当前位置:网站首页>Xception学习笔记
Xception学习笔记
2022-07-01 02:24:00 【麻花地】
Xception学习笔记
原文地址:Xception: Deep Learning with Depthwise Separable Convolutions
概述
整个inception结构主导思想是分解和解耦

效果


引入深度可分离卷积


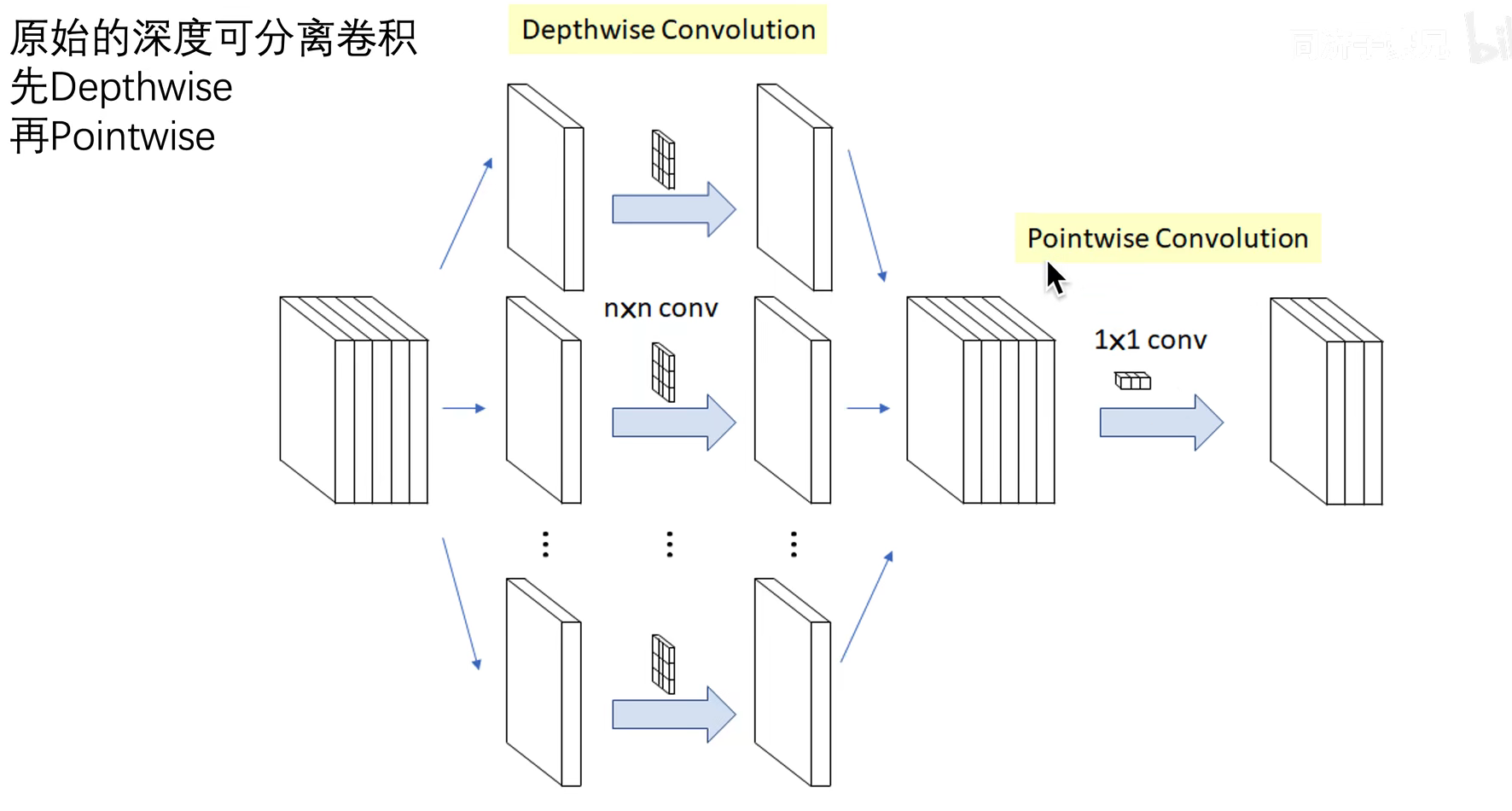
Inception系列回顾
V1



V1-V3




第四层简化也叫组卷积

第四层简化之后使用组卷积使得每个3x3卷积处理一个通道,极致版本等同深度可分离卷积



原文精读

Abstract
我们将卷积神经网络中的Inception modules解释为正则卷积和深度可分离卷积运算(深度卷积后接点卷积)之间的中间步骤(Inception结构是介于传统卷积和深度可分离卷积的中间形态,Xception彻底解耦为深度可分离卷积)。从这个角度来看,深度可分离卷积可以理解为具有最大数量塔的Inception modules。这一观察结果引导我们提出了一种新的深卷积神经网络结构,其灵感来自于初始阶段,Inception modules已被深度可分离卷积所取代。我们表明,这种被称为Exception的体系结构在ImageNet数据集上的性能略优于Inception V3(Inception V3是为该数据集设计的),在包含3.5亿张图像和17000个类的较大图像分类数据集上的性能明显优于Inception V3。由于Exception体系结构的参数数量与Inception V3相同,因此性能的提高不是由于容量的增加,而是由于模型参数的更有效使用。 (inceptionV3和Xception参数量相近,Xception的性能提升仅取决于参数效率提升)
1. Introduction
近年来,卷积神经网络已成为计算机视觉的主要算法,开发设计卷积神经网络的方法一直是一个备受关注的课题。卷积神经网络设计的历史始于LeNet风格的模型【10】,这是用于特征提取的简单卷积堆栈和用于空间子采样的最大池运算。2012年,这些想法被细化到AlexNet架构中【9】,在最大池操作之间,卷积操作被重复多次,从而允许网络在每个空间尺度上学习更丰富的特征。随之而来的是一种趋势,即这种类型的网络越来越深入,主要是由每年的ILSVRC竞争所驱动;首先是2013年与Zeiler和Fergus合作【25】,然后是2014年与VGG架构合作【18】。
此时,出现了一种新的网络样式,即Inception架构,由Szegedy等人于2014年【20】引入,称为GoogLeNet(Inception V1),后来被改进为Inception V2【7】、Inception V3【21】和最近的Inception ResNet【19】。《盗梦空间》本身的灵感来自早期的NetworkIn网络架构【11】。自首次推出以来,Inception一直是ImageNet数据集(14)上性能最好的模型系列之一,也是Google使用的内部数据集,尤其是JFT(5)。
Inception样式模型的基本构建块是Inception模块,其中存在几个不同的版本。在图1中,我们展示了Inception模块的规范形式,如Inception V3体系结构中所示。初始模型可以理解为此类模块的堆栈。这与早期VGG风格的网络不同,后者是简单卷积层的堆栈。
虽然Inception modules在概念上类似于卷积(它们是卷积特征提取器),但从经验上看,它们似乎能够用较少的参数学习更丰富的表示。它们是如何工作的,它们与常规卷积有什么区别?《盗梦空间》之后的设计策略是什么?
1.1. The Inception hypothesis
卷积层尝试在3D空间中学习滤波器,具有2个空间维度(宽度和高度)和一个通道维度;因此,单个卷积核的任务是同时映射交叉信道相关性和空间相关性。 (Inception的设计哲学是解耦)
Inception模块背后的想法是,通过将其明确分解为一系列操作,使这一过程更容易、更高效,这些操作将独立查看跨通道相关性和空间相关性。更准确地说,典型的Inception modules首先通过一组1x1卷积来查看交叉信道相关性,将输入数据映射到比原始输入空间小的3或4个独立空间中,然后通过规则的3x3或5x5卷积映射这些较小3D空间中的所有相关性。这如图1所示。实际上,《盗梦空间》背后的基本假设是,跨通道相关性和空间相关性充分解耦,最好不要将它们联合映射。
考虑一个Inception modules的简化版本,它只使用一种卷积大小(例如3x3),不包括平均池塔(图2)。这个Inception modules可以重新表示为一个大的1x1卷积,然后是空间卷积,它将在输出通道的非重叠段上运行(图3)。这一观察结果自然提出了一个问题:分区中的段数(及其大小)的影响是什么?提出一个比初始假设强得多的假设,并假设跨通道相关性和空间相关性可以完全分开映射,这合理吗?



1.2. The continuum between convolutions and separable convolutions
基于这一更强假设的Inception modules的“极端”版本将首先使用1x1卷积映射交叉信道相关性,然后分别映射每个输出信道的空间相关性。如图4所示。我们注意到,Inception modules的这种极端形式几乎等同于深度可分离卷积,这是一种用于神经网络的运算 设计早在2014年就开始了【15】,自2016年被纳入TensorFlow框架【1】以来,网络设计变得更加流行。

深度可分离卷积,在TensorFlow和Keras等深度学习框架中通常称为“可分离卷积”,包括深度卷积,即在输入的每个通道上独立执行的空间卷积,然后是点式卷积,即1x1卷积,将深度卷积输出的信道投影到新的信道空间。这不能与空间可分离卷积相混淆,空间可分离卷积在图像处理界也称为“可分离卷积”。
Inception modules和深度可分离卷积的“极端”版本之间的两个细微区别是:
1)操作顺序:通常执行的深度可分离卷积(例如在TensorFlow中)首先执行通道方向的空间卷积,然后执行1x1卷积,而Inception首先执行1x1卷积。
2)第一次操作后是否存在非线性。在初始阶段,这两种操作都会伴随着ReLU非线性,然而深度可分离卷积通常是在没有非线性的情况下实现的。
我们认为,第一个差异并不重要,特别是因为这些操作是在堆叠设置中使用的。第二个差异可能很重要,我们在实验部分对此进行了研究(尤其参见图10)。
我们还注意到,位于正则Inception modules和深度可分离卷积之间的Inception modules的其他中间公式也是可能的:实际上,正则卷积和深度可分离卷积之间存在离散频谱,由用于执行空间卷积的独立信道空间段的数量参数化。在该谱的一个极端,正则卷积(前面是1x1卷积)对应于单段情况;深度可分离卷积对应于另一个极端,其中每个通道有一个段;Inception modules介于两者之间,将数百个通道划分为3或4个段。这些中间模块的特性似乎还没有被探索过。(中间层未被探索过)
通过这些观察,我们认为,通过用深度可分离卷积代替Inception modules,即通过构建深度可分离卷积的堆栈模型,可以改进初始体系结构系列。TensorFlow中高效的深度卷积实现使这变得切实可行。在接下来的内容中,我们基于这一思想提出了一种卷积神经网络体系结构,其参数数量与Inception V3相似,并在两个大规模图像分类任务中评估了其相对于Inception V3的性能。
2. Prior work
目前的工作在很大程度上依赖于先前在以下领域的努力:
1、卷积神经网络[10,9,25],尤其是VGG-16架构[18],在几个方面与我们提出的架构类似。
2、卷积神经网络的初始体系结构家族【20、7、21、19】,首先展示了将卷积分解为多个分支的优势,这些分支依次在通道上和空间上运行。
3、我们提出的体系结构完全基于深度可分离卷积。虽然在神经网络中使用空间可分离卷积有着悠久的历史,至少可以追溯到2012年[12](但可能更早),但深度卷积的版本更为新。2013年,Laurent Sifre在Google Brain实习期间开发了深度可分离卷积,并在AlexNet中使用这些卷积,以获得较小的精度增益和较大的收敛速度增益,以及显著减小模型大小。他的工作概述首次在2014年ICLR的一次演讲中公开【23】。Sifre的论文第6.2节【15】中报告了详细的实验结果。这项关于深度可分离卷积的初步工作受到Sifre和Mallat先前关于变换不变散射的研究的启发【16,15】。后来,深度可分离卷积被用作初始V1和初始V2的第一层【20,7】。在谷歌内部,安德鲁·霍华德(AndrewHoward)[6]引入了称为MobileNet的高效移动模型,使用深度可分离卷积。Jin等人于2014年【8】和Wang等人于2016年【24】也做了相关工作,旨在使用可分离卷积来减少卷积神经网络的大小和计算成本。此外,由于在TensorFlow框架中包含了深度可分离卷积的有效实现,我们的工作才有可能实现[1]。
4、剩余连接,由He等人在[4]中介绍,我们提出的体系结构广泛使用。
3. The Xception architecture
我们提出了一种完全基于深度可分离卷积层的卷积神经网络结构。实际上,我们提出以下假设:卷积神经网络特征映射中的跨通道相关性和空间相关性的映射可以完全解耦。由于该假设是Inception modules基础假设的一个更强大版本,我们将我们提出的架构Xception命名为“Extreme Inception”。
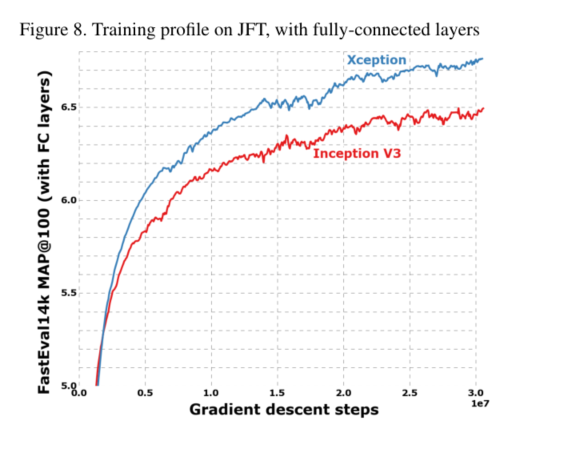
图5给出了网络规范的完整描述。该异常结构具有36个卷积层,构成网络的特征提取基础。在我们的实验评估中,我们将专门研究图像分类,因此我们的卷积基后面将是逻辑回归层。可选地,可以在逻辑回归层之前插入完全连接的层,这将在实验评估部分中进行探讨(具体参见图7和图8)。36个卷积层被构造成14个模块,除了第一个和最后一个模块外,所有模块周围都有线性剩余连接。

简而言之,Exception体系结构是一个具有剩余连接的深度可分离卷积层的线性堆栈。这使得架构很容易定义和修改;使用Keras(2)或TensorFlow Slim(17)等高级库只需要30到40行代码,这与VGG-16(18)等体系结构没有什么不同,但与Inception V2或V3等定义复杂得多的体系结构不同。MIT许可下,作为Keras应用程序模块2的一部分,提供了使用Keras和TensorFlow的Exception开源实现。
4. Experimental evaluation






4.7. Effect of an intermediate activation after pointwise convolutions***
非线性激活进队空间-通道未解耦时有用,对1x1卷积后的feature map非线性激活会导致信息丢失,不利于后续的深度可分离卷积
比喻:
BN操作会导致细节丢失,如果先使用1x1卷积进行,在使用BN归一化,就相当于吃汉堡竖着咬一口,使用BN之后会把肉、生菜、面包等一些细节给去掉了或者消失了,不利于后面做深度可分离卷积

5. Future directions
我们之前注意到,正则卷积和深度可分离卷积之间存在离散谱,由用于执行空间卷积的独立信道空间段的数量来参数化。Inception modules是这一领域的一个重点。我们在经验评估中表明,Inception modules的极端公式,即深度可分离卷积,可能比正则Inception modules具有优势。然而,没有理由相信深度可分离卷积是最优的。这可能是频谱上的中间点,位于正则起始模和深度可分离卷积之间,具有进一步的优势。这个问题留待将来调查。
6. Conclusions
我们展示了卷积和深度可分离卷积如何位于离散谱的两个极端,初始模块是两者之间的中间点。这一观察结果促使我们提出在神经计算机视觉体系结构中用深度可分离卷积代替初始模块。基于这一思想,我们提出了一种新的体系结构,名为Exception,它的参数计数与Inception V3相似。与Inception V3相比,Xception在ImageNet数据集上的分类性能提高很小,而在JFT数据集上的分类性能提高很大。我们预计深度可分离卷积将成为未来卷积神经网络体系结构设计的基石,因为它们提供与初始模块类似的特性,但与常规卷积层一样易于使用。
边栏推荐
- Do you write API documents or code first?
- The latest CSDN salary increase technology stack in 2022 overview of APP automated testing
- Pychart software deployment gray unable to point
- RocketQA:通过跨批次负采样(cross-batch negatives)、去噪的强负例采样(denoised hard negative sampling)与数据增强(data augment
- [multi source BFS] 934 Shortest Bridge
- How to use Jieba participle in unity
- Applet custom top navigation bar, uni app wechat applet custom top navigation bar
- 7_OpenResty安装
- URL和URI
- 如何在智汀中實現智能鎖與燈、智能窗簾電機場景聯動?
猜你喜欢

(translation) reasons why real-time inline verification is easier for users to make mistakes

How does ZABBIX configure alarm SMS? (alert SMS notification setting process)

PMP是什么?

Small program cloud development -- wechat official account article collection

视觉特效,图片转成漫画功能

Restcloud ETl数据通过时间戳实现增量数据同步

LabVIEW计算相机图像传感器分辨率以及镜头焦距

5款主流智能音箱入门款测评:苹果小米华为天猫小度,谁的表现更胜一筹?

Ernie-gram, 显式、完备的 n-gram 掩码语言模型,实现了显式的 n-gram 语义单元知识建模。
What is PMP?
随机推荐
SWT/ANR问题--Dump时间过长导致的SWT
查看 jvm 参数
Pulsar 主题压缩
How to use Jieba participle in unity
How does ZABBIX configure alarm SMS? (alert SMS notification setting process)
Live shopping mall source code, realize left-right linkage of commodity classification pages
PMP是什麼?
我的PMP学习考试心得
MySQL insert \ pre update + judgment condition
在unity中使用jieba分词的方法
现在开户有优惠吗?另外,手机开户安全么?
Qu'est - ce que le PMP?
House change for agricultural products? "Disguised" house purchase subsidy!
SQL语句关联表 如何添加关联表的条件 [需要null值或不需要null值]
522. Longest special sequence II
(translation) reasons why real-time inline verification is easier for users to make mistakes
@The difference between configurationproperties and @value
Video tutorial | Chang'an chain launched a series of video tutorial collections (Introduction)
halcon数组的一些使用
SWT / anr issues - ams/wms