当前位置:网站首页>Thick willow dustpan, thin willow bucket, who hates reptile man? Asynchronous synergism, half a second to strip away a novel
Thick willow dustpan, thin willow bucket, who hates reptile man? Asynchronous synergism, half a second to strip away a novel
2022-07-25 09:26:00 【Ride Hago to travel】
A while ago , I overheard my classmate say , I want to crawl hundreds of thousands of data from XXX website for data analysis , But the speed is too slow , I am very worried about this ... In fact, the common ways to speed up crawlers are multithreading , Multi process , Asynchronous co process, etc , What Xiaobian wants to say is Asynchronous coroutine Speed up the reptile !
The reason why reptiles are slow , Often because the program waits IO And blocked , For example, the common blocking in reptiles is : Network congestion , Disk blocking, etc ; Let's talk about network congestion in detail , If used requests To make a request , If the response speed of the website is too slow , The program has been waiting for the network response , Finally, it leads to extremely low efficiency of reptiles !
So what is asynchronous crawler ?
Generally speaking, it's : When the program detects IO Blocking , It will automatically switch to other tasks of the program , In this way IO To the minimum , There will be more tasks when the program is ready , In order to deceive the operating system , The operating system thinks that the program IO Less , So as to allocate as much as possible CPU, Achieve the purpose of improving the efficiency of program execution .
One , coroutines
import asyncio
import time
async def func1(): # asnyc Define a coroutine
print(' Next to the Lao wang !')
await asyncio.sleep(3) # Analog blocking Asynchronous operations await Wait asynchronously
print(' Next to the Lao wang ')
async def func2(): # asnyc Define a coroutine
print(' Siberian Husky ')
await asyncio.sleep(2) # Analog blocking Asynchronous operations await Wait asynchronously
print(' Siberian Husky ')
async def func3(): # asnyc Define a coroutine
print(' Alaska ')
await asyncio.sleep(1) # Analog blocking Asynchronous operations await Wait asynchronously
print(' Alaska ')
async def main():
tasks = [ # tasks: Mission , It is a further encapsulation of the coroutine object , Contains the various states of the task
asyncio.create_task(func1()),
asyncio.create_task(func2()),
asyncio.create_task(func3()),
]
await asyncio.wait(tasks)
if __name__ == '__main__':
start_time = time.time()
asyncio.run(main()) # Start multiple tasks at once ( coroutines )
print(' The process takes time \033[31;1m%s\033[0ms' % (time.time() - start_time))

Two , Asynchronous requests aiohttp And asynchronous write aiofiles
Casually take a few picture link addresses on the Internet as an exercise
import aiohttp
import aiofiles
import asyncio
import os
if not os.path.exists('./Bantu'):
os.mkdir('./Bantu')
async def umei_picture_download(url):
name = url.split('/')[-1]
picture_path = './Bantu/' + name
async with aiohttp.ClientSession() as session: # aiohttp.ClientSession() amount to requests
async with session.get(url) as resp: # or session.post() Send asynchronously
# resp.content.read() Read binary ( video , Pictures, etc ),resp.text() Read the text ,resp.json() read json
down_pict = await resp.content.read() # resp.content.read() amount to requests(xxx).content
async with aiofiles.open(picture_path, 'wb') as f: # aiofiles.open() Open files asynchronously
await f.write(down_pict) # Writing content is also asynchronous , Need to suspend
print(' Crawl the picture to complete !!!')
async def main():
tasks = []
for url in urls:
tasks.append(asyncio.create_task(umei_picture_download(url)))
await asyncio.wait(tasks)
if __name__ == '__main__':
urls = [
'https://tenfei02.cfp.cn/creative/vcg/veer/1600water/veer-158109176.jpg',
'https://alifei03.cfp.cn/creative/vcg/veer/1600water/veer-151526132.jpg',
'https://tenfei05.cfp.cn/creative/vcg/veer/1600water/veer-141027139.jpg',
'https://tenfei03.cfp.cn/creative/vcg/veer/1600water/veer-132395407.jpg'
]
# asyncio.run(main())
loop = asyncio.get_event_loop() # get_event_loop() Method creates an event loop loop
loop.run_until_complete(main()) # Called loop Object's run_until_complete() Method registers the coroutine into the event loop loop in , Then start

3、 ... and , Asynchronous synergetic process takes away a novel in half a second
The object of this time is a novel on a certain degree ,url The address is :http://dushu.baidu.com/pc/detail?gid=4308271440
1, Simply analyze 
Copy URL Address and open the page shown above on the browser , You can see that only a few chapter titles are displayed , When you click to view all , The URL has not changed, but all the chapter titles have been loaded .
So the first reaction is , The chapter title of the novel is probably through AJAX Partially loaded !
f12 Open developer tools , Point to Network Under the XHR On , And click on Check all Button , Here's the picture :

Capture a package , Open it and see. , Here's the picture :
OK, Find the title ! Continue with the details of each chapter
Click on any chapter name , Enter the details page , Look at the package captured by the browser , Here's the picture :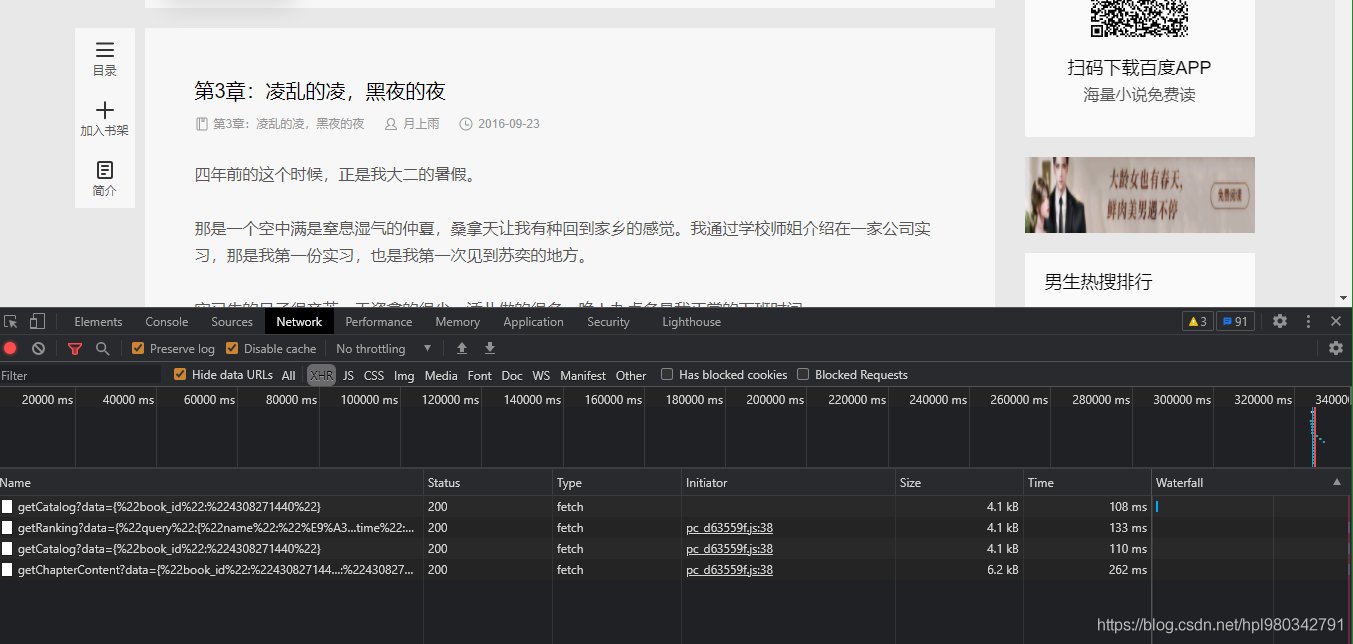
Except for the first bag just now , Look carefully in the other three bags , Is there any trace , Here's the picture 
Chapter details have been found !!!
2, Start rolling code
Before starting, put the chapter title corresponding to url The address corresponds to the chapter details page url Take the address and have a look
The chapter title corresponds to url Address :
# http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%224308271440%22}
The chapter details page corresponds to url Address :
# http://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%224308271440%22,%22cid%22:%224308271440|20222925%22,%22need_bookinfo%22:1}
forehead , This is a certain degree !url Although it's a little messy, it's so messy , But still can't get rid of the fate of being picked , Here's the picture :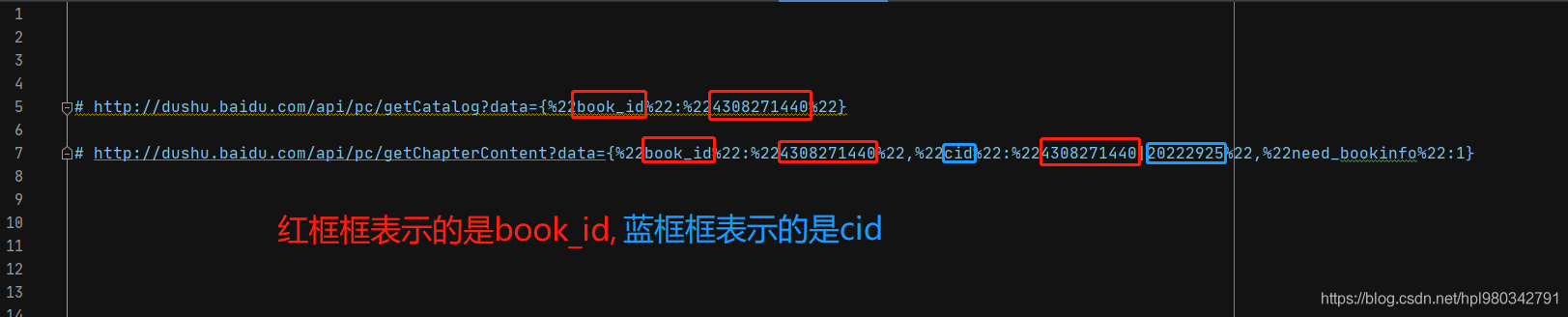
You can see , Two url They all use book_id, So will book_id Extract it separately
① Let's start with a basic frame
import aiohttp
import asyncio
import requests
import aiofiles
import pprint
import os
import time
def get_chapter_content(url, headers):
pass
if __name__ == '__main__':
book_id = '4308271440'
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22' + book_id + '%22}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
get_chapter_content(url, headers)
② Get the chapter name and the corresponding cid
Read out the corresponding json file
def get_chapter_content(url, headers):
response = requests.get(url=url, headers=headers).json()
pprint.pprint(response)
The operation is as follows :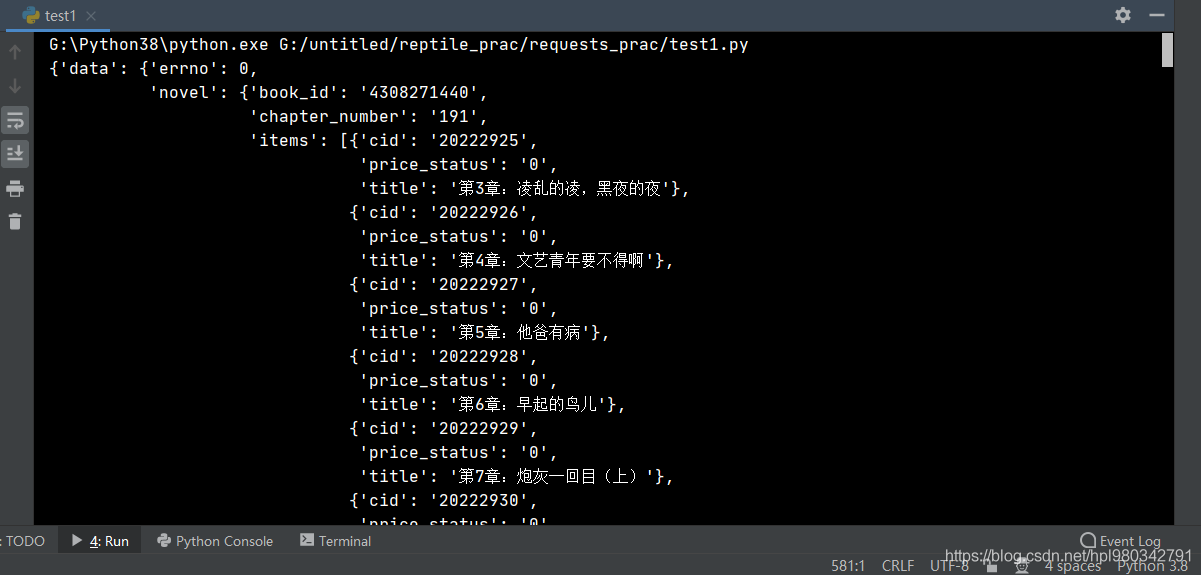
Take out cid and title
def get_chapter_content(url, headers):
response = requests.get(url=url, headers=headers).json()
# pprint.pprint(response)
chapter_details = response['data']['novel']['items'] # Getting contains every chapter cid And chapter name
for chapter in chapter_details:
chapter_cid = chapter['cid'] # Get the corresponding cid
chapter_title = chapter['title'] # Get the title corresponding to each chapter
print(chapter_cid, chapter_title)

③ Upper asynchronous
async def get_chapter_content(url, headers):
response = requests.get(url=url, headers=headers).json()
# pprint.pprint(response)
tasks = []
chapter_details = response['data']['novel']['items'] # Getting contains every chapter cid And chapter name
for chapter in chapter_details:
chapter_cid = chapter['cid'] # Get the corresponding cid
chapter_title = chapter['title'] # Get the title corresponding to each chapter
# print(chapter_cid, chapter_title)
tasks.append(asyncio.create_task(aio_download_novel(headers, chapter_cid, chapter_title, book_id)))
await asyncio.wait(tasks)
async def aio_download_novel(headers, chapter_cid, chapter_title, book_id):
pass
if __name__ == '__main__':
book_id = '4308271440'
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22' + book_id + '%22}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
asyncio.run(get_chapter_content(url, headers))
④ Take out the details
async def aio_download_novel(headers, chapter_cid, chapter_title, book_id):
details_url = 'http://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%22' + book_id + '%22,%22cid%22:%22' + book_id + '|' + chapter_cid + '%22,%22need_bookinfo%22:1}'
# print(details_url)
async with aiohttp.ClientSession() as session:
async with session.get(url=details_url, headers=headers) as response:
content = await response.json()
# pprint.pprint(content)
details_content = content['data']['novel']['content']
print(details_content)

⑤ Persistent storage
import aiohttp
import asyncio
import requests
import aiofiles
import pprint
import os
import time
if not os.path.exists('./ Don't make cannon fodder, sister '):
os.mkdir('./ Don't make cannon fodder, sister ')
async def get_chapter_content(url, headers):
response = requests.get(url=url, headers=headers).json()
# pprint.pprint(response)
tasks = []
chapter_details = response['data']['novel']['items'] # Getting contains every chapter cid And chapter name
for chapter in chapter_details:
chapter_cid = chapter['cid'] # Get the corresponding cid
chapter_title = chapter['title'] # Get the title corresponding to each chapter
# print(chapter_cid, chapter_title)
tasks.append(asyncio.create_task(aio_download_novel(headers, chapter_cid, chapter_title, book_id)))
await asyncio.wait(tasks)
async def aio_download_novel(headers, chapter_cid, chapter_title, book_id):
details_url = 'http://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%22' + book_id + '%22,%22cid%22:%22' + book_id + '|' + chapter_cid + '%22,%22need_bookinfo%22:1}'
# print(details_url)
novel_path = './ Don't make cannon fodder, sister /' + chapter_title
async with aiohttp.ClientSession() as session:
async with session.get(url=details_url, headers=headers) as response:
content = await response.json()
# pprint.pprint(content)
details_content = content['data']['novel']['content']
# print(details_content)
async with aiofiles.open(novel_path, mode='w', encoding='utf-8') as f:
await f.write(details_content)
print(chapter_title, '\033[31;1m Crawling is complete !!!\033[0m')
if __name__ == '__main__':
book_id = '4308271440'
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22' + book_id + '%22}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
start_time = time.time()
asyncio.run(get_chapter_content(url, headers))
print('\n')
print(' Crawlers take a lot of time : \033[31;1m%s\033[0m s' % (time.time() - start_time))


To this end !
边栏推荐
- OverTheWire-Natas
- Programmers can't SQL? Ashes Engineer: all waiting to be eliminated! This is a must skill!
- idea中将lib目录下的jar包加入到项目中
- 多态和接口
- ActiveMQ -- JDBC with persistent mechanism
- MySQL appends a string to the string of a field in the table [easy to understand]
- [selected] from simple to deep, you will understand MQ principles and application scenarios
- Silicon Valley class lesson 11 - official account news and wechat authorization
- What is the difference between mongodb and redis
- MySQL的索引、视图与事务
猜你喜欢
Ten thousand words long, one word thoroughly! Finally, someone has made business intelligence (BI) clear
Unable to start debugging on the web server, the web server failed to find the requested resource

Do you know these methods of MySQL database optimization?

Silicon Valley classroom lesson 12 - official account on demand course and live broadcast management module

activemq--消息重试机制

Bi business interview with data center and business intelligence (I): preparation for Industry and business research

Publish Yum private server using nexus3 (offline intranet)
【Nacos】NacosClient在服务注册时做了什么

Idea hot deployment

Common tool classes under JUC package
随机推荐
sqli-labs安装 环境:ubuntu18 php7
C#语言和SQL Server数据库技术
Click to hide the column in wechat applet, and then click to show it
BigDecimal 对数据进行四舍五入
C#语言和SQL Server数据库技术
[SCADA case] myscada helps VIB company realize the modernization and upgrading of production line
[arm] Xintang nuc977 transplants wk2124 drive
Network principle (2) -- network development
Numpy - 数组array的构造
activemq--可持久化机制之AMQ
MongoDB数据库文件的读与写
activemq--消息重试机制
『怎么用』装饰者模式
数据预处理
什么是贫血模型和充血模型?
数据查询语言(DQL)
数据控制语言(DCL)
Bi business interview with data center and business intelligence (I): preparation for Industry and business research
【Nacos】NacosClient在服务注册时做了什么
OverTheWire-Bandit