当前位置:网站首页>OD-Model【6】:YOLOv2
OD-Model【6】:YOLOv2
2022-08-04 21:00:00 【zzzyzh】
系列文章目录
前言
YOLOv2,即YOLO9000,是一个单阶段的实时物体检测模型。它在几个方面对YOLOv1进行了改进,包括使用Darknet-19作为骨干,批量规范化,使用高分辨率分类器,以及使用锚定框来预测边界框等等。
原论文链接:
YOLO9000: Better, Faster, Stronger
1. Abstract & Introduction
1.1. Abstract
本文将介绍一个先进的,实时目标检测的网络 YOLO9000,它可以检测超过9000个类别的物体。首先,本文提出了对 YOLO 检测方法的各种改进,既新颖又借鉴了以前的工作。改进后的模型 YOLOv2 在 pascal voc 和 COCO 等标准检测任务上是最先进的。使用一种新颖的多尺度训练方法,相同的 YOLOv2 模型可以在不同的尺寸下运行,在速度和准确性之间提供了一个简单的折中。在 67 FPS 下,YOLOv2 在 VOC 2007 上得到 76.8 mAP。在40帧的FPS下,YOLOv2 获得78.6 mAP,比使用 ResNet 和 SSD 的 Faster RCNN 等最先进的方法表现得更好,同时仍然运行得更快。最后,本文提出了一种联合训练目标检测和分类的方法。利用该方法,本文在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000。本文的联合训练允许YOLO9000预测没有标记检测数据的对象类的检测。我们在ImageNet检测任务上验证我们的方法。YOLO9000在ImageNet检测验证集上获得19.7 mAP,尽管它只有200个类中的44个类的检测数据。在156个不在COCO中的类中,YOLO9000得到16.0 mAP(弱监督)。 。YOLO9000可以实时预测9000多种不同对象类别的检测结果。
1.2. Introduction
通用目标检测应该是快速的、准确的并且能够识别各种各样的物体。由于神经网络的发展,检测网络已经变得越来越快速和准确。然而,大多数检测网络仍然受限于很少的物体范围内。
与用于分类和标记等其他任务的数据集相比,当前目标检测数据集是有限的。目标检测数据集通常包含几十万至几百万张图片和几千个类别,而图像分类数据集通常包含几千万张图片和几万个类别。
我们希望检测能扩展到物体分类的级别。然而,用于检测的标签图像比用于分类或标记的标签要昂贵得多。因此,我们不太可能在不久的将来看到与分类数据集相同规模的检测数据集。
本文提出了一种新方法来驾驭我们已有的大量的分类数据,并用它来扩展当前检测系统的范围。本文的方法使用物体分类的分层视图,允许我们将不同的数据集组合在一起。
本文还提出了一种联合训练算法,该算法允许我们既在目标检测数据集上训练,也在图像分类数据集上训练目标检测网络。该的方法利用标记的检测图像来学习精确定位物体,同时使用分类图像来增加其词汇量库(能够识别的类别)和鲁棒性。
2. Better
与先进的检测系统相比,YOLOv1 存在各种缺点。与Fast R-CNN相比,YOLO的错误分析表明YOLOv1 产生了大量的定位误差。 此外,与基于 region proposal(提取候选框的两阶段算法)的方法相比,YOLOv1 具有相对较低的 recall(将所有目标全部检测出来的能力)。 因此,我们主要关注改善 recall 和定位误差,同时保持分类准确性。
计算机视觉通常趋向于更大,更深的网络。更好的性能通常取决于训练更大的网络或集合多个模型。但是,对于 YOLOv2,我们需要更准确的检测,但速度仍然很快。我们没有扩展网络,而是简化网络,然后使特征表示更容易学习。我们将过去工作中的各种想法与我们自己的新思想结合起来,以提高 YOLO 的性能。
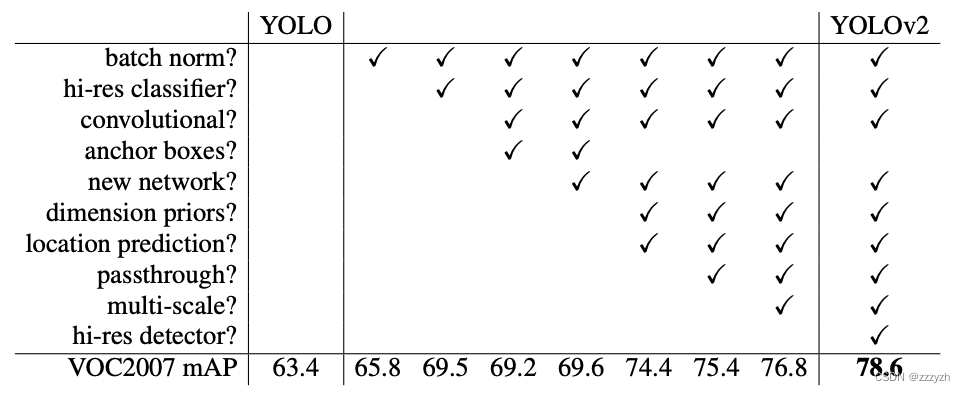
2.1. Batch Normalization
Batch Normalization 使得收敛显着改善,同时消除了对其他形式的正则化的需要。通过在YOLO中的所有卷积层上添加 BN 层,我们可以使mAP提高 2% 以上。BN 层也有助于模型正则化。通过使用 BN 层,我们可以从模型中删除 dropout 而不会过度拟合。
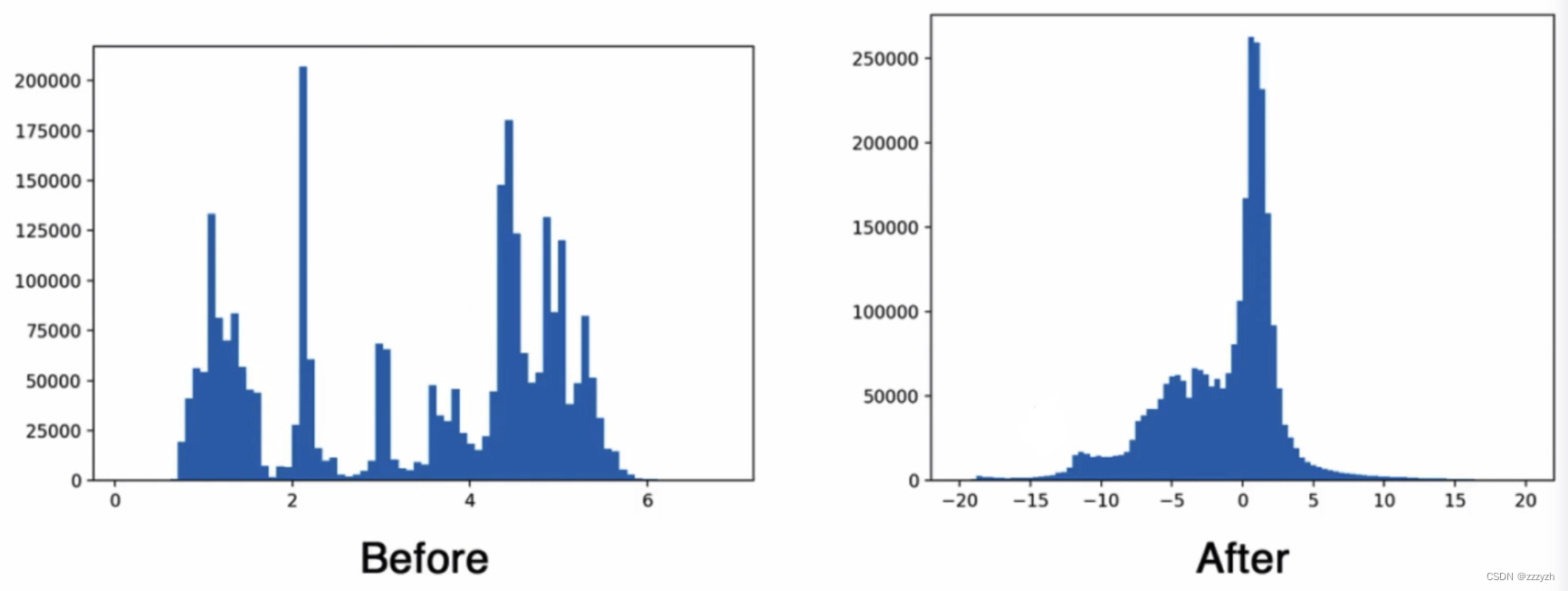
- 正则分布
- 以0为均值,标准差为1的分布
- 大多激活函数在0附近是非饱和区,变化大;两端是饱和区(靠近收敛值),梯度消失,平缓

- 训练阶段
- 每层的每个神经元都会输出一组(batch)响应值,对这组响应值做标准化
- 标准化
- x i ^ = x i − μ σ \hat{x_i} = \frac{x_i - \mu}{\sigma} xi^=σxi−μ
- y i = γ x i ^ + β y_i = \gamma \hat{x_i} + \beta yi=γxi^+β
- 每个神经元都会训练一组 γ , β \gamma, \beta γ,β
- 通过线性变换还原回原始空间,弥补信息丢失
- 标准化
- 将响应转换到0附近,大大加快收敛速度
- 需要注意的是,BN 操作是针对每一个神经元的输出进行标准化,而不是对某一层的输出进行标准化
- 每层的每个神经元都会输出一组(batch)响应值,对这组响应值做标准化
- 测试阶段
- 测试阶段均值、方差、 γ \gamma γ、 β \beta β都在训练阶段的全局求出
- μ t e s t = E ( μ b a t c h ) \mu_{test} = \mathbb{E}(\mu_{batch}) μtest=E(μbatch)
- 对每一组batch的均值求均值,得到全局的均值
- σ t e s t 2 = m m − 1 E ( σ b a t c h 2 ) \sigma^2_{test} = \frac{m}{m-1} \mathbb{E}(\sigma^2_{batch}) σtest2=m−1mE(σbatch2)
- 对每一组batch的方差求均值
- 使用 m m − 1 \frac{m}{m-1} m−1m,无偏估计,求出全局方差
- μ t e s t = E ( μ b a t c h ) \mu_{test} = \mathbb{E}(\mu_{batch}) μtest=E(μbatch)
- Batch Normalization 相当于做线性变换
- B N ( X t e s t ) = γ ⋅ X t e s t − μ t e s t σ t e s t w + ϵ BN(X_{test}) = \gamma \cdot \frac{X_{test} - \mu_{test}}{\sqrt{\sigma^w_{test} + \epsilon }} BN(Xtest)=γ⋅σtestw+ϵXtest−μtest
- 测试阶段均值、方差、 γ \gamma γ、 β \beta β都在训练阶段的全局求出
- 例子
- 在网络中的位置及作用
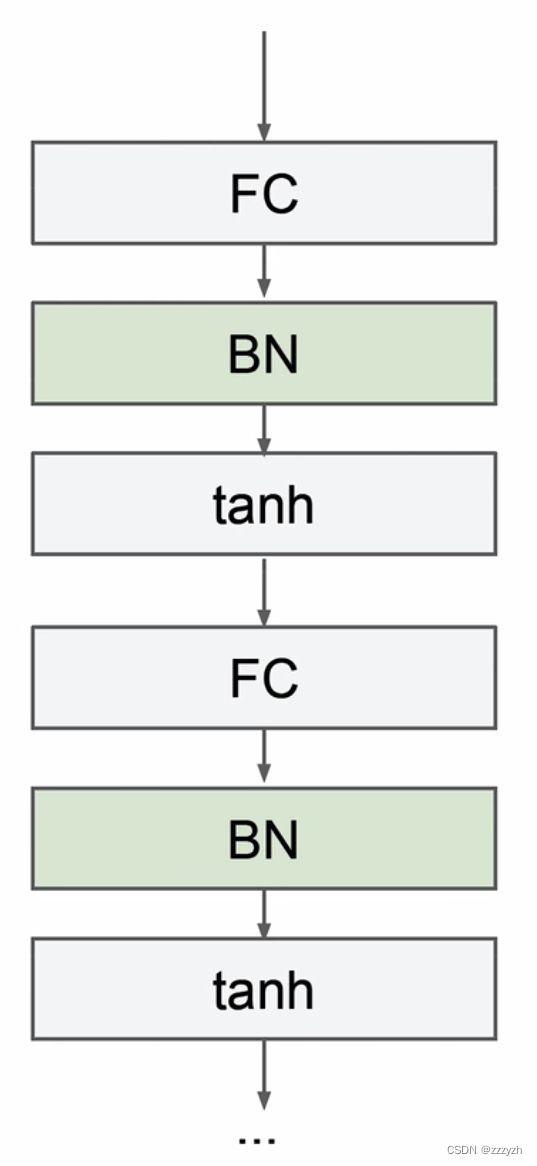
- 通常在线性层的后面、激活层的前面
- 在 YOLOv2 中,在线性层的后面,leaky ReLu激活函数的前面
- 作用
- 让网络更容易训练(加快收敛)
- 改善梯度(让数据远离饱和区)
- 允许使用大学习率
- 对初始化不敏感
- 可以起到正则化的作用
- 需要注意的是,训练和测试的 BN 层不一样
- 与Dropout一起使用效果不好
- 通常在线性层的后面、激活层的前面
2.2. High Resolution Classifie
所有最先进的检测方法都使用在 ImageNet 上预先训练的分类器。原始的 YOLO 训练分类器网络为 224 × 224 224 \times 224 224×224 并增加分辨率为 448 × 448 448 \times 448 448×448 进行检测。这意味着网络必须同时切换到学习目标检测并调整到新的输入分辨率。
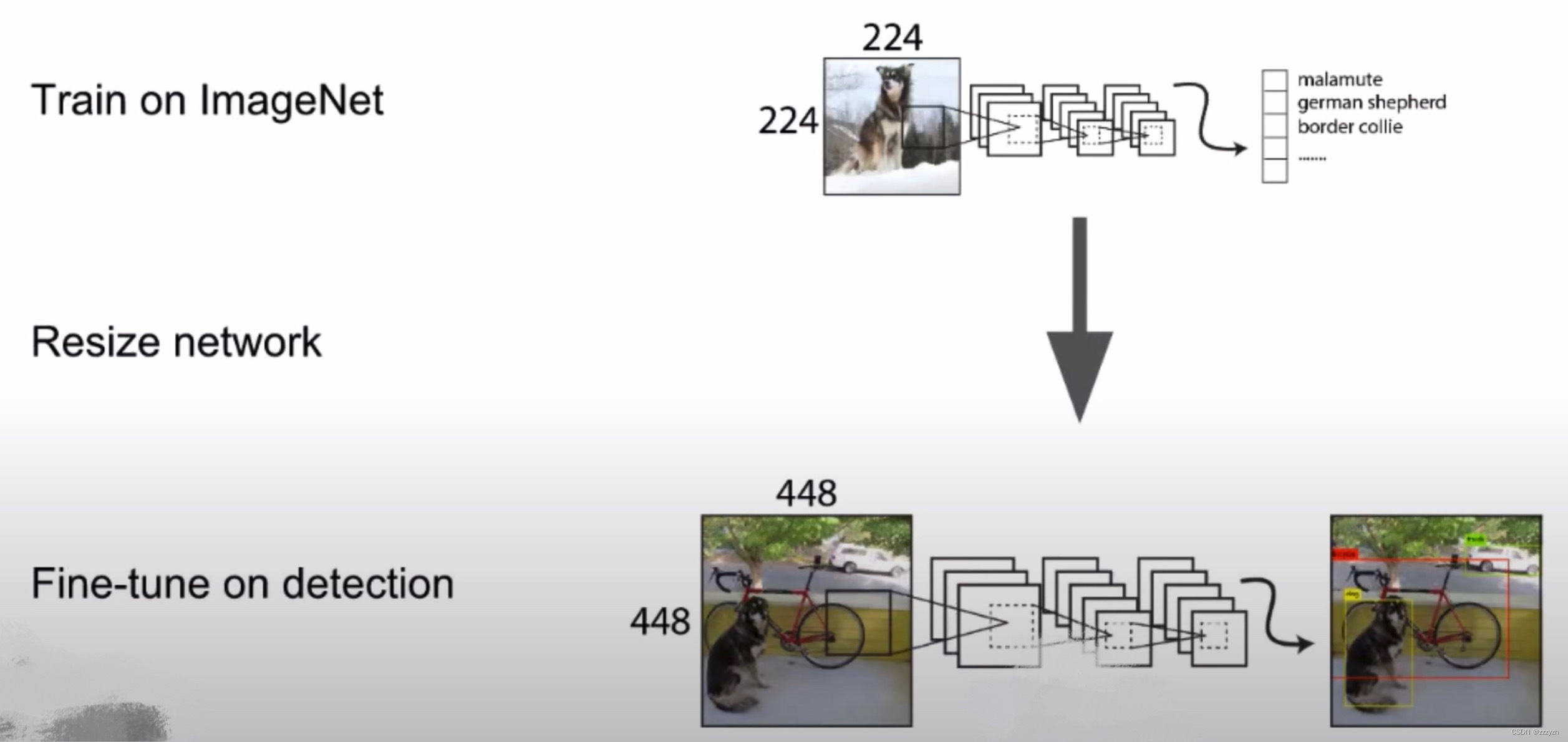
对于YOLOv2,我们首先在 ImageNet 上以完整的 448 × 448 448 \times 448 448×448 分辨率微调分类网络10个 epoch(迭代周期)。这使网络有时间调整其卷积核,以便在更高分辨率的输入上更好地工作。然后我们在检测时对生成的网络进行微调。高分辨率分类网络使我们的 mAP 增加了近4%。
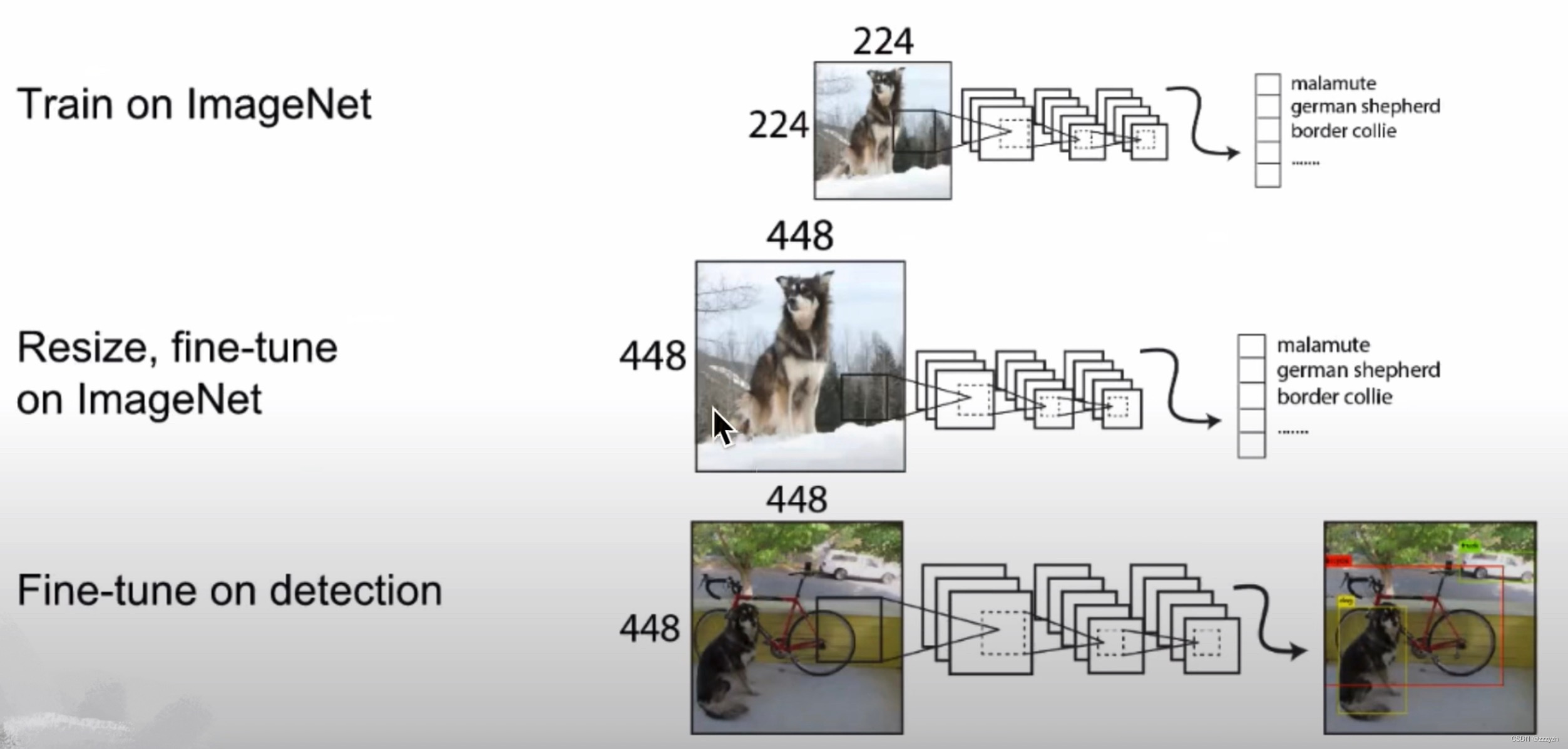
2.3. Convolutional With Anchor Boxes
借鉴Faster RCNN的做法,YOLOv2 也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
每个 grid cell 预测5个大小、长宽比不同的anchor。每个anchor对应一个预测框,而这个预测框只需要预测、输出他相对于他对应的anchor的偏移量。人工标注框的中心点,落在了哪个 grid cell 中,就由哪个 grid cell 产生的 5 个 anchor 中,与该标注框 IOU 最大的anchor去预测,而预测框只需要预测与对应的 anchor 的偏移量即可。
本文移除了YOLO网络中的全连接层并使用anchor boxes来预测边界框。YOLOv2 移除了一个pooling层,使网络卷积层的输出分辨率更高。本文还缩小网络用来在 416 × 416 416 \times 416 416×416 输入图像而不是 448 × 448 448 \times 448 448×448 上操作。这样做是因为我们想要在我们的特征图中有奇数个位置,所以只有一个中心单元格。物体,特别是大物体,往往占据图像的中心,因此最好在中心有一个位置来预测这些物体而不是附近的四个位置。
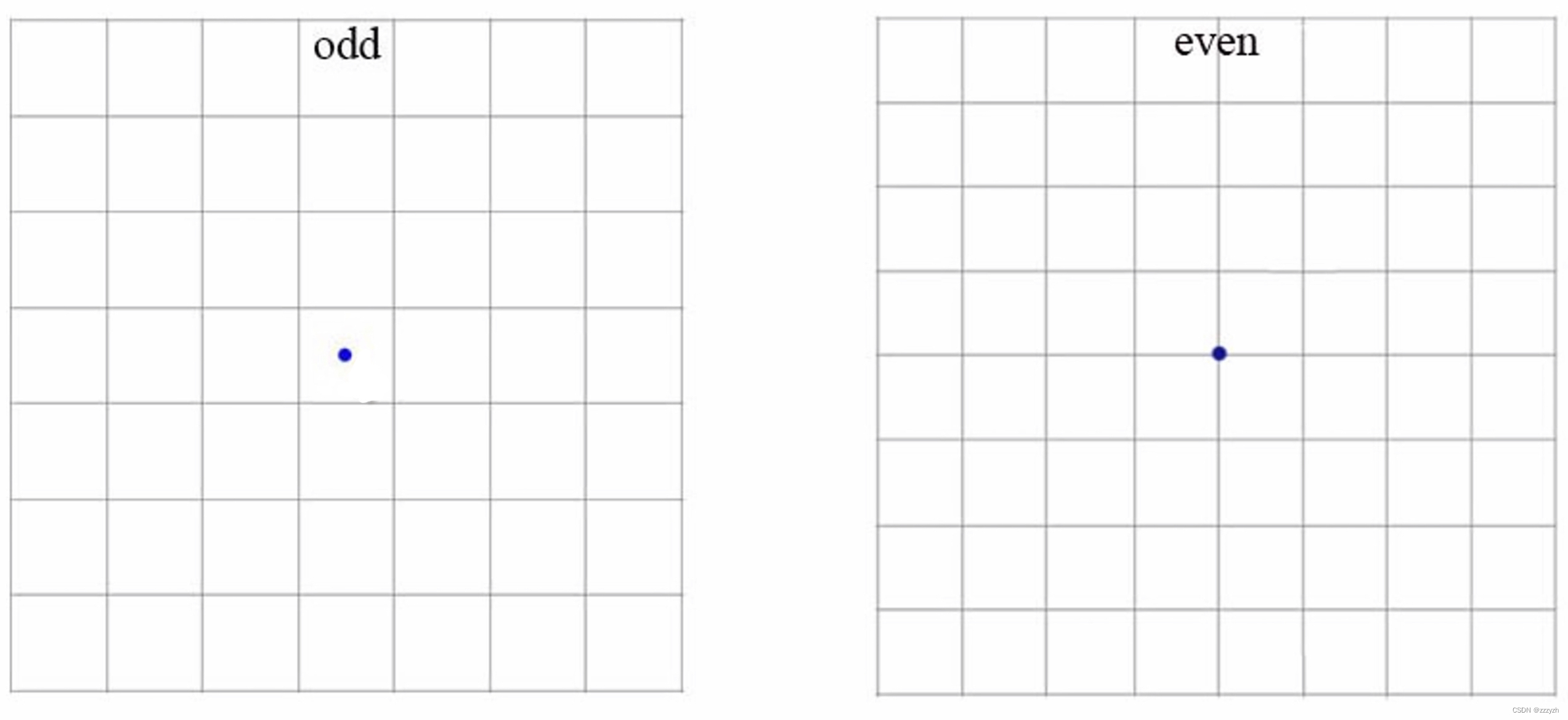
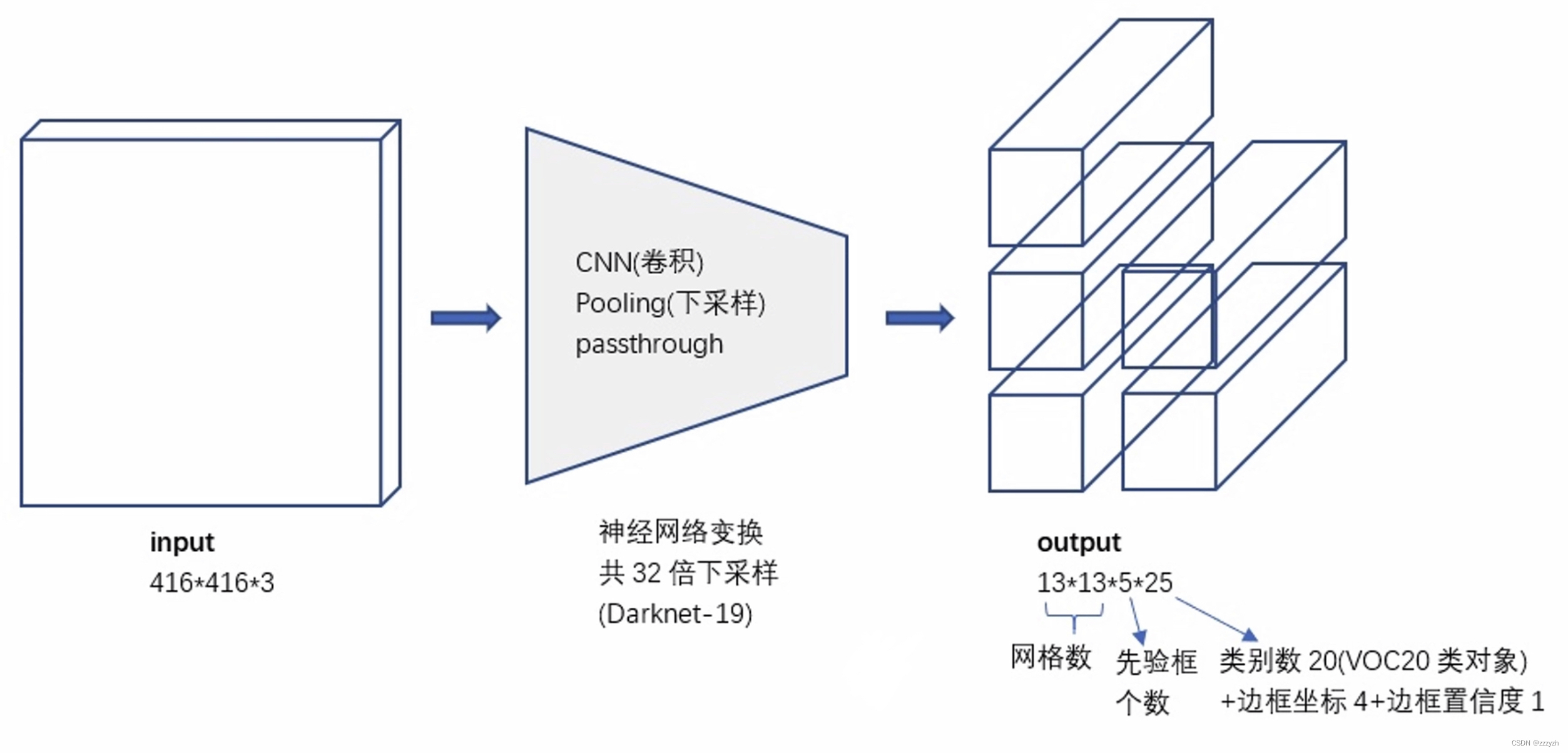
YOLO的卷积层将图像缩小了32倍,因此通过使用 416 × 416 416 \times 416 416×416 的输入图像,我们得到 13 × 13 13 \times 13 13×13 的输出特征图。
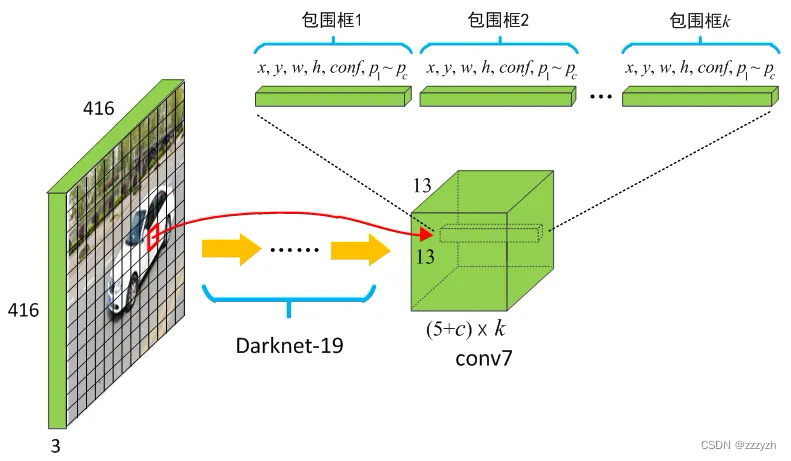
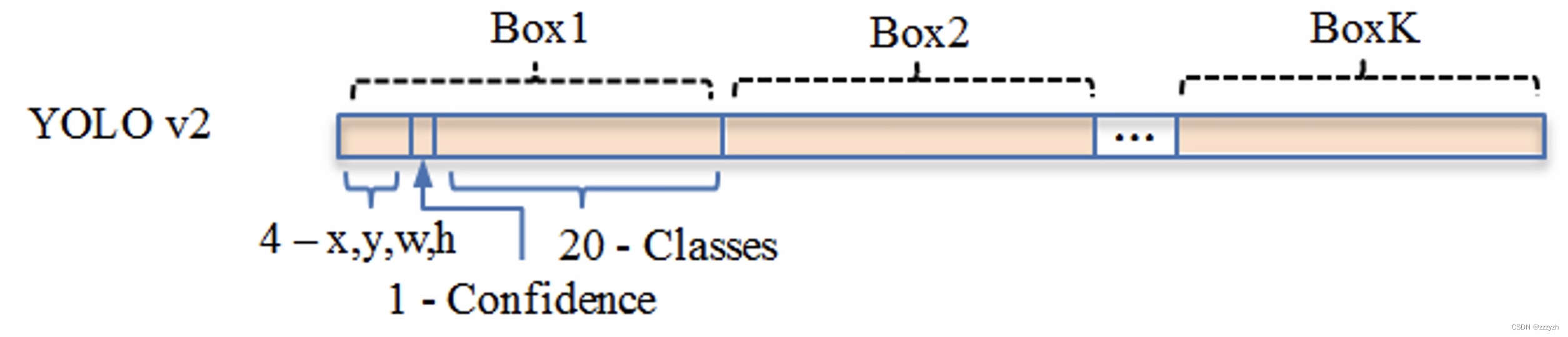
对应的输出,是一个 13 × 13 × 125 13 \times 13 \times 125 13×13×125 的 feature map。原图被划分为13个 grid cell,每个 grid cell 对应 5 个 anchor,每个 anchor 包含 25 个 参数:位置信息(4),置信度(1),概率分布(20)。
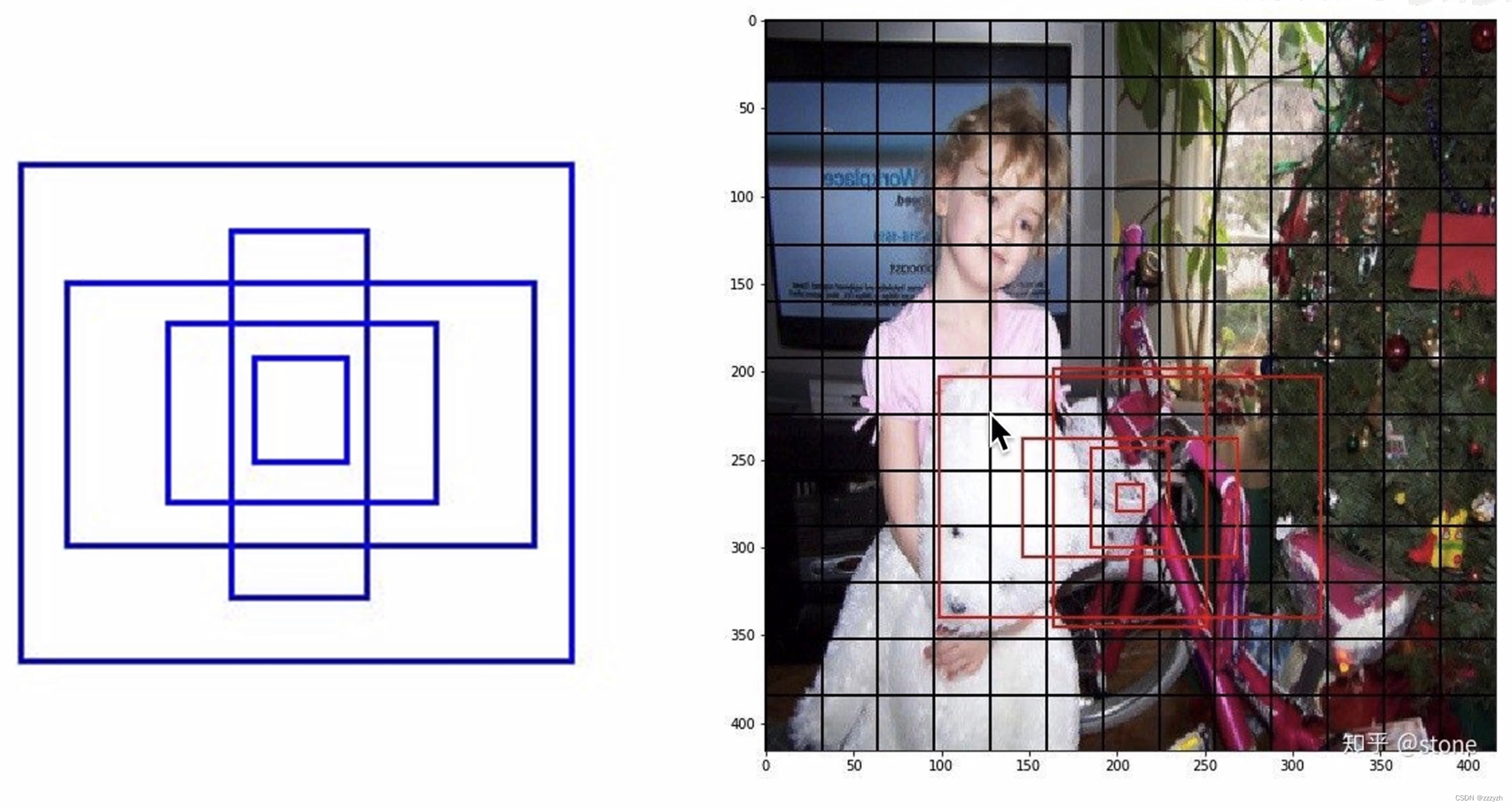
2.4. Dimension Clusters
本文不再手动选择先验,而是在训练集边界框上运行 k-means 聚类,以自动找到好的先验。本文尝试使用具有欧几里德距离的标准 k-means,那么较大的框会产生比较小的框更多的误差。但是,我们真正想要的是能够获得良好IOU分数的先验,这与框 box 的大小无关。 因此,对于我们的距离度量,我们使用:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 - IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
其中,centroid 是聚类时被选作中心的边框,box 就是其它边框,d 就是两者间的距离,IOU 越大,距离越近。聚类中心越多,anchor能覆盖的 IOU 就越大,但是模型也会变得更复杂。在 model 复杂性与 high recall 之间权衡之后,选择聚类分类数 K=5。
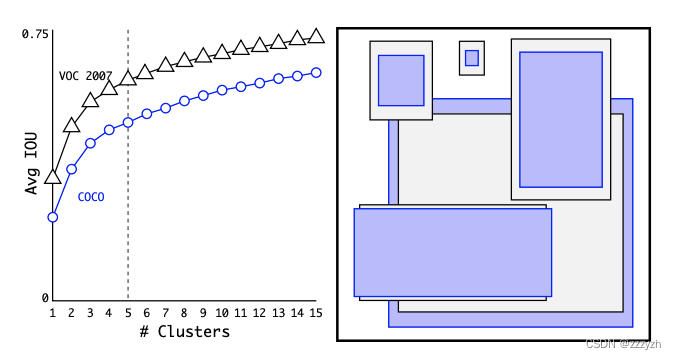
5个 anchor 的长宽比如右图所示,其中黑框是在 PASCAL VOC 2007 上的 anchor 长宽比;蓝框是在 COCO 目标检测数据集中的 anchor 长宽比。
2.5. Direct location prediction
在YOLO网络中使用anchor boxes时,模型不稳定,特别是在早期迭代期间。大多数不稳定性来自于预测box的 ( x , y ) (x, y) (x,y) 位置。在区域提议网络RPN中,网络预测值 t x t_x tx 和 t y t_y ty,并且 ( x , y ) (x, y) (x,y) 中心坐标计算为:
x = ( t x × w a ) + x a y = ( t y × h a ) + y a x = (t_x \times w_a) + x_a \\ y = (t_y \times h_a) + y_a x=(tx×wa)+xay=(ty×ha)+ya
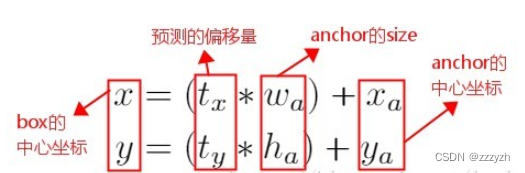
这个公式是不受约束的,因此任何anchor box都可以在图像中的任何位置结束,无论预测box的位置如何。随机初始化,模型需要很长时间才能稳定以预测合理的偏移。
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标 ( C x , C y ) (C_x, C_y) (Cx,Cy) 的相对偏移量,同时为了将 bounding box 的中心点约束在当前网格中,使用逻辑激活函数 sigmoid ( σ \sigma σ) 来约束网络将 t x , t y t_x, t_y tx,ty 进行归一化处理,将值约束在 ( 0 , 1 ) (0, 1) (0,1),这使得模型训练更稳定。
下图为 Anchor box 与 bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box:
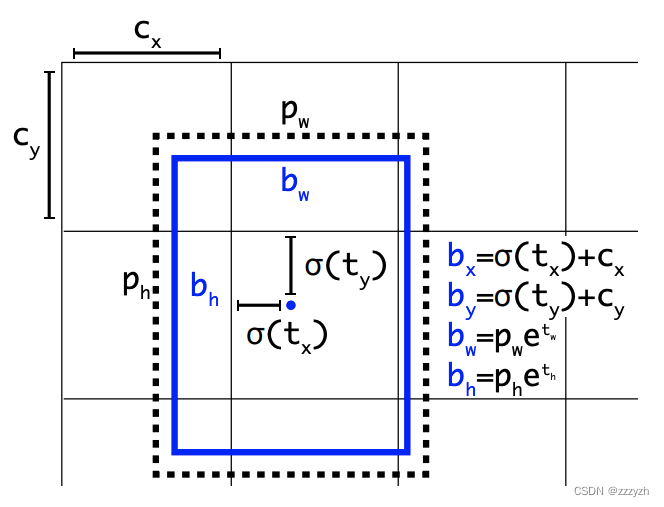
使用 sigmoid 即 σ \sigma σ 函数,将预测框的中心点限制在该框所在的 grid cell 中。同时 grid cell 的大小,也归一化为 1 ∗ 1 1 * 1 1∗1
网络在输出的 feature map 中预测每个单元格的5个边界框。网络预测每个边界框的 5 个坐标,即相对于 anchor 的偏移量, t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th 和 t o t_o to。如果单元格从图像的左上角偏移 ( c x , c y ) (c_x, c_y) (cx,cy) 并且前面的 anchor 具有宽度和高度 p w p_w pw, p h p_h ph,则预测对应于:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_w e^{t_w} \\ b_h = p_h e^{t_h} \\ Pr(object) * IOU(b, object) = \sigma(t_o) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
参数解析:
- c x c_x cx:grid cell 左上角x坐标
- c y c_y cy:grid cell 左上角y坐标
- p w p_w pw:anchor 宽度
- p h p_h ph:anchor 高度
- b x b_x bx:预测框x坐标
- b y b_y by:预测框y坐标
- b w b_w bw:预测框宽度
- b h b_h bh:预测框高度
2.6. Fine-Grained Features
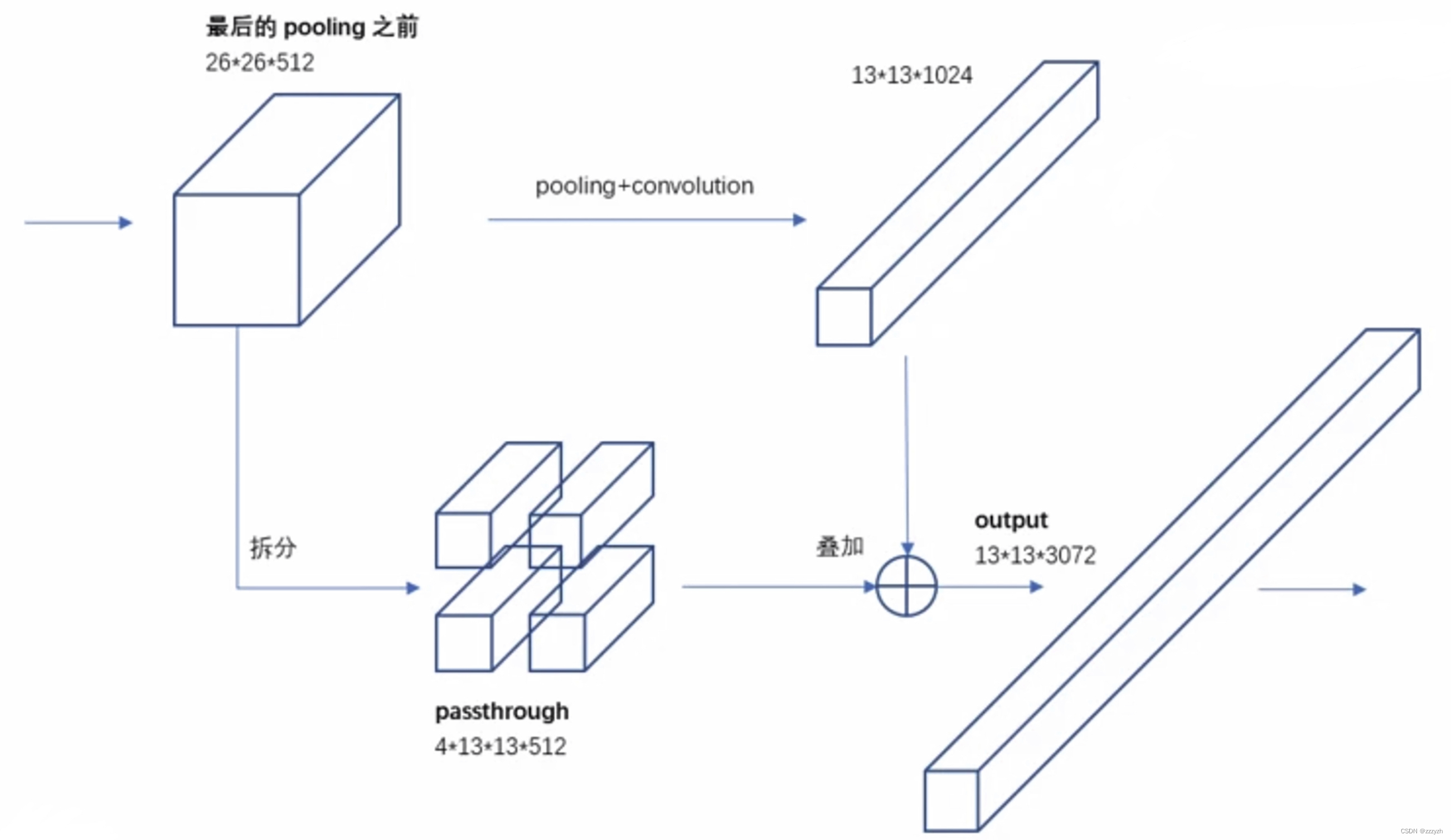
改进后的 YOLO 在 13 ∗ 13 13 * 13 13∗13 特征图上预测检测。我们采用的方法,只需添加一个直通层(passthrough layer),以 26 ∗ 26 26 * 26 26∗26 的分辨率从较早的层中获取特征。
直通层通过将相邻特征堆叠到不同的通道而不是空间位置,将较高分辨率的特征与低分辨率特征连接起来,类似于ResNet中的identity mappings。这将 26 ∗ 26 ∗ 512 26 * 26 * 512 26∗26∗512 特征图转换为 13 ∗ 13 ∗ 2048 13 * 13 * 2048 13∗13∗2048 特征图,可以与原始特征连接。我们的检测器运行在这个扩展的特征图之上,因此它可以访问细粒度的特征。
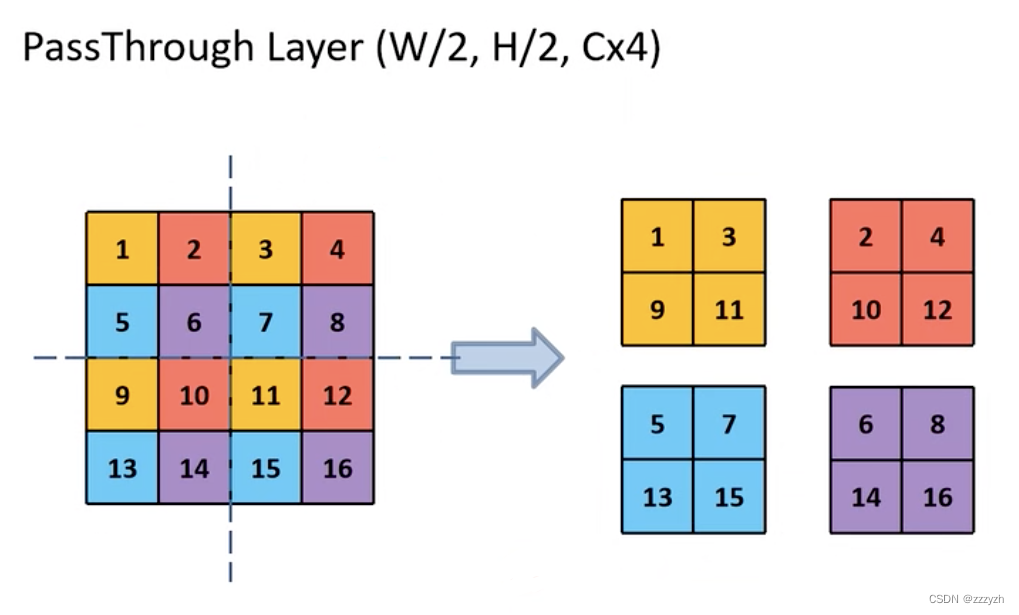
将原本的 feature map 4等分,再从等分的4个小 feature map 的相同位置提取对应的元素到新的 feature map 中,得到了4个新的小 feature map 并连接到一起。对应的,高和宽是原 feature map 的 1/2,而通道数是原来的4倍。
2.7. Multi-Scale Training
最初的YOLO使用输入分辨率为 448 ∗ 448 448 * 448 448∗448。通过添加锚定框,本文将分辨率更改为 416 ∗ 416 416 * 416 416∗416。但是,由于本文使用的模型仅使用卷积和池化层,因此可以动态调整大小。本文希望YOLOv2能够在不同尺寸的图像上鲁棒运行,因此本文将其训练到模型中。
我们并没有固定输入图像的尺寸,而是每隔几次迭代就改变一次网络。每10批(batch)我们的网络随机选择一个新的图像尺寸大小。由于我们的模型下采样率为 32,我们从32的倍数中提取 { 320 ; 352 ; … ; 608 } \{ 320; 352; …; 608 \} { 320;352;…;608}。因此最小的选项是 320 × 320 320 \times 320 320×320,最大的是 608 × 608 608 \times 608 608×608。我们将网络调整到这个维度并继续训练。
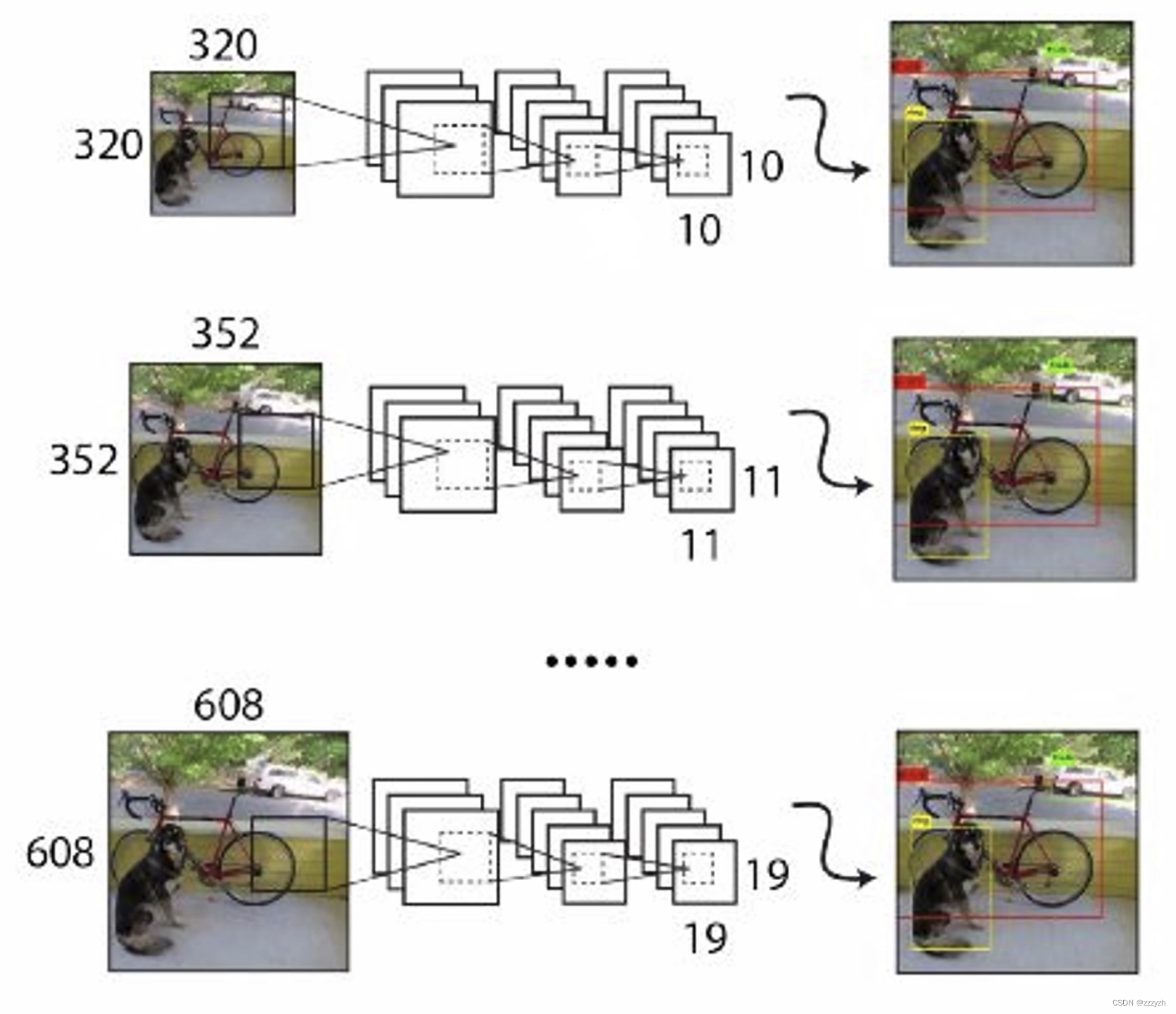
输入小尺寸的图片,预测的会很快,但精度不高;输入大尺寸的图片,预测的会比较慢,但是精度高。所以可以通过输入不同尺寸的图片,来达到速度和精度的权衡。
3. Faster
3.1. Model
3.1.1. Backbone
Darknet - 19(19个卷积层)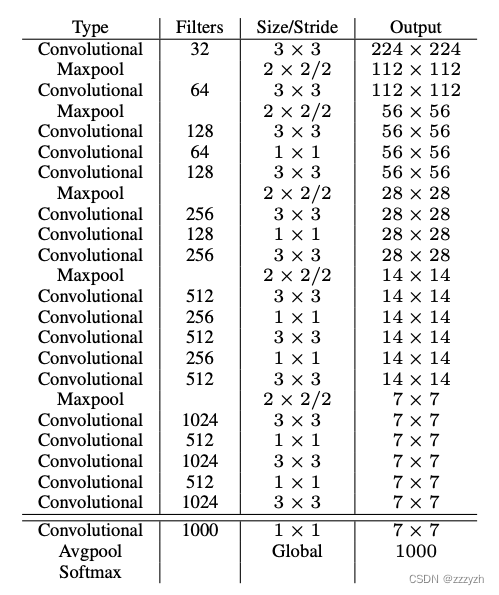
3.1.2. Training for detection
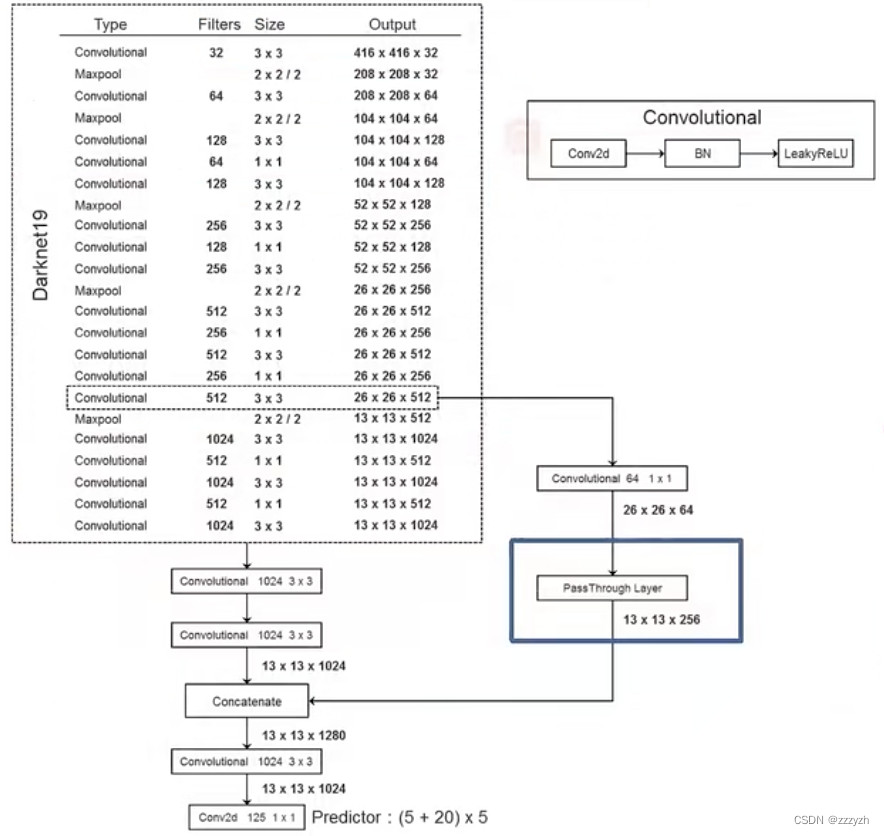
本文通过去掉最后一个卷积层,并在三个 3 × 3 3 \times 3 3×3 卷积层上加上1024个滤波器,每个滤波器后加上最后一个 1 × 1 1 \times 1 1×1 卷积层,再加上需要检测的输出数,来修改该网络进行检测。
参数:
- Filters:卷积核个数
- Size:卷积核大小
- 没有特别说明的话,步长=1,padding = 1
- 有特别说明的话,步长为对应的值
图中所标的所有 Convolutional,均由三部分组成:
- Conv2d
- 不包含偏置
- BN
- Leaky ReLu
- 需要注意的是,最后一层的 Conv2d 并不包含其他层,因为起到是全连接层的作用,进行分类
Pass through层
- 原文中并不存在 1 × 1 1 \times 1 1×1 的卷积层,起到了压缩 feature map 的作用
- 高宽减半,深度变为原来的4倍
- 将 pass through layer 在深度方向上拼接到模型中,就实现了低层特征和高层特征的融合
3.2. Loss
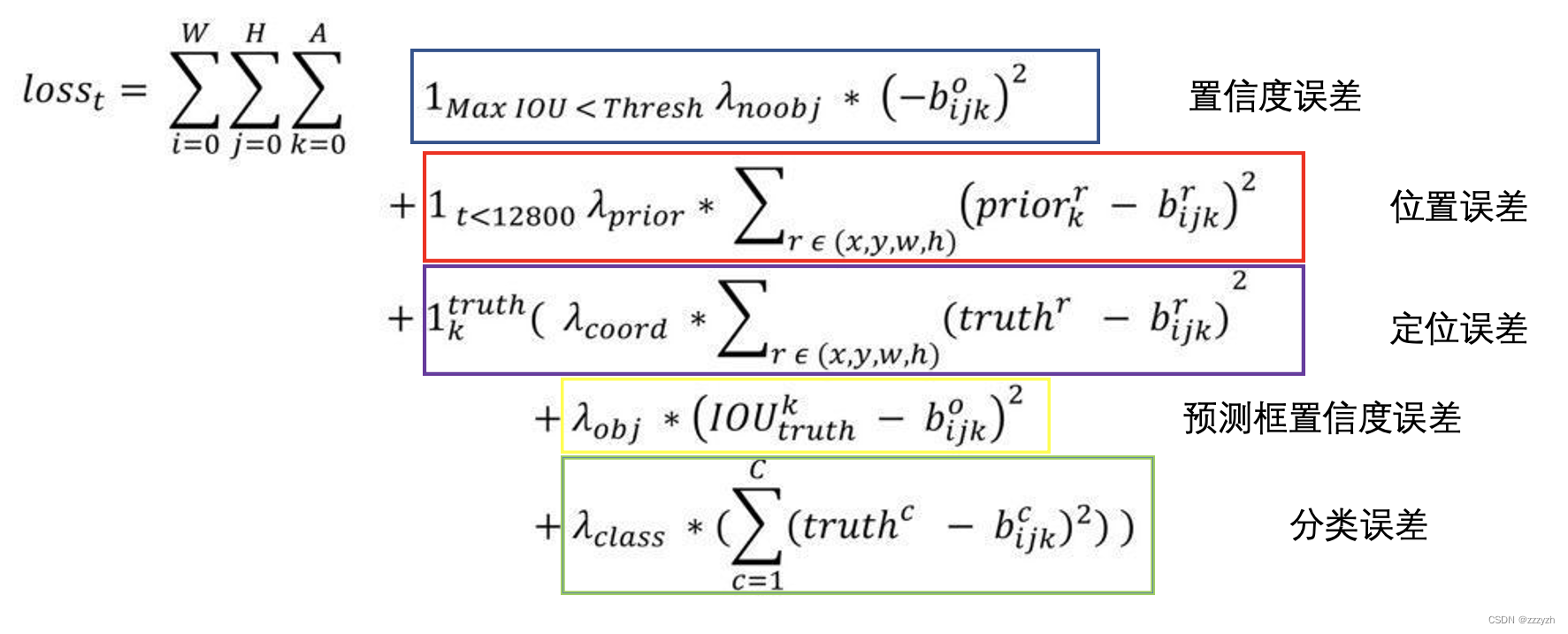
- 置信度误差
- 该预测框对应的是背景
- 越小越好
- 1 M a x ( I O U < T h r e s h ) 1_{Max(IOU < Thresh)} 1Max(IOU<Thresh)
- 非0即1:是否与 GT box 的 I O U < 0.6 IOU < 0.6 IOU<0.6
- IOU计算法:将Anchor与 GT box中心点重合
- 位置误差
- 预测框与 anchor 位置误差,使模型更快学会预测 anchor 位置
- 1 t < 12800 1_{t<12800} 1t<12800
- 非0即1:是否是前12800次迭代
- 负责预测物体的预测框
- 1 k t r u t h 1_k^{truth} 1ktruth
- 非0即1:预测框是否预测物体
- 该 anchor 与 GT box 的 IOU 最大的预测框负责预测物体
- I O U > 0.6 IOU > 0.6 IOU>0.6 但非最大的预测框,忽略其损失
- 定位误差
- 标注框位置 - 预测框位置
- 置信度误差
- anchor与标注框的IOU - 预测框置信度
- 分类误差
- 标注框类别 - 预测框类别
- 1 k t r u t h 1_k^{truth} 1ktruth
总结
总的来说,YOLO2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势。YOLO9000则开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象
边栏推荐
猜你喜欢
Oreo domain name authorization verification system v1.0.6 public open source version website source code

Big capital has begun to flee the crypto space?
xss课堂内容复现

【TypeScript】深入学习TypeScript枚举

How to carry out AI business diagnosis and quickly identify growth points for cost reduction and efficiency improvement?
Matlab画图2

3、IO流之字节流和字符流
![[2022 Hangzhou Electric Multi-School 5 1003 Slipper] Multiple Super Source Points + Shortest Path](/img/78/054329dec6a6faea5e9d583b6a8da5.png)
[2022 Hangzhou Electric Multi-School 5 1003 Slipper] Multiple Super Source Points + Shortest Path
明明加了唯一索引,为什么还是产生了重复数据?
如何最简单、通俗地理解爬虫的Scrapy框架?
随机推荐
【随记】新一天搬砖 --20220727
Comic | Two weeks after the boss laid me off, he hired me back and doubled my salary!
[Teach you to use the serial port idle interrupt of the STM32HAL library]
两种白名单限流方案(redis lua限流,guava方案)
IPV6地址
Zero-knowledge proof - zkSNARK proof system
vim clear last search highlighting
2022-8-4 第七组 ptz 锁与线程池和工具类
帝国CMS仿核弹头H5小游戏模板/92game帝国CMS内核仿游戏网整站源码
【AGC】构建服务1-云函数示例
如何用好建造者模式
3、IO流之字节流和字符流
jekyll adds a flowchart to the blog
宝塔实测-搭建中小型民宿酒店管理源码
Cryptography Series: PEM and PKCS7, PKCS8, PKCS12
run command for node
【学术相关】清华教授发文劝退读博:我见过太多博士生精神崩溃、心态失衡、身体垮掉、一事无成!...
遇到MapStruct后,再也不手写PO,DTO,VO对象之间的转换了
mysql的存储过程介绍、创建、案例、删除、查看「建议收藏」
Oreo domain name authorization verification system v1.0.6 public open source version website source code