当前位置:网站首页>【SCA-CNN 解读】空间与通道注意力:Spatial and Channel-wise Attention
【SCA-CNN 解读】空间与通道注意力:Spatial and Channel-wise Attention
2022-06-13 00:35:00 【AI 菌】

摘要
视觉注意已经成功地应用于结构预测任务,如视觉字幕和问题回答。现有的视觉注意力模型一般是空间的,即注意力被建模为空间概率,该空间概率对编码输入图像的CNN的最后一个卷积层特征图进行重新加权。 然而,我们认为,这种空间注意并不一定符合注意力机制——一种结合了随时间推移的上下文注视的动态特征提取器,因为CNN的特征是空间的、通道的和多层次的。在本文中,我们介绍了一种新的卷积神经网络,称为SCA-CNN,它在CNN中结合了空间和通道方向的关注。 在图像字幕任务中,SCA-CNN在多层特征映射中动态调整句子生成上下文,编码视觉注意在哪里(即,多层的注意空间位置)和是什么(即,注意通道)。我们在三个基准图像字幕数据集:Flickr8K、Flickr30K和MSCOCO上对所提出的SCA-CNN架构进行了评估。据观察,SCA-CNN的性能明显优于最先进的基于视觉注意力的图像字幕方法。
一、引言
视觉注意在各种结构预测任务中被证明是有效的,例如图像/视频字幕和视觉问题回答。它的成功主要归功于一个合理的假设,即人类的视觉并不倾向于一次处理整个图像;相反,一个人只在需要的时候和在需要的地方关注整个视觉空间的特定部分。具体地说,注意力不是将图像编码成静态向量,而是允许图像特征从句子语境进化而来。以这种方式,视觉注意可以被认为是一种动态特征提取机制,其结合了随着时间推移的上下文注视。
在本文中,我们将充分利用CNN的三个特征进行基于视觉注意的图像字幕。特别是,我们提出了一种新颖的基于空间和通道注意力的卷积神经网络,称为SCA-CNN,它学习关注多层3D特征地图中的每个特征条目。图1说明了在多层特征映射中引入通道注意的动机。首先,由于通道特征映射实质上是相应过滤器的检测响应映射,因此通道注意可以看作是根据句子语境的需要选择语义属性的过程。例如,当我们想要预测蛋糕时,我们的通道方向注意(例如,在Conv5 3/Conv5 4特征图中)将根据蛋糕、火、光和蜡烛形状等语义在由过滤器生成的通道方向特征图上分配更多的权重。其次,由于特征地图依赖于其较低层的特征地图,自然会在多个层次上进行注意,从而获得对多个语义抽象的视觉注意。例如,强调与更基本的形状相对应的较低层通道是有益的,如组成蛋糕的阵列和圆柱体。
们在三个著名的图像字幕基准:Flickr8K、Flickr30K和MSCOCO上验证了所提出的SCACNN的有效性。在BLEU4中,SCA-CNN可以显著超过空间注意模型4.8%。综上所述,我们提出了一个统一的SCA-CNN框架,以有效地整合CNN特征中的空间、通道和多层视觉注意,用于图像字幕。特别是,提出了一种新的空间和通道注意模型。该模型是通用的,因此可以应用于任何CNN体系结构中的任何层,例如流行的VGG[25]和ResNet[8]。SCA-CNN帮助我们更好地了解CNN特征在句子生成过程中的演变。
二、相关工作
我们对用于神经图像/视频字幕(NIC)和视觉问答(VQA)的编解码器框架中使用的视觉注意模型感兴趣,这符合最近将计算机视觉和自然语言连接起来的趋势。NIC和VQA的开创性工作使用CNN将图像或视频编码为静态视觉特征向量,然后将其送入RNN以解码字幕或答案等语言序列。
然而,静态向量不允许图像特征适应手边的句子上下文。在机器翻译中引入的注意机制的启发下,译码动态地选择有用的源语言单词或子序列来翻译成目标语言,视觉注意模型在NIC和VQA中得到了广泛的应用。我们将这些基于注意力的模型归类为以下三个领域,它们激励了我们的SCA-CNN。
Xu等人提出了第一个表象捕捉的视觉注意模型。总的来说,他们使用了选择最有可能关注的区域的“硬”集合,或用关注权重平均空间特征的“软”集合。至于VQA,朱等人采用“软”关注度合并图像区域特征。为了进一步提炼空间注意,杨等人对空间注意进行了研究。徐某等人采用堆叠式空间注意模型,其中第二个注意基于第一个注意调制的注意特征图。与他们不同的是,我们的多层次关注应用在CNN的多个层面上。上述空间模型的一个共同缺陷是它们通常在关注的特征地图上求助于加权汇集。因此,空间信息不可避免地会丢失。更严重的是,他们的注意力只集中在最后一层,在那里,感受野的大小会很大,而且各个感受野区域之间的差异很小,导致空间注意不显著。
除了空间信息外,You等人也提出了自己的观点,提出在NIC中选取语义概念,其中图像特征是属性分类器的置信度向量。贾等人利用图像与字幕之间的相关性作为全局语义信息来指导LSTM生成句子。然而,这些模型需要外部资源来训练这些语义属性。在SCA-CNN中,卷积层的每个过滤器核充当语义检测器。因此,SCA-CNN的通道注意类似于语义注意。
三、空间与通道注意力
3.1 概述
我们采用流行的编解码器框架来生成图像字幕,其中CNN首先将输入图像编码成一个向量,然后LSTM将该向量解码成一个单词序列。如图2所示,SCA-CNN通过多层的通道注意和空间注意使原始的CNN多层特征地图适应句子上下文。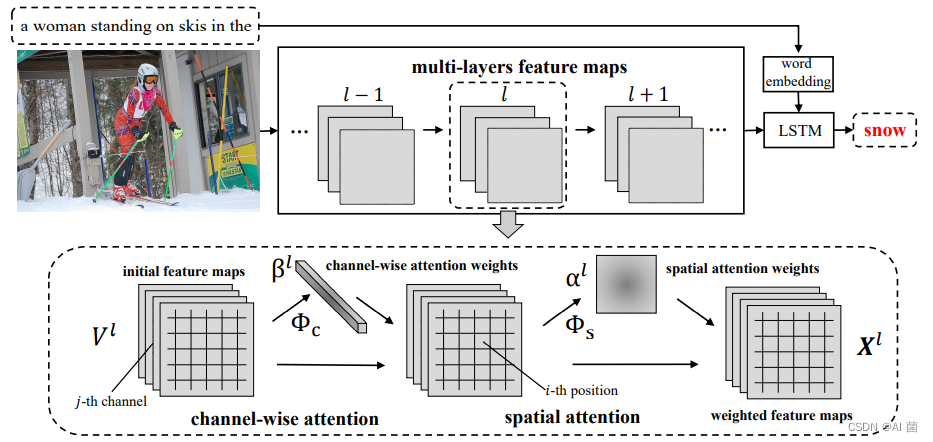
形式上,假设我们想要生成图像标题的第t个单词。现在,我们在LSTM存储器ht−1∈Rd中编码了最后一句上下文,其中d是隐藏状态维度。在l层,空间和通道方向的关注权重γ是hT−1和当前cnn特征V1的函数。因此,SCA-CNN以循环和多层的方式使用注意权重γ来调制VL,如下:
其中,x1是调制特征,Φ(·)是将在第3.2节和第3.3节中详细描述的空间和通道方向的注意力函数,v1是从前一卷积层输出的特征图,例如,紧跟在合并、下采样或卷积之后的卷积[25,8],f(·)是调制cnn特征和关注权重的线性加权函数。与现有流行的基于注意力权重[34]汇总所有视觉特征的调制策略不同,函数f(·)应用了按元素相乘。到目前为止,我们已经准备好通过以下方式生成第t个单词:
其中,L是转换层的总数;pt∈R|D|是概率向量,D是包括所有字幕词的预定义词典。
3.2 空间注意力
一般来说,字幕词只涉及图像的部分区域。例如,在图1中,当我们想要预测蛋糕时,只有包含蛋糕的图像区域是有用的。因此,应用全局图像特征向量来生成字幕可能会因为不相关的区域而导致次优结果。空间注意机制试图更多地关注与语义相关的区域,而不是平等地考虑每个图像区域。在不失去一般性的情况下,我们丢弃了分层上标l。我们通过展平原始V的宽度和高度来重塑V=[v1,v2,…,Vm],其中vi∈Rc和m=W·H。我们可以认为通孔是第i个位置的视觉特征。在给定先前时间步长LSTM隐藏状态ht−1的情况下,我们使用单层神经网络,然后使用Softmax函数来生成图像区域上的注意力分布α。以下是空间注意力模型Φ的定义:

3.3 通道注意力
注意,公式(3)中的空间注意函数仍然需要视觉特征V来计算空间注意权重,但用于空间注意的视觉特征V实际上不是基于注意的。因此,我们引入了一种基于通道的注意机制来关注特征V。值得注意的是,每个CNN过滤器充当模式检测器,而CNN中特征映射的每个通道都是相应卷积过滤器的响应激活。因此,以通道化的方式应用注意机制可以被视为选择语义属性的过程。
对于通道方面的关注,我们首先将V重塑为U,并且U=[U1,U2,…,UC],其中UI∈RW×H表示特征映射V的第i个通道,而C是通道的总数。然后,我们对每个通道应用平均汇集,以获得通道特征v:
其中标量vi是表示第i个通道特征的矢量ui的平均值。在空间注意模型的定义之后,基于通道的注意模型Φ可以定义如下:
3.4 混合注意力机制
根据通道注意和空间注意的不同实施顺序,存在两种同时包含两种注意机制的模型。我们将这两种类型区分如下:
通道-空间注意力。 第一种类型被称为通道-空间(C-S),在空间注意之前应用通道注意。C-S类型的流程图如图2所示。首先,在给定初始特征图V的情况下,我们采用基于通道的注意权重Φ来获得通道通道的注意权重β。通过β和V的线性组合,我们得到了按通道加权的特征映射。然后将通道加权特征图反馈给空间注意力模型Φ,得到空间注意力权重α。在获得两个注意力权重α和β后,我们可以将V、β,α馈送到调制函数f以计算调制特征图X。所有过程总结如下:
空间-通道注意力。第二种类型称为SpatialChannel(S-C),是一种首先实现空间注意的模型。对于S-C型,在给定初始特征图V的情况下,我们首先利用空间注意力Φ来获得空间注意力权重α。基于α、线性函数fs(·)和通道方向注意模型Φc,我们可以按照C-S类型的配方来计算调制特征X:
四、实验
我们将通过回答以下问题来验证所提出的SCACNN图像字幕框架的有效性:
- 第一,通道注意是否有效?它会改善空间注意力吗?
- 其二,多层次的注意力有效吗?与其他最先进的视觉注意模型相比,SCA-CNN的表现如何?
4.1 数据集和评价标准
我们在三个著名的基准上进行了实验:
- 1)Flickr8k:包含8000张图片。根据其官方拆分,它选择6000张图像进行训练,1000张图像进行验证,1000张图像进行测试;
- 2)Flickr30k:包含31000张图片。由于缺乏正式的分裂,为了与以前的工作进行公平的比较,我们报告了以前工作中使用的公开可用的分裂的结果。在此拆分中,29,000个图像用于培训,1,000个图像用于验证,1,000个图像用于测试
- 3)MSCOCO:训练集包含82,783幅图像,验证集包含40,504幅图像,测试集中包含40,775幅图像。由于MSCOCO测试集的基本事实不可用,因此将验证集进一步拆分成用于模型选择的验证子集和用于本地实验的测试子集。这种分裂也紧随其后,它利用整个82,783个训练集图像进行训练,并从官方验证集中选择5,000个图像进行验证和5,000个图像进行测试。对于句子的预处理,我们遵循公开的代码1。我们使用BLEU([email protected],[email protected],[email protected],[email protected])、流星(MT)、苹果酒(CD)和胭脂-L(RG)作为评价指标。简而言之,对于所有这四个度量,它们衡量了n元语法在生成的句子和基本事实句子中出现的一致性,其中这种一致性由n元语法的显着性和稀有性来加权。同时,这四个指标都可以通过MSCOCO字幕评估工具2直接计算出来。而且我们的源代码已经公开可用了。



五、结论
本文提出了一种新的深度注意模型SCA-CNN用于图像字幕。SCA-CNN充分利用了CNN的特点,产生了关注的图像特征:空间性、渠道智能性和多层次性,从而在热门基准上实现了最先进的性能。SCA-CNN的贡献不仅是更强大的注意力模型,而且更好地理解了在句子生成过程中CNN的注意力在哪里(即空间)和什么(即通道方面)的演变。在未来的工作中,我们打算在SCA-CNN中引入时间注意,以便在不同的视频帧中参与视频字幕的特征。我们还将研究如何在不过度匹配的情况下增加注意力层的数量。
边栏推荐
- Generate two-dimensional code in Delphi
- Delphi Chinese digit to Arabic digit
- Using STM32 DMA to drive 4-wire SPI interface OLED high-speed display
- [LeetCode]21. Merge two ordered linked lists twenty-nine
- 63. different paths II
- Go design concurrent web crawler
- 测试平台系列(97) 完善执行case部分
- 也许尘埃落地,我们才能想清楚互联网的本质
- 磁盘分区方式对比(MBR与GPT)
- C language standard IO, for example: fread(), fwrite(), fgetc(), etc. (end)
猜你喜欢

RCC clock configuration of stm32f401

Using com0com/com2tcp to realize TCP to serial port (win10)
![[matlab] matrix](/img/15/da3b530fca50080392c89e91998526.png)
[matlab] matrix

Stm32f4 development of DMA transmission to GPIO port

安全事故等级划分为哪几级

Masa auth - overall design from the user's perspective

63. 不同路径 II
MASA Auth - 从用户的角度看整体设计

通过抓包下载钉钉直播回放
![[matlab] 3D curve and 3D surface](/img/50/44fec1cae6e2bbab1d9e000578f281.png)
[matlab] 3D curve and 3D surface
随机推荐
浏览器控制台注入JS
Transaction creation of btcd transaction process (I)
Several interview questions in TCP three grips and four swings
Go implements concurrent non blocking caching
How to quickly query the online status of mobile phones
Tsinghua Bosch joint ml center, thbi lab:cheng Yang Ying | realize safety reinforcement learning through the value at risk of constraints
antdPro - ProTable 实现两个选择框联动效果
2022施工員-設備方向-通用基礎(施工員)操作證考試題及模擬考試
MAYA建模六
[LeetCode]13. Roman numerals to integers thirty
Building crud applications in golang
[LeetCode]7. Integer inversion thirty-nine
Use of split() method in string class
[matlab] basic knowledge
测试平台系列(97) 完善执行case部分
[GXYCTF2019]禁止套娃--详解
Easyexcel read excel simple demo
[gxyctf2019] no dolls -- detailed explanation
MySQL finds duplicate data based on one or more fields
Leetcode weekly -- April to May