当前位置:网站首页>Prediction of red wine quality by decision tree
Prediction of red wine quality by decision tree
2022-06-28 13:28:00 【Hedgehog baby machao】
% Import excel data
filename="D:\Matlab\bin\ Homework \B topic The attachment 1.xlsx";
Title=[" Non volatile acid content "," Volatile acid content "," Citric acid "," Sugar content "," Chloride "," Free sulfur dioxide "," Total sulfur dioxide "," density ","PH value "," Sulfates "," alcohol "];
xlswrite(filename,Title);
[data,top,all]=xlsread(filename);
[data1,top1,all1]=xlsread(filename,' Data set to be predicted ');
%------------------------------------------------------------------------------------------------------------------------------------
% Data sets are preprocessed
%rmmissing Delete missing value processing
list=rmmissing(data);
list1=rmmissing(data1);
% normalization z-score Standardized treatment
R = zscore(list);
%-------------------------------------------------------------------------------------------------------------------------------------
% Randomly generated training set / Test set
P=randperm(3867);
Train =list(P(1:3000),:);
rest=list(P(3001:end),:);
% Training data
P_Train=Train(:,1:11);
T_Train=Train(:,12);
% Test data
P_rest=rest(:,1:11);
T_rest=rest(:,12);
% Create a decision tree classifier
ctree=ClassificationTree.fit(P_Train,T_Train);
% View decision tree view
view(ctree);
view(ctree,'mode','graph');
% The simulation test
T_sim=predict(ctree,P_rest);
%V. Result analysis
count_3= length(find(T_Train == 3));rate_3=count_3/3700;total_3=length(find(list(:,12)==3));
count_4= length(find(T_Train == 4));rate_4=count_4/3700;total_4=length(find(list(:,12)==4));
count_5= length(find(T_Train == 5));rate_5=count_5/3700;total_5=length(find(list(:,12)==5));
count_6= length(find(T_Train == 6));rate_6=count_6/3700;total_6=length(find(list(:,12)==6));
count_7= length(find(T_Train == 7));rate_7=count_7/3700;total_7=length(find(list(:,12)==7));
count_8= length(find(T_Train == 8));rate_8=count_8/3700;total_8=length(find(list(:,12)==8));
count_9= length(find(T_Train == 9));rate_9=count_9/3700;total_9=length(find(list(:,12)==9));
number_3= length(find(T_rest == 3));number_B3_sim= length(find(T_sim ==3&T_rest == 3));
number_4= length(find(T_rest == 4));number_B4_sim= length(find(T_sim ==4&T_rest == 4));
number_5= length(find(T_rest == 5));number_B5_sim= length(find(T_sim ==5&T_rest == 5));
number_6= length(find(T_rest == 6));number_B6_sim= length(find(T_sim ==6&T_rest == 6));
number_7= length(find(T_rest == 7));number_B7_sim= length(find(T_sim ==7&T_rest == 7));
number_8= length(find(T_rest == 8));number_B8_sim= length(find(T_sim ==8&T_rest == 8));
number_9= length(find(T_rest == 9));number_B9_sim= length(find(T_sim ==9&T_rest == 9));
fprintf(' Total red wine measurement :%d\n',3867);
fprintf(' The quality is 3:%d\n',total_3);
fprintf(' The quality is 4:%d\n',total_4);
fprintf(' The quality is 5:%d\n',total_5);
fprintf(' The quality is 6:%d\n',total_6);
fprintf(' The quality is 7:%d\n',total_7);
fprintf(' The quality is 8:%d\n',total_8);
fprintf(' The quality is 9:%d\n',total_9);
fprintf(' The total number of red wine measurements in the training set :%d\n',3700);
fprintf(' The quality is 3:%d\n',count_3);
fprintf(' The quality is 4:%d\n',count_4);
fprintf(' The quality is 5:%d\n',count_5);
fprintf(' The quality is 6:%d\n',count_6);
fprintf(' The quality is 7:%d\n',count_7);
fprintf(' The quality is 8:%d\n',count_8);
fprintf(' The quality is 9:%d\n',count_9);
fprintf(' The total number of red wine measurements in the test set :%d\n',167);
fprintf(' The quality is 3:%d\n',number_3);
fprintf(' The quality is 4:%d\n',number_4);
fprintf(' The quality is 5:%d\n',number_5);
fprintf(' The quality is 6:%d\n',number_6);
fprintf(' The quality is 7:%d\n',number_7);
fprintf(' The quality is 8:%d\n',number_8);
fprintf(' The quality is 9:%d\n',number_9);
fprintf(' The number of correct quality predictions :%d\n',number_B3_sim+number_B4_sim+number_B5_sim+number_B6_sim+number_B7_sim+number_B8_sim+number_B9_sim);
fprintf(' Wrong number %d\n',number_3+number_4+number_5+number_6+number_7+number_8+number_9-(number_B3_sim+number_B4_sim+number_B5_sim+number_B6_sim+number_B7_sim+number_B8_sim+number_B9_sim));
fprintf(' Accuracy rate p:%f%%\n',(number_B3_sim+number_B4_sim+number_B5_sim+number_B6_sim+number_B7_sim+number_B8_sim+number_B9_sim)/(number_3+number_4+number_5+number_6+number_7+number_8+number_9)*100);
%. The influence of the minimum number of samples contained in leaf nodes on the performance of decision tree
leafs= logspace(1,2,10);
N= numel(leafs);
err= zeros(N,1);
for n= 1:N
t= ClassificationTree.fit(P_Train,T_Train,'crossval','on','minleaf',leafs(n));
err(n)= kfoldLoss(t);
end
plot(leafs,err);
xlabel(' The minimum number of samples contained in leaf nodes ');
ylabel(' Cross validation error ');
title(' The influence of the minimum number of samples contained in leaf nodes on the performance of decision tree ');
% Set up minleaf by 10, Generate optimization decision tree
OptimalTree=ClassificationTree.fit(P_Train,T_Train,'minleaf',10);
view(OptimalTree,'mode','graph');
%1. The resampling error and cross validation error of the optimized decision tree are calculated
resubOpt= resubLoss(OptimalTree);
lossOpt= kfoldLoss(crossval(OptimalTree));
%2. The resampling error and cross validation error of the decision tree before optimization are calculated
resubDefault= resubLoss(ctree);
lossDefault= kfoldLoss(crossval(ctree));
%%. prune
[~,~,~,bestlevel]=cvLoss(ctree,'subtrees','all','treesize','min');
cptree= prune(ctree,'Level',bestlevel);
view(cptree,'mode','graph');
%1. The resampling error and cross validation error of the decision tree after pruning are calculated
resubPrune= resubLoss(cptree);
lossPrune= kfoldLoss(crossval(cptree));
%------------------------------------------------------------------------------------------------------------------------------------
% surface 2 data
% Randomly generated training set / Test set
P1=randperm(2000);
Train1 =list(P1(1:1000),:);
rest1=list1(1:1000,:);
% Training data
P_Train1=Train1(:,1:11);
T_Train1=Train1(:,12);
% Test data
P_rest1=rest1(:,1:11);
% Create a decision tree classifier
ctree1=ClassificationTree.fit(P_Train1,T_Train1);
% View decision tree view
view(ctree1);
view(ctree1,'mode','graph');
% The simulation test
T_sim1=predict(ctree1,P_rest1);
%------------------------------------------------------------------------------------------------------------------------------------
% Forward processing steps
[a,b]=size(list);
disp([' share ' num2str(a) ' Two evaluation objects , ' num2str(b-1) ' Evaluation indicators ']);
position = input(' Please enter the column of the indicator that needs forward processing , for example [2,4,5]:');
disp(' Please enter the column indicator type to be processed (1: Very small ,2: The middle type , 3: Interval type )')
type = input(' For example 2 Columns are very small , The first 4 Columns are interval type , The first 5 Columns are intermediate , Input [1,3,2]: ');
% Be careful ,Position and Type Are two row vectors of the same dimension
X=list;
for i = 1 : size(position,2) % These columns need to be treated separately , So we need to know the total number of times to process , That is, the number of cycles
X(:,position(i)) = Positivization(X(:,position(i)),type(i),position(i));
end
disp(' The forward matrix X = ')
disp(X)
weigh=[0.15;0.15;0.1;0.2;0.05;0.05;0.05;0.05;0.01;0.01;0.18];% The weight
R(:,12)=[];
r=R';
D_P = sum(((r(:,1:a)-repmat(max(r(:,1:a)),1,1)) .^2 ) .* repmat(weigh,1,a) ,2) .^ 0.5; % D+ The distance vector from the maximum
D_N = sum(((r(:,1:a)-repmat(min(r(:,1:a)),1,1)) .^2 ) .* repmat(weigh,1,a) ,2) .^ 0.5; % D- The distance vector from the minimum
S = D_N ./ (D_P+D_N); % Non normalized score
disp(' The final score is :');
stand_S = S / sum(S);
[sorted_S,index] = sort(stand_S ,'descend');
disp(index);
Reference function Positivization.m
% function [ Output variables ] = The name of the function ( The input variable )
function [posit_x] = Positivization(x,type,i)
% There are three input variables :
% x: The original column vector corresponding to the indicator that needs forward processing
% type: Types of indicators (1: Very small , 2: The middle type , 3: Interval type )
% i: Which column in the original matrix is being processed
% Output variables posit_x Express : The forward column vector
if type == 1 % Very small
disp([' The first ' num2str(i) ' Columns are very small , Is moving forward '] )
posit_x = max(x) - x;
disp([' The first ' num2str(i) ' Column miniaturization forward processing is complete '] )
disp('-------------------- Demarcation line --------------------')
elseif type == 2 % The middle type
disp([' The first ' num2str(i) ' Columns are intermediate '] )
best = input(' Please enter the best value : ');
M = max(abs(best-x));
posit_x = 1-abs(best-x)/M;
disp([' The first ' num2str(i) ' The forward processing of column intermediate type is completed '] )
disp('-------------------- Demarcation line --------------------')
elseif type == 3 % Interval type
disp([' The first ' num2str(i) ' Columns are interval type '] )
a = input(' Please enter the lower bound of the interval : ');
b = input(' Please enter the upper bound of the interval : ');
r_data = size(x,1);
M = max([a-min(x),max(x)-b]);
posit_x = zeros(r_data,1);
for i = 1:r_data
if x(i)<a
posit_x(i) = 1-(a-x(i))/M;
elseif x(i)>b
posit_x(i) = 1-(x(i)-b)/M;
else
posit_x(i) = 1;
end
end
disp([' The first ' num2str(i) ' Column interval type forward processing completed '] )
disp('-------------------- Demarcation line --------------------')
else
disp(' There are no indicators of this type , Please check Type Is there anything in the vector other than 1、2、3 Other values ')
end
end
边栏推荐
- pytorch主要模块
- [understanding of opportunity -32]: Guiguzi - Dui [x ī] Five attitudes towards danger and problems
- The English translation of heartless sword Zhu Xi's two impressions of reading
- Jeecg 官方组件的使用笔记(更新中...)
- Oracle 云基础设施扩展分布式云服务,为组织提供更高的灵活性和可控性
- 专业英语历年题
- 开源项目维权成功案例: Spug 开源运维平台成功维权
- 恒生电子:金融分布式数据库LightDB通过中国信通院多项测评
- Talk about exception again -- what happens when an exception is thrown?
- Copy 10 for one article! The top conference papers published in South Korea were exposed to be plagiarized, and the first author was "original sin"?
猜你喜欢

The $980000 SaaS project failed

FH511+TP4333组成一个户外移动电源照明野营灯方案。

StackOverflow 2022数据库年度调查

抢做意大利岛主?刘强东两月套现66亿 疑一次性5.6亿“紧急转账”急购欧洲海上皇宫

Yii2 writing the websocket service of swoole

How does Quanzhi v853 chip switch sensors on Tina v85x platform?
How to find opportunities in a bear market?

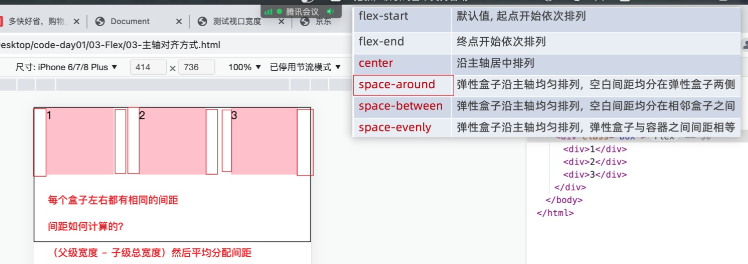
flex布局中的align-content属性

First knowledge of exception
Mobile web training day-1
随机推荐
我呕血收集融合了来自各路经典shell书籍的脚本教学,作为小白的你快点来吧
Forecast and Analysis on market scale and development trend of China's operation and maintenance security products in 2022
Latest summary! 30 provinces announce 2022 college entrance examination scores
Align content attribute in flex layout
G1垃圾收集器中重要的配置参数及其默认值
codeblocks mingw安装配置问题
G1 important configuration parameters and their default values in the garbage collector
Oceanwide micro fh511 single chip microcomputer IC scheme small household appliances LED lighting MCU screen printing fh511
Notes on the use of official jeecg components (under update...)
c语言中的类结构体-点号
How to solve the data inconsistency between redis and MySQL?
真香啊!最全的 Pycharm 常用快捷键大全!
Fs7022 scheme series fs4059a dual two lithium battery series charging IC and protection IC
Solution to directory access of thinkphp6 multi-level controller
Pytorch main modules
移动Web实训DAY-2
Centos7——安装mysql5.7
专业英语历年题
How vscade sets auto save code
plt.savefig()的用法以及保存路径