = fused_conv.weight.detach().numpy() - (alpha1**2 + alpha2**2) * fused_conv.weight.grad.numpy() * lr
print(torch_fused_w_updated)在RepOptVGG中,对应的CSLA块则是将RepVGG块中的3x3卷积,1x1卷积,bn层替换为带可学习缩放参数的3x3卷积,1x1卷积
进一步拓展到多分支中,假设s,t分别是3x3卷积,1x1卷积的缩放系数,那么对应的更新规则为:

第一条公式对应输入通道==输出通道,此时一共有3个分支,分别是identity,conv3x3, conv1x1
第二条公式对应输入通道!=输出通道,此时只有conv3x3, conv1x1两个分支
第三条公式对应其他情况
需要注意的是CSLA没有BN这种训练期间非线性算子(training-time nonlinearity),也没有非顺序性(non sequential)可训练参数,CSLA在这里只是一个描述RepOptimizer的间接工具。
那么剩下一个问题,即如何确定这个缩放系数
HyperSearch
受DARTS启发,我们将CSLA中的常数缩放系数,替换成可训练参数。在一个小数据集(如CIFAR100)上进行训练,在小数据上训练完毕后,我们将这些可训练参数固定为常数。
具体的训练设置可参考论文
实验结果
 实验效果看上去非常不错,训练中没有多分支,可训练的batchsize也能增大,模型吞吐量也提升不少。
实验效果看上去非常不错,训练中没有多分支,可训练的batchsize也能增大,模型吞吐量也提升不少。
在之前RepVGG中,不少人吐槽量化困难,那么在RepOptVGG下,这种直筒模型对于量化十分友好:

代码简单走读
我们主要看 repoptvgg.py 这个文件,核心类是 RepVGGOptimizer
在reinitialize 方法中,它做的就是repvgg的工作,将1x1卷积权重和identity分支给融到3x3卷积中:
if len(scales) == 2:
conv3x3.weight.data = conv3x3.weight * scales[1].view(-1, 1, 1, 1) \
+ F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[0].view(-1, 1, 1, 1)
else:
assert len(scales) == 3
assert in_channels == out_channels
identity = torch.from_numpy(np.eye(out_channels, dtype=np.float32).reshape(out_channels, out_channels, 1, 1))
conv3x3.weight.data = conv3x3.weight * scales[2].view(-1, 1, 1, 1) + F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[1].view(-1, 1, 1, 1)
if use_identity_scales: # You may initialize the imaginary CSLA block with the trained identity_scale values. Makes almost no difference.
identity_scale_weight = scales[0]
conv3x3.weight.data += F.pad(identity * identity_scale_weight.view(-1, 1, 1, 1), [1, 1, 1, 1])
else:
conv3x3.weight.data += F.pad(identity, [1, 1, 1, 1])然后我们再看下GradientMask生成逻辑,如果只有conv3x3和conv1x1两个分支,根据前面的CSLA等价变换规则,conv3x3的mask对应为:
mask = torch.ones_like(para) * (scales[1] ** 2).view(-1, 1, 1, 1)而conv1x1的mask,需要乘上对应缩放系数的平方,并加到conv3x3中间:
mask[:, :, 1:2, 1:2] += torch.ones(para.shape[0], para.shape[1], 1, 1) * (scales[0] ** 2).view(-1, 1, 1, 1)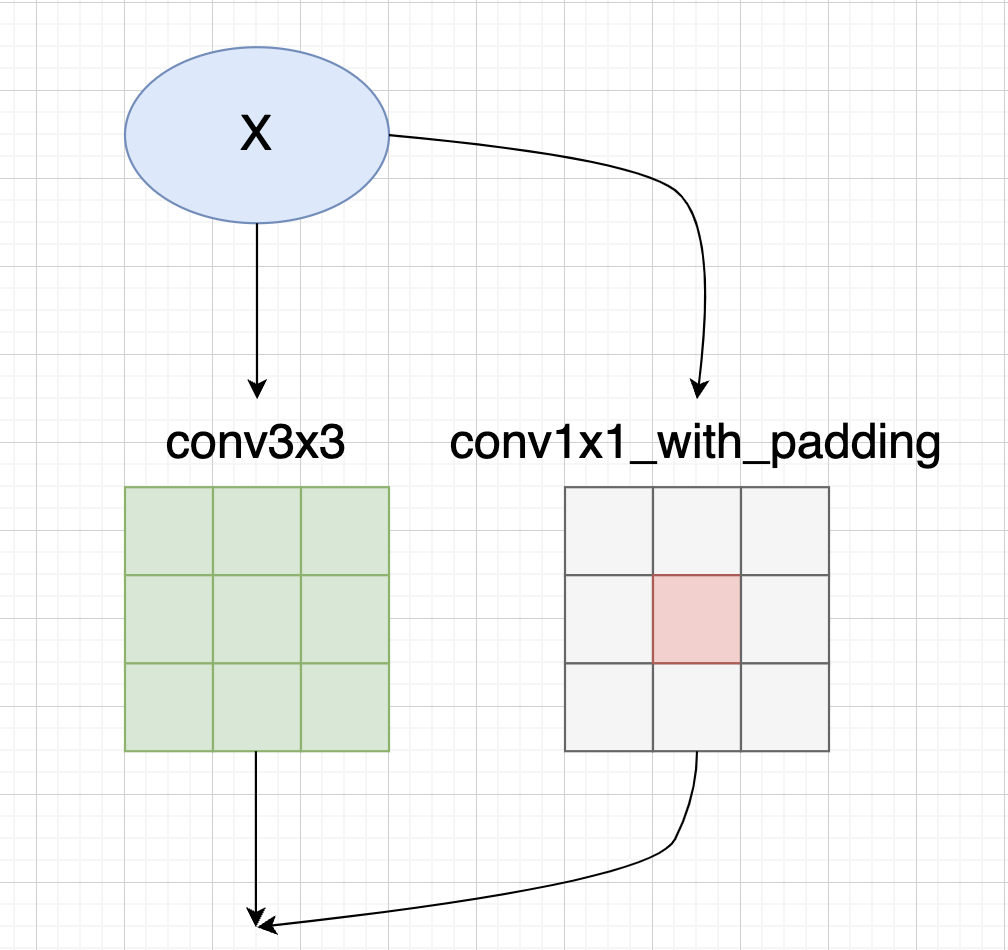
如果还有Identity分支,我们则需要在对角线上加上1.0(Identity分支没有可学习缩放系数)
mask[ids, ids, 1:2, 1:2] += 1.0如果有不明白Identity分支为什么对应的是对角线,可以参考下笔者的图解RepVGG
总结
这篇文章出来有段时间了,但是好像没有很多人关注。在我看来这是个实用性很高的工作,解决了上一代RepVGG留下的小坑,真正实现了训练时完全直筒的模型,并且对量化,剪枝友好,十分适合实际部署。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~
边栏推荐
- 美创入选信通院“业务安全推进计划”首批成员单位
- 【HBZ分享】Semaphore 与 CountDownLatch原理
- 2022 amination process test question simulation test question bank and online simulation test
- Introduction to software engineering - Chapter 5 - overall design
- [HBZ sharing] InnoDB principle of MySQL
- 哈希Hash竞猜游戏系统开发详解技术丨哈希竞猜游戏系统开发方案解析
- Object 类——万类之父
- AOSP ~ 初始化语言
- rxjs Observable 设计原理背后的 Pull 和 Push 思路
- MySQL enable slow query
猜你喜欢

Oracle netsuite helps TCM bio understand data changes and make business development more flexible

Adding sharding sphere5.0.0 sub tables to the ruoyi framework (adding custom sub table policies through SPI)

Nature | biosynthetic potential of global marine microbiome

Qt学习03 Qt的诞生和本质

When a technician becomes a CEO, what "bugs" should be modified?

小白学习MySQL - 增量统计SQL的需求 - 开窗函数的方案

Qt学习07 Qt中的坐标系统
巴比特 | 元宇宙每日必读:HTC 宣布推出首款元宇宙手机,售价约2700元人民币,都有哪些新玩法?...

What are the main factors that affect the heat dissipation of LED packaging?

Object 类——万类之父
随机推荐
Good news | Haitai Fangyuan has passed the cmmi-3 qualification certification, and its R & D capability has been internationally recognized
喜报|海泰方圆通过CMMI-3资质认证,研发能力获国际认可
分布式缓存之Memcached
seekg ()[通俗易懂]
Xuetong denies that the theft of QQ number is related to it: it has been reported; IPhone 14 is ready for mass production: four models are launched simultaneously; Simple and elegant software has long
【文献翻译】Concealed Object Detection(伪装目标检测)
普通用户使用vscode登录ssh编辑root文件
Object class - the father of ten thousand classes
哈希Hash竞猜游戏系统开发详解技术丨哈希竞猜游戏系统开发方案解析
2022年资料员-岗位技能(资料员)操作证考试题库及模拟考试
Qt学习02 GUI程序实例分析
equals提高执行速度/性能优化
Adding sharding sphere5.0.0 sub tables to the ruoyi framework (adding custom sub table policies through SPI)
Exclusive interview with CTO: the company has deepened the product layout and accelerated the technological innovation of domestic EDA
杰理之关于 TWS 声道配置【篇】
Nature | biosynthetic potential of global marine microbiome
Object 类——万类之父
Information technology application and innovation professionals (database) intermediate training hot enrollment (July 6-10)
地平线开发板配置网段
【VTK】MFC基于VTK8.2的网格编辑器