当前位置:网站首页>2022cuda summer training camp Day1 practice
2022cuda summer training camp Day1 practice
2022-07-29 10:27:00 【Hua Weiyun】

Zhang Xiaobai once successfully ran the first CUDA Program , But I just know what it is and I don't know why . therefore CUDA Training camp is to help you know why .
We put CPU, This area of memory is called “ host (HOST)”, hold GPU, This area of video memory is called “ equipment (DEVICE)”.
CUDA The code execution of includes the following steps :
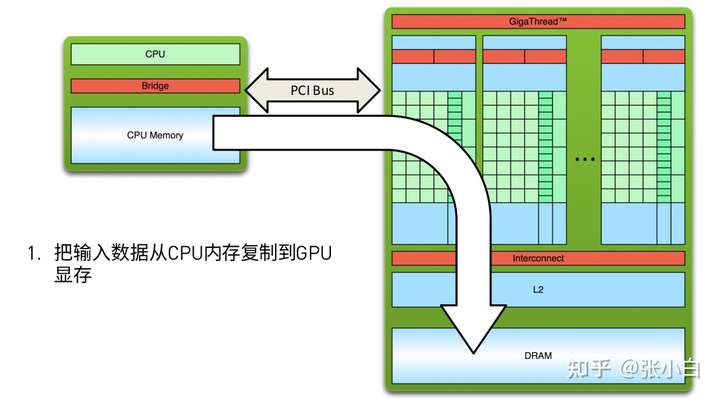
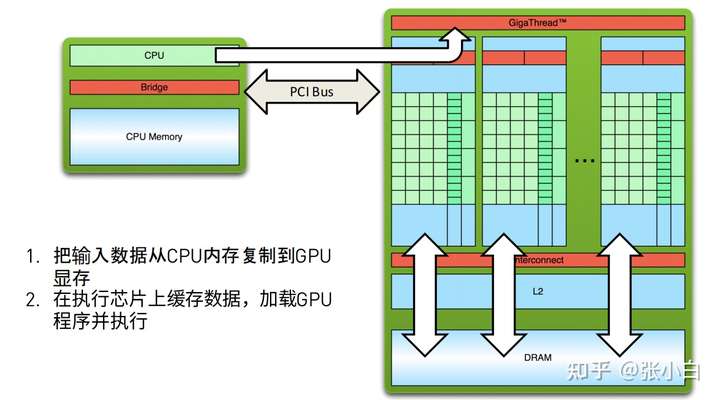
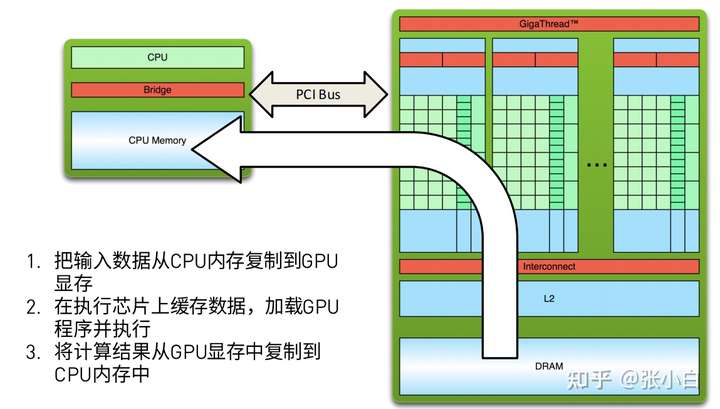
Briefly , Namely host_to_device-》 stay device Top parallel computing -》device_to_host.
cuda The program is actually a right C Extension program . Its suffix is .cu, If the header file is .cuh.
This .cu Procedure except C Outside the syntax of the program , Some more cuda Unique part of , For example, it prefixes the function , It is divided into __global__, __host__,__device__ Three .
about __global__, That's what the training camp says :

So-called “ Perform configuration ”, As we'll see , For instance, <<< >>> In the middle .
This identifier will be a C The function is declared as a Kernel function . It can only be used on devices (device) On the implementation .
about __host__ That's what it says :

about __device__ That's what it says :

Personal understanding , These prefixes define the device where these codes run , This allows the program to decide which device to run on .
For a simple Hello World In terms of code :
#include <stdio.h>void hello_from_cpu(){ printf("Hello World from the CPU!\n");}int main(void){ hello_from_cpu(); return 0;}If we want it to be in GPU Up operation , Only two steps are needed :
(1) The function to be called hello_from_cpu Change it to hello_from_gpu , prefix __global__ Define it as a kernel function .
(2) stay main When the main function is called , Plus execution configuration <<< >>> part , If you add <<<1,1>>> Is parallel 1 Time , If you add <<<2,4>>> Then run 2X4 Time .
Let's look at the effect of the actual code modification :
#include <stdio.h>__global__ void hello_from_gpu(){ printf("Hello World from the GPU!\n");}int main(void){ hello_from_gpu<<<1,1>>>(); return 0;}cu The code must use nvcc compile , Compile according to GPU Fill in different parameters for different architectures .

among ,arch The parameters are as follows :
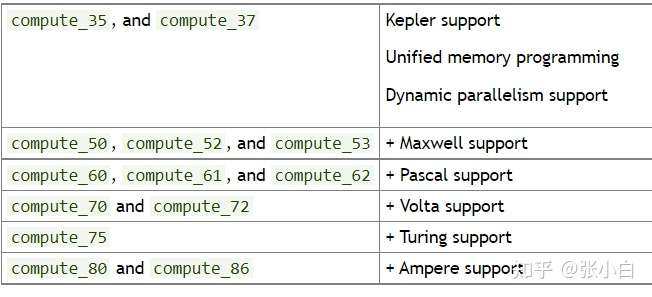
code The parameters are as follows :
A simple example , The graphics card of Zhang Xiaobai's notebook is Quardo P1000, yes Pascal framework , So the parameter is compute_61 and sm_61.
We execute the following statement :
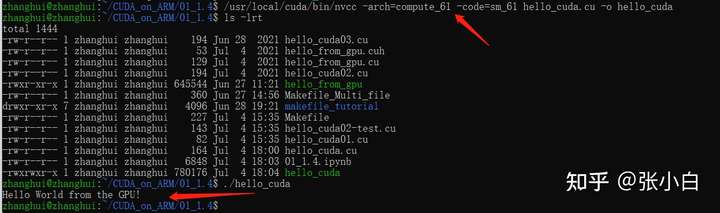
/usr/local/cuda/bin/nvcc -arch=compute_61 -code=sm_61 hello_cuda.cu -o hello_cuda
./hello_cuda
If the execution configuration is changed to 2,4:

It can be found that this kernel function has been executed 8 Time .
Let's see if this code can be used jupyter lab perform .
Let's decompress Provided by the training camp jupyter Exercise pack :CUDA_on_ARM.zip
decompression :unzip, If you want to implement it, you have to install unzip:
Perform decompression :unzip CUDA_on_ARM.zip
install PIP:
sudo apt install python3-pip

It seems python3 and pip All ready OK 了 .
pip install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo apt install jupyter
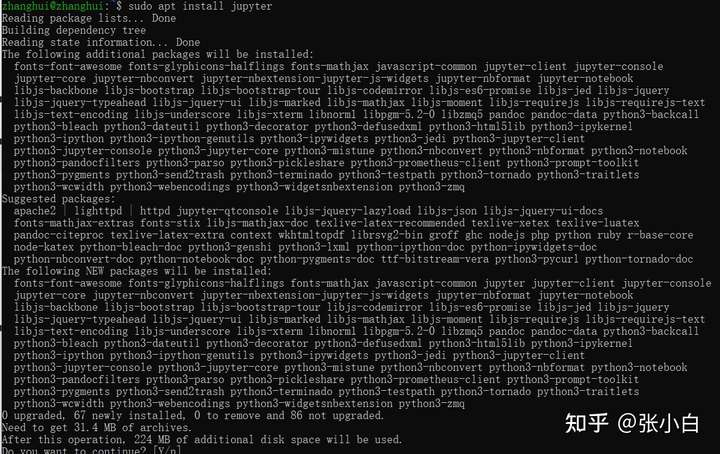
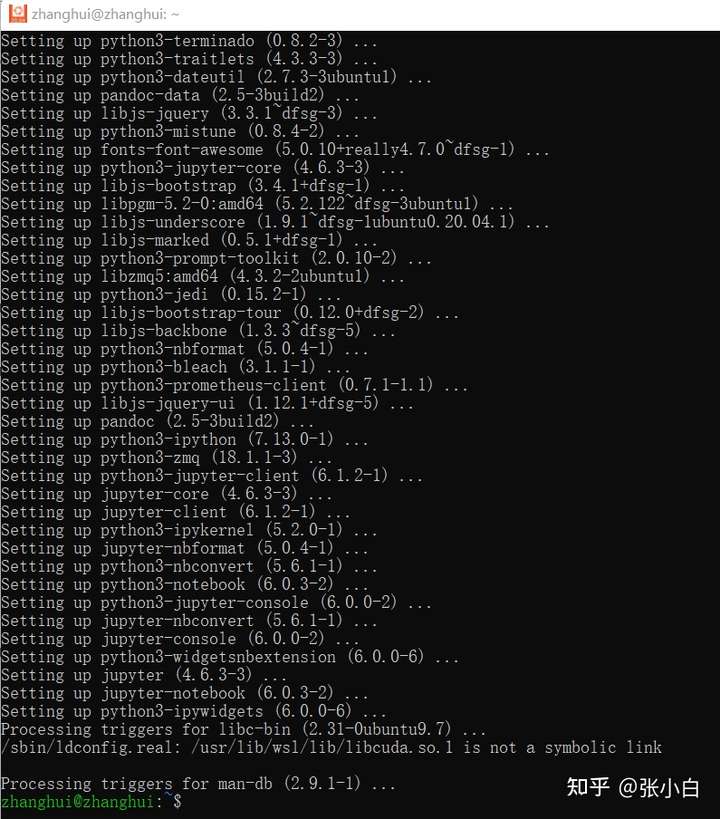
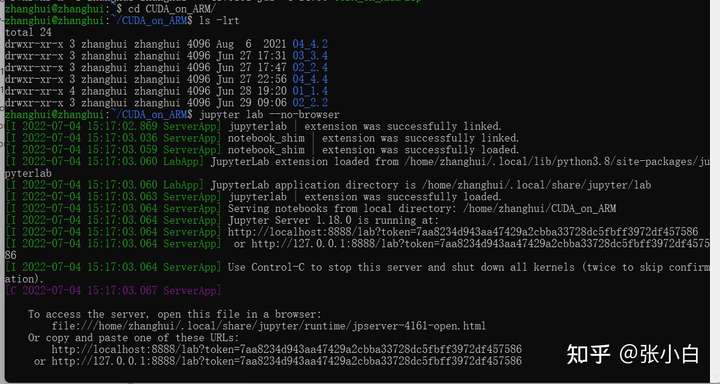
start-up jupyter lab --no-browser have a look :
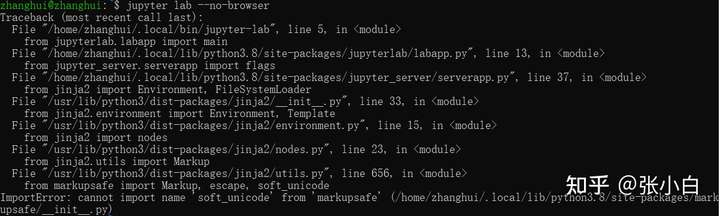
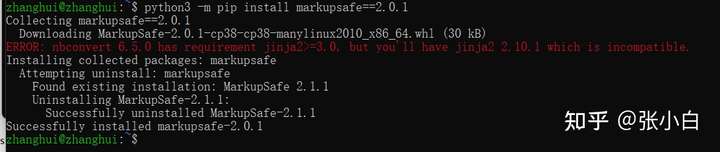
Wrong report , No problem , Du Niang :https://blog.csdn.net/weixin_45438997/article/details/124261720
pip show markupsafe
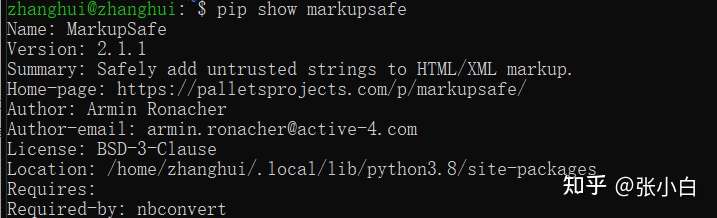
python -m pip install markupsafe==2.0.1
Restart :jupyter lab --no-browser
Of course, you can set the password before starting :
jupyter server password
Type twice 123456

Browser open :http://127.0.0.1:8888/lab
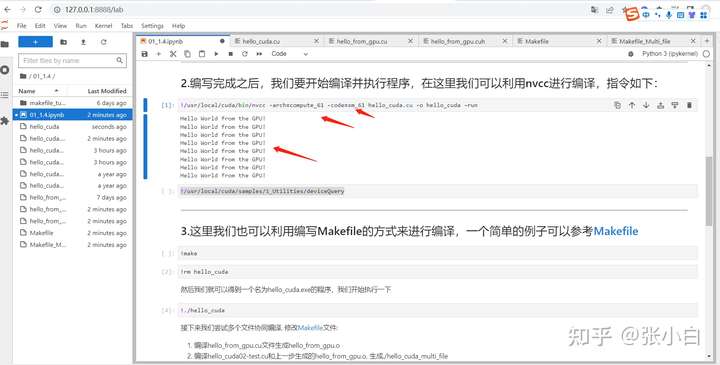
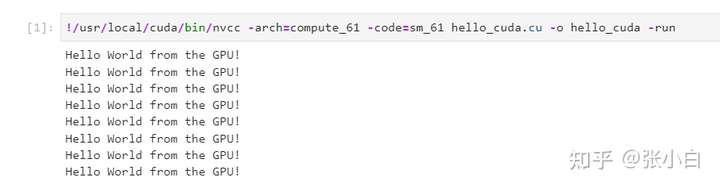
so , stay jupyter lab You can also experience CUDA Code .
( To be continued )
边栏推荐
- Efficient 7 habit learning notes
- Mitsubishi PLC and Siemens PLC
- What is the difference between a global index and a local index?
- ORBSLAM2安装测试,及各种问题汇总
- Second handshake?? Three waves??
- Easy to understand and explain the gradient descent method!
- Function - (C travel notes)
- 二次握手??三次挥手??
- “为机器立心”:朱松纯团队搭建人与机器人的价值双向对齐系统,解决人机协作领域的重大挑战
- What is "enterprise level" low code? Five abilities that must be possessed to become enterprise level low code
猜你喜欢

Some suggestions for programmers to leave single
![[jetson][转载]jetson上安装pycharm](/img/65/ba7f1e7bd1b39cd67018e3f17d465b.png)
[jetson][转载]jetson上安装pycharm

Static resource mapping

根据给定字符数和字符,打印输出“沙漏”和剩余数

关系型数据库之MySQL8——由内而外的深化全面学习

通俗易懂讲解梯度下降法!

DW: optimize the training process of target detection and more comprehensive calculation of positive and negative weights | CVPR 2022

汉源高科千兆2光6电导轨式网管型工业级以太网交换机支持X-Ring冗余环网一键环网交换机
![[ts]typescript learning record pit collection](/img/4c/14991ea612de8d5c94b758174a1c26.png)
[ts]typescript learning record pit collection

Follow teacher Wu to learn advanced numbers - function, limit and continuity (continuous update)
随机推荐
函数——(C游记)
汉源高科千兆2光6电导轨式网管型工业级以太网交换机支持X-Ring冗余环网一键环网交换机
[paper reading] q-bert: Hessian based ultra low precision quantification of Bert
HMS Core Discovery第16期回顾|与虎墩一起,玩转AI新“声”态
SkiaSharp 之 WPF 自绘 弹动小球(案例版)
MySQL infrastructure: SQL query statement execution process
MySQL million level data migration practice notes
[semantic segmentation] 2021-pvt2 cvmj
消费电子,冻死在夏天
Summary of window system operation skills
[fortran]vscode配置fortran跑hello world
Second handshake?? Three waves??
10 suggestions for 10x improvement of application performance
Oracle advanced (XIV) explanation of escape characters
跟着田老师学实用英语语法(持续更新)
[HFCTF 2021 Final]easyflask
Hanyuan high tech Gigabit 2-optical 6-conductor rail managed Industrial Ethernet switch supports X-ring redundant ring network one key ring network switch
敏捷开发如何消减协作中的认知偏差?| 敏捷之道
Shell笔记(超级完整)
Where are those test / development programmers in their 30s? a man should be independent at the age of thirty......