当前位置:网站首页>6、 Project practice --- identifying cats and dogs
6、 Project practice --- identifying cats and dogs
2022-06-26 04:16:00 【Beyond proverb】
One 、 Prepare the dataset
kagglecatsanddogs The Internet is full of them , I won't upload here , You can send a private letter if you need it 
Guide pack
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
Pictures of cats and dogs 12500 Zhang
print(len(os.listdir('./temp/cats/')))
print(len(os.listdir('./temp/dogs/')))
""" 12500 12500 """
Generate training data folder and test data folder
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
def create_dir(file_dir):
if os.path.exists(file_dir):
print("True")
shutil.rmtree(file_dir)# Delete and create
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
cat_source_dir = "./temp/cats/"
train_cats_dir = "./temp/train/cats/"
test_cats_dir = "./temp/test/cats/"
dot_source_dir = "./temp/dogs/"
train_dogs_dir = "./temp/train/dogs/"
test_dogs_dir = "./temp/test/dogs/"
create_dir(train_cats_dir)# Create a cat's training set folder
create_dir(test_cats_dir)# Create the cat's test set folder
create_dir(train_dogs_dir)# Create a dog's training set folder
create_dir(test_dogs_dir)# Create the dog's test set folder
""" True True True True """

Press... For the total dog and cat image 9:1 Divided into training set and test set , Cat and dog each 12500 Zhang
Final temp/train/cats and temp/train/dogs Each of the two folders 12500 * 0.9=11250 Zhang temp/test/cats and temp/test/dogs These two folders are 12500 * 0.1=1250 Zhang
cats and dogs For a total of cat and dog images
test and train Dataset file prepared for
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
def split_data(source,train,test,split_size):
files = []
for filename in os.listdir(source):
file = source + filename
if os.path.getsize(file)>0:
files.append(filename)
else:
print(filename + "is zero file,please ignoring")
train_length = int(len(files)*split_size)
test_length = int(len(files)-train_length)
shuffled_set = random.sample(files,len(files))
train_set = shuffled_set[0:train_length]
test_set = shuffled_set[-test_length:]
for filename in train_set:
this_file = source + filename
destination = train + filename
copyfile(this_file,destination)
for filename in test_set:
this_file = source + filename
destination = test + filename
copyfile(this_file,destination)
cat_source_dir = "./temp/cats/"
train_cats_dir = "./temp/train/cats/"
test_cats_dir = "./temp/test/cats/"
dot_source_dir = "./temp/dogs/"
train_dogs_dir = "./temp/train/dogs/"
test_dogs_dir = "./temp/test/dogs/"
split_size = 0.9
split_data(cat_source_dir,train_cats_dir,test_cats_dir,split_size)
split_data(dog_source_dir,train_dogs_dir,test_dogs_dir,split_size)
Two 、 Model building and training
First, normalize the data , Optimize the pretreatment
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
train_dir = "./temp/train/"
train_datagen = ImageDataGenerator(rescale=1.0/255.0)# Optimize the network , Normalize first
train_generator = train_datagen.flow_from_directory(train_dir,batch_size=100,class_mode='binary',target_size=(150,150))# Two classification , The input of training samples should be consistent
validation_dir = "./temp/test/"
validation_datagen = ImageDataGenerator(rescale=1.0/255.0)
validation_generator = validation_datagen.flow_from_directory(validation_dir,batch_size=100,class_mode='binary',target_size=(150,150))
""" Found 22500 images belonging to 2 classes. Found 2500 images belonging to 2 classes. """
Build model architecture
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),activation='relu',input_shape=(150,150,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['acc'])
Training models
225: Because the data is 22500 Zhang , Cat and dog each 12500 Zhang , It is important for the training set 11250 Zhang , So the training set is 22500 Zhang , In the first piece of preprocessing code ,batch_size=100 Set up a batch of 100 individual , So there should be 225 batch
epochs=2: Two rounds , That is, all samples are trained once
Each round contains 225 batch , Each batch has 100 Samples
history = model.fit_generator(train_generator,
epochs=2,# Conduct 2 Round training , Every round 255 batch
verbose=1,# Don't log every workout ,1 To record
validation_data=validation_generator)
""" Instructions for updating: Use tf.cast instead. Epoch 1/2 131/225 [================>.............] - ETA: 2:03 - loss: 0.7204 - acc: 0.6093 """
history It is the result of the model running process
3、 ... and 、 Analyze the training results
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
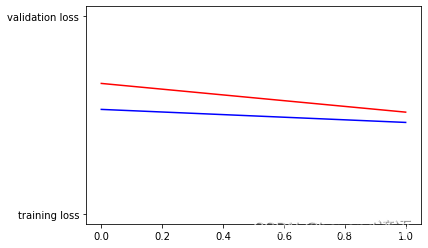
epoch It's too short , The result is a straight line , A few more rounds of training should actually be a line chart
Accuracy rate
plt.plot(epochs,acc,'r',"training accuracy")
plt.plot(epochs,val_acc,'b',"validation accuracy")
plt.title("training and validation accuracy")
plt.figure()

Loss value
plt.plot(epochs,loss,'r',"training loss")
plt.plot(epochs,val_loss,'b',"validation loss")
plt.figure()
Four 、 Validation of the model
import numpy as np
from google.colab import files
from tensorflow.keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys():
path = 'G:/Juptyer_workspace/Tensorflow_mooc/sjj/test/' + fn# This path is the path to be tested with the model
img = image.load_img(path,target_size=(150,150))
x = image.img_to_array(img)# Multidimensional arrays
x = np.expand_dims(x,axis=0)# The tensile
images = np.vstack([x])# Straighten horizontally
classes = model.predict(images,batch_size=10)
print(classes[0])
if classes[0]>0.5:
print(fn + "it is a dog")
else:
print(fn + "it is a cat")
边栏推荐
- Analysis report on the development trend and operation status of China's environmental monitoring instrument industry from 2022 to 2028
- Mutex of thread synchronization (mutex)
- Tencent Interviewer: How did binder get its system services?
- 微软禁止俄用户下载安装Win10/11
- What if the serial port fails to open when the SCM uses stc-isp to download software?
- Ipvs0 network card of IPVS
- Go time package: second, millisecond, nanosecond timestamp output
- 1. foundation closing
- In 2022, what professional competitions can college students majoring in automation, electrical engineering and automation participate in?
- What preparations should be made to develop an app from scratch
猜你喜欢

Sorting out the examination sites of the 13th Blue Bridge Cup single chip microcomputer objective questions
解析JSON接口并批量插入到数据库中

What's wrong with connecting MySQL database with eclipse and then the words in the figure appear

Using jsup to extract images from interfaces

Threejs special sky box materials, five kinds of sky box materials are downloaded for free

Swagger

After a test of 25K bytes, I really saw the basic ceiling
![[Qunhui] import certificate](/img/1f/ab63b0556a60b98388b482d70f6156.jpg)
[Qunhui] import certificate

微软禁止俄用户下载安装Win10/11
Zeromq from getting started to mastering
随机推荐
Tencent Interviewer: How did binder get its system services?
How much do you make by writing a technical book? To tell you the truth, 2million is easy!
Detailed explanation of globalkey of flutter
Redis cache data consistency solution analysis
[Qunhui] import certificate
Use soapUI to access the corresponding ESB project
mysql自带的性能测试工具mysqlslap执行压力测试
[Flink] Flink batch mode map side data aggregation normalizedkeysorter
1.基础关
Report on demand situation and development trend of China's OTC industry from 2022 to 2028
判断两个集合的相同值 ||不同值
而是互联网开始有了新的进化,开始以一种全新的状态出现
Analysis report on development trend and market demand of global and Chinese molecular diagnostics industry from 2022 to 2028
Construction of art NFT trading platform | NFT mall
How does virtual box virtual machine software accelerate the network speed in the virtual system?
軟件調試測試的十大重要基本准則
神经网络学习小记录71——Tensorflow2 使用Google Colab进行深度学习
Judge the same value of two sets 𞓜 different values
[learn FPGA programming from scratch -45]: vision chapter - integrated circuits help high-quality development in the digital era -2- market forecast
win10 系统打开的软件太小,如何变大(亲测有效)