当前位置:网站首页>Getting started with scratch
Getting started with scratch
2022-07-25 04:43:00 【HHYZBC】
install scrapy
pip install scrapyscrapy Development process
- Create project
- Generate a reptile :
- Extract the data :
- Save the data :
Create project
establish scrapy The order of the project :
scrapy startproject < Project name >example
scrapy startproject myspiderThe generated directory and file results are as follows :

Create crawler
command :
Execute under the project path :
scrapy genspider < Reptile name > < Domain name allowed to crawl >Reptile name : As a parameter of the crawler runtime
Domain name allowed to crawl : Crawl range set for crawlers , After setting, it is used to filter the url, If you climb and take url If the domain is not allowed, it will be filtered out .
Example :
scrapy genspider itcast itcast.cnThe generated directory and file results are as follows :

Perfect reptiles
stay /myspider/myspider/spiders/itcast.py The content of the modification is as follows :
import scrapy
class ItcastSpider(scrapy.Spider): # Inherit scrapy.spider
# Reptile name
name = 'itcast'
# The range allowed to climb
allowed_domains = ['itcast.cn']
# Starting to climb url Address
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
# Data extraction method , Accept the download middleware response
def parse(self, response):
# scrapy Of response The object can proceed directly xpath
names = response.xpath('//div[@class="tea_con"]//li/div/h3/text()')
print(names)
# The way to get the specific data text is as follows
# grouping
li_list = response.xpath('//div[@class="tea_con"]//li')
for li in li_list:
# Create a data dictionary
item = {}
# utilize scrapy Packaged xpath Selector positioning elements , And pass extract() or extract_first() To get results
item['name'] = li.xpath('.//h3/text()').extract_first() # The teacher's name
item['level'] = li.xpath('.//h4/text()').extract_first() # The level of the teacher
item['text'] = li.xpath('.//p/text()').extract_first() # Teacher's introduction
print(item)Be careful :
- scrapy.Spider Reptiles must be named parse Parsing
- If the structure of the website is complex , You can also customize other parsing functions
- Extracted from the analytic function url Address if you want to send a request , Must belong to allowed_domains Within the scope of , however start_urls Medium url The address is not subject to this restriction
- When starting the crawler, pay attention to the starting position , It's started in the project path
- parse() Use in a function yield Return the data , Be careful : In analytic functions yield The only objects that can be passed are :BaseItem, Request, dict, None
Locate elements and extract data 、 Method of attribute value
- response.xpath Method returns a similar result list The type of , It includes selector object , The operation is the same as the list , But there are some extra ways
- Additional methods extract(): Returns a list of strings
- Additional methods extract_first(): Returns the first string in the list , The list is empty and does not return None
response Common properties of response objects
- response.url: Currently responding to url Address
- response.request.url: The current response to the corresponding request url Address
- response.headers: Response head
- response.requests.headers: The request header of the current response
- response.body: Response body , That is to say html Code ,byte type
- response.status: Response status code
Save the data
stay pipelines.py Operations on data are defined in the file
- Define a pipe class
- Override the process_item Method
- process_item The method is finished item And then it has to go back to the engine
It should be noted that , After the definition is completed, the pipeline also needs to configure the application
stay settings.py Configure enable pipeline
ITEM_PIPELINES = {
'myspider.pipelines.ItcastPipeline': 400
} The key in the configuration item is the pipe class used , Use of pipeline . Segmentation , The first is the project directory , The second is the document , The third is the defined pipeline class .
The value of the configuration item is the order in which the pipes are used , The smaller the value, the higher the priority , This value is generally set to 1000 within .
function scrapy
command : Execute in the project directory scrapy crawl < Reptile name >
Example :scrapy crawl itcast
边栏推荐
- Introduction to FileStream class of C #
- The United States has launched 337 investigations on a number of Chinese companies: Bubugao is full of lying guns!
- Large screen visual adaptation file
- Docker install MySQL 5.7
- Preparation for Android development in big companies
- MySQL 中RDS 链接数突然上涨怎么查?
- [golang from introduction to practice] stone scissors paper game
- mitt.js:小型事件发布订阅库
- How to use ide tool hhdbcs to create a data table containing 1000 simulated data in Oracle database, and
- Beijing University of Posts and telecommunications | RIS assisted in-house multi robot communication system joint deep reinforcement learning
猜你喜欢

Pyg builds GCN to realize link prediction

IT自媒体高调炫富,被黑客组织盯上,铁定要吃牢饭了…

Zhongchuang computing power won the recognition of "2022 technology-based small and medium-sized enterprises"

If you don't know these 20 classic redis interview questions, don't go to the interview!
![[analysis of GPIO register (crl/crh) configuration of STM32]](/img/63/a7b262e95f1dc74201ace9d411b46f.png)
[analysis of GPIO register (crl/crh) configuration of STM32]

实战|记一次攻防演练打点
Ffmpeg download and installation
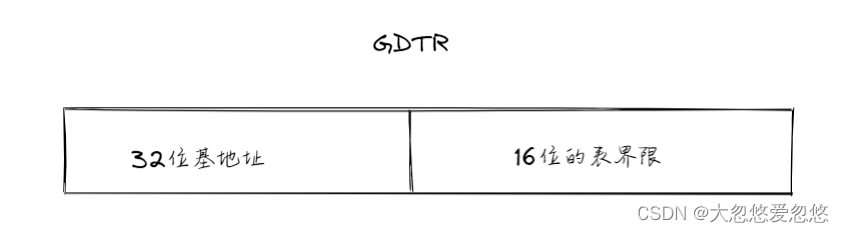
GDT,LDT,GDTR,LDTR

Paper:《Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Condi

运筹学基础【一】 之 导论
随机推荐
Summary of UPR optimization suggestions of unity
The United States has launched 337 investigations on a number of Chinese companies: Bubugao is full of lying guns!
Dry goods | Ctrip Hongmeng application development practice
[sht30 temperature and humidity display based on STM32F103]
Introduction to computing system hardware (common servers)
Market regulation
LVGL 8.2 Textarea
Numpy overview
Unity 之 UPR优化建议汇总
ESWC 2018 | r-gcn: relational data modeling based on graph convolution network
If the development of the metauniverse still follows the development logic of the Internet, and its end point also follows
二、MySQL数据库基础
Ffmpeg download and installation
Sony announced the closure of Beijing mobile phone factory! The production line will be moved to Thailand, and the cost can be reduced by half!
Metinfo function public function getcity() error: XXX function no permission load!!!
2019 telecast retest test questions
MongoDB的安全认证详解
Beijing University of Posts and telecommunications | RIS assisted in-house multi robot communication system joint deep reinforcement learning
Function and technical principle of data desensitization [detailed explanation]
Opencv4.5.x+cuda11.0.x source code compilation and yolov5 acceleration tutorial!