当前位置:网站首页>Based on easycv to reproduce Detr and dab-detr, the correct opening method of object query
Based on easycv to reproduce Detr and dab-detr, the correct opening method of object query
2022-07-25 18:59:00 【51CTO】
DETR It is the latest target detection framework in recent years , The first real end-to-end Detection Algorithm , Save the tedious RPN、anchor and NMS Wait for the operation , Directly input the picture output detection box .DETR Our success is mainly due to Transformer Powerful modeling capabilities , And the Hungarian matching algorithm solves how to learn one-to-one Match detection box and target box .
although DETR Can achieve with Mask R-CNN Quite accurate , But training 500 individual epoch、 Slow convergence , The problem of low accuracy of small targets has been criticized . A series of subsequent work is carried out around these issues , One of the most exciting is Deformable DETR, It is also a must for today's test ,Deformable DETR Our contribution is not just to Deformable Conv Extended to Transformer On , More importantly, it provides a lot of good training DETR Techniques for detecting frameworks , Like imitation Mask R-CNN Framework of the two-stage practice , How to integrate query embed Split into content and reference points Two parts , How to integrate DETR Expand to multi-scale training , And through look forward once Conduct boxes Prediction and other skills , stay Deformable DETR after , Everyone seems to have found out how to open DETR The right way to frame . Among them the object query What does it mean , And how to make better use of object query Make a test , Produced a lot of valuable work , such as Anchor DETR、Conditional DETR wait , among DAB-DETR It is particularly thorough .DAB-DETR take object query As a content and reference points Two parts , among reference points The displayed representation is xywh four-dimensional vector , And then through decoder forecast xywh The residual of is iteratively updated to the detection box , And through xywh Vectors introduce positional attention , help DETR Speed up convergence , This article will be based on EasyCV Recurring DETR and DAB-DETR The algorithm details how to use it correctly object query To enhance DETR Check the performance of the framework .
DETR
DETR Use set loss function As a monitoring signal for end-to-end training , Then predict all goals at the same time , among set loss function Use bipartite matching Algorithm will pred Objectives and gt Match the goals . Directly regard the target detection task as set prediction problem , Make the training process simple , And avoid anchor、NMS Etc .
DETR The main contribution has two parts :architecture and set prediction loss.
1.Architecture

DETR First use CNN The input image embedding Into a two-dimensional representation , Then convert the two-dimensional representation into one-dimensional representation and combine positional encoding Send together encoder,decoder Put a small fixed number of learned object queries( It can be understood as positional embeddings) and encoder Output as input . The final will be decoder Every... You get output embdding To a shared feedforward network (FFN), The network can predict a detection result ( Include classes and borders ) Or the “ No target ” Class .
1.1 Transformer
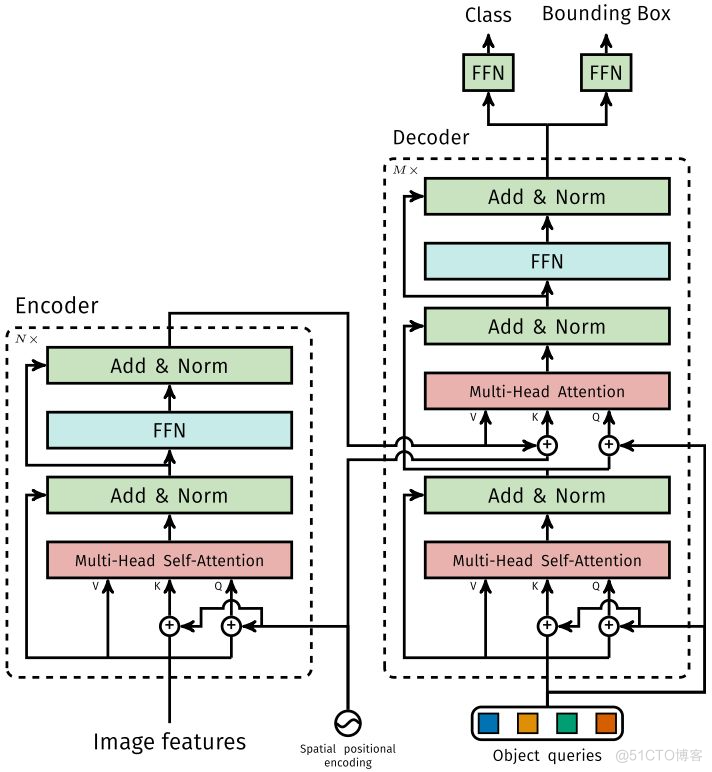
1.1.1 Encoder
take Backbone Output feature map Convert to one-dimensional representation , obtain Characteristics of figure , Then combine positional encoding As Encoder The input of . Every Encoder All by Multi-Head Self-Attention and FFN form . and Transformer Encoder The difference is , because Encoder It has position invariance ,DETR take positional encoding Add to each Multi-Head Self-Attention in , To ensure the position sensitivity of target detection .
1.1.2 Decoder
because Decoder It also has position invariance ,Decoder Of %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) individual object query( It can be understood that learning is different object Of positional embedding) Must be different , In order to generate different object Of embedding, And add them to each at the same time Multi-Head Attention in . individual object queries adopt Decoder Convert to a output embedding, then output embedding adopt FFN Independently decode A prediction , contain box and class. For input embedding Use at the same time Self-Attention and Encoder-Decoder Attention, The model can make use of the relationship between targets to carry out global reasoning . and Transformer Decoder The difference is ,DETR Each Decoder Parallel output Objects ,Transformer Decoder Using an autoregressive model , Serial output Objects , Only one element of one output sequence can be predicted at a time .
individual object query( It can be understood that learning is different object Of positional embedding) Must be different , In order to generate different object Of embedding, And add them to each at the same time Multi-Head Attention in . individual object queries adopt Decoder Convert to a output embedding, then output embedding adopt FFN Independently decode A prediction , contain box and class. For input embedding Use at the same time Self-Attention and Encoder-Decoder Attention, The model can make use of the relationship between targets to carry out global reasoning . and Transformer Decoder The difference is ,DETR Each Decoder Parallel output Objects ,Transformer Decoder Using an autoregressive model , Serial output Objects , Only one element of one output sequence can be predicted at a time .
1.1.3 FFNFFN
from 3 layer perceptron And the first floor linear projection form .FFN Predict box Normalized center coordinates of 、 Long 、 generous and easygoing class.DETR The forecast is a fixed number N individual box Set , also N Usually larger than the actual target number ( among DETR The default setting is 100 individual , and DAB-DETR Set to 300 individual ), And an extra empty class is used to represent the predicted box There is no goal .
2.Set prediction loss
DETR The main difficulty of model training is how to base on gt Measure forecast results ( Category 、 Location 、 Number ).DETR Proposed loss Function can produce pred and gt Optimal bilateral matching ( determine pred and gt The one-to-one relationship of ), And then optimize loss. take %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-79%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) Expressed as gt Set , Expressed as A set of prediction results . hypothesis Greater than the number of image targets , It can be considered as using empty classes ( No goal ) The size of the fill is N Set . Search two sets Elements
Expressed as gt Set , Expressed as A set of prediction results . hypothesis Greater than the number of image targets , It can be considered as using empty classes ( No goal ) The size of the fill is N Set . Search two sets Elements  Different arrangement order of , bring loss The smallest possible order of permutation is the maximum match of bipartite graph (Bipartite Matching), The formula is as follows :
Different arrangement order of , bring loss The smallest possible order of permutation is the maximum match of bipartite graph (Bipartite Matching), The formula is as follows :

among  Express pred and gt About
Express pred and gt About %3C%2Ftitle%3E%0A%3Cdefs%20aria-hidden%3D%22true%22%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-3C3%22%20d%3D%22M184%20-11Q116%20-11%2074%2034T31%20147Q31%20247%20104%20333T274%20430Q275%20431%20414%20431H552Q553%20430%20555%20429T559%20427T562%20425T565%20422T567%20420T569%20416T570%20412T571%20407T572%20401Q572%20357%20507%20357Q500%20357%20490%20357T476%20358H416L421%20348Q439%20310%20439%20263Q439%20153%20359%2071T184%20-11ZM361%20278Q361%20358%20276%20358Q152%20358%20115%20184Q114%20180%20114%20178Q106%20141%20106%20117Q106%2067%20131%2047T188%2026Q242%2026%20287%2073Q316%20103%20334%20153T356%20233T361%20278Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-28%22%20d%3D%22M94%20250Q94%20319%20104%20381T127%20488T164%20576T202%20643T244%20695T277%20729T302%20750H315H319Q333%20750%20333%20741Q333%20738%20316%20720T275%20667T226%20581T184%20443T167%20250T184%2058T225%20-81T274%20-167T316%20-220T333%20-241Q333%20-250%20318%20-250H315H302L274%20-226Q180%20-141%20137%20-14T94%20250Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-69%22%20d%3D%22M184%20600Q184%20624%20203%20642T247%20661Q265%20661%20277%20649T290%20619Q290%20596%20270%20577T226%20557Q211%20557%20198%20567T184%20600ZM21%20287Q21%20295%2030%20318T54%20369T98%20420T158%20442Q197%20442%20223%20419T250%20357Q250%20340%20236%20301T196%20196T154%2083Q149%2061%20149%2051Q149%2026%20166%2026Q175%2026%20185%2029T208%2043T235%2078T260%20137Q263%20149%20265%20151T282%20153Q302%20153%20302%20143Q302%20135%20293%20112T268%2061T223%2011T161%20-11Q129%20-11%20102%2010T74%2074Q74%2091%2079%20106T122%20220Q160%20321%20166%20341T173%20380Q173%20404%20156%20404H154Q124%20404%2099%20371T61%20287Q60%20286%2059%20284T58%20281T56%20279T53%20278T49%20278T41%20278H27Q21%20284%2021%20287Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-29%22%20d%3D%22M60%20749L64%20750Q69%20750%2074%20750H86L114%20726Q208%20641%20251%20514T294%20250Q294%20182%20284%20119T261%2012T224%20-76T186%20-143T145%20-194T113%20-227T90%20-246Q87%20-249%2086%20-250H74Q66%20-250%2063%20-250T58%20-247T55%20-238Q56%20-237%2066%20-225Q221%20-64%20221%20250T66%20725Q56%20737%2055%20738Q55%20746%2060%20749Z%22%3E%3C%2Fpath%3E%0A%3C%2Fdefs%3E%0A%3Cg%20stroke%3D%22currentColor%22%20fill%3D%22currentColor%22%20stroke-width%3D%220%22%20transform%3D%22matrix(1%200%200%20-1%200%200)%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-3C3%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%20x%3D%22571%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%22961%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%20x%3D%221306%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) Elements
Elements %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) The matching of loss. The bipartite graph is matched by Hungarian algorithm (Hungarian algorithm) obtain . matching loss At the same time, I considered pred class and pred box The accuracy of the . Every gt The elements of i Can be seen as
The matching of loss. The bipartite graph is matched by Hungarian algorithm (Hungarian algorithm) obtain . matching loss At the same time, I considered pred class and pred box The accuracy of the . Every gt The elements of i Can be seen as %3C%2Ftitle%3E%0A%3Cdefs%20aria-hidden%3D%22true%22%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-79%22%20d%3D%22M21%20287Q21%20301%2036%20335T84%20406T158%20442Q199%20442%20224%20419T250%20355Q248%20336%20247%20334Q247%20331%20231%20288T198%20191T182%20105Q182%2062%20196%2045T238%2027Q261%2027%20281%2038T312%2061T339%2094Q339%2095%20344%20114T358%20173T377%20247Q415%20397%20419%20404Q432%20431%20462%20431Q475%20431%20483%20424T494%20412T496%20403Q496%20390%20447%20193T391%20-23Q363%20-106%20294%20-155T156%20-205Q111%20-205%2077%20-183T43%20-117Q43%20-95%2050%20-80T69%20-58T89%20-48T106%20-45Q150%20-45%20150%20-87Q150%20-107%20138%20-122T115%20-142T102%20-147L99%20-148Q101%20-153%20118%20-160T152%20-167H160Q177%20-167%20186%20-165Q219%20-156%20247%20-127T290%20-65T313%20-9T321%2021L315%2017Q309%2013%20296%206T270%20-6Q250%20-11%20231%20-11Q185%20-11%20150%2011T104%2082Q103%2089%20103%20113Q103%20170%20138%20262T173%20379Q173%20380%20173%20381Q173%20390%20173%20393T169%20400T158%20404H154Q131%20404%20112%20385T82%20344T65%20302T57%20280Q55%20278%2041%20278H27Q21%20284%2021%20287Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-69%22%20d%3D%22M184%20600Q184%20624%20203%20642T247%20661Q265%20661%20277%20649T290%20619Q290%20596%20270%20577T226%20557Q211%20557%20198%20567T184%20600ZM21%20287Q21%20295%2030%20318T54%20369T98%20420T158%20442Q197%20442%20223%20419T250%20357Q250%20340%20236%20301T196%20196T154%2083Q149%2061%20149%2051Q149%2026%20166%2026Q175%2026%20185%2029T208%2043T235%2078T260%20137Q263%20149%20265%20151T282%20153Q302%20153%20302%20143Q302%20135%20293%20112T268%2061T223%2011T161%20-11Q129%20-11%20102%2010T74%2074Q74%2091%2079%20106T122%20220Q160%20321%20166%20341T173%20380Q173%20404%20156%20404H154Q124%20404%2099%20371T61%20287Q60%20286%2059%20284T58%20281T56%20279T53%20278T49%20278T41%20278H27Q21%20284%2021%20287Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-3D%22%20d%3D%22M56%20347Q56%20360%2070%20367H707Q722%20359%20722%20347Q722%20336%20708%20328L390%20327H72Q56%20332%2056%20347ZM56%20153Q56%20168%2072%20173H708Q722%20163%20722%20153Q722%20140%20707%20133H70Q56%20140%2056%20153Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-28%22%20d%3D%22M94%20250Q94%20319%20104%20381T127%20488T164%20576T202%20643T244%20695T277%20729T302%20750H315H319Q333%20750%20333%20741Q333%20738%20316%20720T275%20667T226%20581T184%20443T167%20250T184%2058T225%20-81T274%20-167T316%20-220T333%20-241Q333%20-250%20318%20-250H315H302L274%20-226Q180%20-141%20137%20-14T94%20250Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-63%22%20d%3D%22M34%20159Q34%20268%20120%20355T306%20442Q362%20442%20394%20418T427%20355Q427%20326%20408%20306T360%20285Q341%20285%20330%20295T319%20325T330%20359T352%20380T366%20386H367Q367%20388%20361%20392T340%20400T306%20404Q276%20404%20249%20390Q228%20381%20206%20359Q162%20315%20142%20235T121%20119Q121%2073%20147%2050Q169%2026%20205%2026H209Q321%2026%20394%20111Q403%20121%20406%20121Q410%20121%20419%20112T429%2098T420%2083T391%2055T346%2025T282%200T202%20-11Q127%20-11%2081%2037T34%20159Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-2C%22%20d%3D%22M78%2035T78%2060T94%20103T137%20121Q165%20121%20187%2096T210%208Q210%20-27%20201%20-60T180%20-117T154%20-158T130%20-185T117%20-194Q113%20-194%20104%20-185T95%20-172Q95%20-168%20106%20-156T131%20-126T157%20-76T173%20-3V9L172%208Q170%207%20167%206T161%203T152%201T140%200Q113%200%2096%2017Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-62%22%20d%3D%22M73%20647Q73%20657%2077%20670T89%20683Q90%20683%20161%20688T234%20694Q246%20694%20246%20685T212%20542Q204%20508%20195%20472T180%20418L176%20399Q176%20396%20182%20402Q231%20442%20283%20442Q345%20442%20383%20396T422%20280Q422%20169%20343%2079T173%20-11Q123%20-11%2082%2027T40%20150V159Q40%20180%2048%20217T97%20414Q147%20611%20147%20623T109%20637Q104%20637%20101%20637H96Q86%20637%2083%20637T76%20640T73%20647ZM336%20325V331Q336%20405%20275%20405Q258%20405%20240%20397T207%20376T181%20352T163%20330L157%20322L136%20236Q114%20150%20114%20114Q114%2066%20138%2042Q154%2026%20178%2026Q211%2026%20245%2058Q270%2081%20285%20114T318%20219Q336%20291%20336%20325Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-29%22%20d%3D%22M60%20749L64%20750Q69%20750%2074%20750H86L114%20726Q208%20641%20251%20514T294%20250Q294%20182%20284%20119T261%2012T224%20-76T186%20-143T145%20-194T113%20-227T90%20-246Q87%20-249%2086%20-250H74Q66%20-250%2063%20-250T58%20-247T55%20-238Q56%20-237%2066%20-225Q221%20-64%20221%20250T66%20725Q56%20737%2055%20738Q55%20746%2060%20749Z%22%3E%3C%2Fpath%3E%0A%3C%2Fdefs%3E%0A%3Cg%20stroke%3D%22currentColor%22%20fill%3D%22currentColor%22%20stroke-width%3D%220%22%20transform%3D%22matrix(1%200%200%20-1%200%200)%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-79%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%22497%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%221009%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%20x%3D%222065%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%222455%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%222888%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%223401%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-62%22%20x%3D%223846%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%224275%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%20x%3D%224787%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) ,
,%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%22433%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) Express class label( It may be an empty class )
Express class label( It may be an empty class )%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-62%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%22429%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) Express gt box, Put the element The bipartite graph matches the specified pred class Expressed as
Express gt box, Put the element The bipartite graph matches the specified pred class Expressed as  ,pred box Expressed as
,pred box Expressed as  .
.
The first step is to find a one-to-one match pred and gt, The second step is to calculate hungarian loss.hungarian loss The formula is as follows :
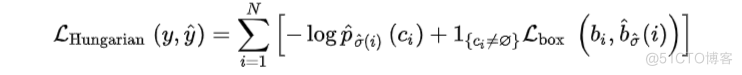
among Combined with the L1 loss and generalized IoU loss, The formula is as follows :

DAB-DETR
DAB-DETR take object query As a content and reference points Two parts , among reference points The displayed representation is xywh four-dimensional vector , And then through decoder forecast xywh The residual of is iteratively updated to the detection box , And through xywh Vectors introduce positional attention , help DETR Speed up convergence .


stay DAB-DETR Before , There is a lot of work on how to set reference points Have made in-depth exploration :Conditional DETR adopt 256 The learnable vector of dimension learns xy Reference point , Then the location information is introduced transformer decoder in ;Anchor DETR The reference point is regarded as xy, And then get through learning 256 Dimension vector , Introduce location information into transformer decoder in , And through the step-by-step iteration, we get the xy;Defomable DETR It is through 256 The vectorial learning vector gets xywh Reference resources anchor, The detection frame is obtained through step-by-step iteration ;DAB-DETR Is more thorough , Absorb the advantages of hundreds of families , adopt xywh Study 256 Dimension vector , Introduce location information into transformer decoder in , And the detection frame is obtained through step-by-step iteration . thus ,reference points The way of using is becoming clearer , The displayed representation is xywh, Then learn to 256 Dimension vector , Introduce location information , Each layer transformer decoder Study xywh Residual of , The final detection frame is obtained by stacking step by step .

in addition ,DAB-DETR In order to make full use of xywh This is more revealing reference points Representation , Further introduced Width & Height-Modulated Multi-Head Cross-Attention, In fact, simply speaking, it is in cross-attention Introduction position in xywh Get position attention , This improvement can be greatly accelerated decoder The rate of convergence , Because the original DETR It is equivalent to learning positional attention in the whole picture ,DAB-DETR You can focus directly on key positions , This is also Deformable DETR The reason why convergence can be accelerated , The essence is that the more critical sparse position sampling can speed up decoder Convergence rate .
Repeat the results

Tutorial
Next , We will use a practical example to show how to base on EasyCV Conduct DAB-DETR Algorithm training , You can also link See the detailed steps .
One 、 Install dependency packages
If you are running in a local development environment , You can refer to the link Installation environment . If you use PAI-DSW There is no need to install related dependencies for the experiment , stay PAI-DSW docker Relevant environment has been built in . Two 、 Data preparation
You can download COCO2017 data , You can also use the example we provided COCO data
data/coco The format is as follows :
Two 、 Model training and evaluation
With vitdet-base For example . stay EasyCV in , Use the form of configuration file to realize the control of model parameters 、 Data input and augmentation methods 、 Configuration of training strategy , Only by modifying the parameter settings in the configuration file , You can complete the experimental configuration for training . You can download the sample configuration file directly .
see easycv Installation position
Execute training orders
Execute the evaluation order
Reference
Code implementation :
DETR https://github.com/alibaba/EasyCV/tree/master/easycv/models/detection/detectors/detr
DAB-DETR https://github.com/alibaba/EasyCV/tree/master/easycv/models/detection/detectors/dab_detr
EasyCV Previous sharing
be based on EasyCV Reappear ViTDet: Single layer features surpass FPN https://zhuanlan.zhihu.com/p/528733299
MAE Introduction and implementation of self-monitoring algorithm based on EasyCV The recurrence of https://zhuanlan.zhihu.com/p/515859470
EasyCV Open source | Visual self-monitoring out of the box +Transformer Algorithm library https://zhuanlan.zhihu.com/p/505219993
边栏推荐
- 给生活加点惊喜,做创意生活的原型设计师丨编程挑战赛 x 选手分享
- PHP等于==和恒等于===的区别
- Yarn 安装与使用教程[通俗易懂]
- 2022 Robocom 省赛题解
- QT compiled successfully, but the program could not run
- 华为交换机系统软件升级和安全漏洞修复教程
- With a financing of 200million yuan, the former online bookstore is now closed nationwide, with only 3 stores left in 60 stores
- 浅析IM即时通讯开发出现上网卡顿?网络掉线?
- MES管理系统有什么应用价值
- [cloud native kubernetes] management of secret storage objects under kubernetes cluster
猜你喜欢

MySQL sub query (selected 20 sub query exercises)

With a market value of 30billion yuan, the largest IPO in Europe in the past decade was re launched on the New York Stock Exchange

Fruit chain "siege": it's a journey of sweetness and bitterness next to apples

【919. 完全二叉树插入器】

【Web技术】1391- 页面可视化搭建工具前生今世

【加密周报】加密市场有所回温?寒冬仍未解冻!盘点上周加密市场发生的重大事件!

Circulaindicator component, which makes the indicator style more diversified

The Yellow Crane Tower has a super shocking perspective. You've never seen such a VR panorama!
Excellent test / development programmers should make breakthroughs and never forget their original intentions, so that they can always

上半年出货量已超去年全年,森思泰克毫米波雷达“夺食”国际巨头
随机推荐
【919. 完全二叉树插入器】
关爱一线防疫工作者,浩城嘉业携手高米店街道办事处共筑公益长城
Circulaindicator component, which makes the indicator style more diversified
房企打响“保交战”
MySQL sub query (selected 20 sub query exercises)
Care for front-line epidemic prevention workers, Haocheng JIAYE and Gaomidian sub district office jointly build the great wall of public welfare
无惧高温暴雨,有孚网络如何保您无忧?
CircleIndicator组件,使指示器风格更加多样化
[encryption weekly] has the encryption market recovered? The cold winter has not thawed yet! Check the major events in the encryption market last week!
JMeter performance test actual video (what are the common performance test tools)
Everyone can participate in the official launch of open source activities. We sincerely invite you to experience!
Ping command details [easy to understand]
软件测试(思维导图)
Single arm routing experiment demonstration (Huawei router device configuration)
Dachang cloud business adjustment, a new round of war turn
浅析IM即时通讯开发出现上网卡顿?网络掉线?
srec_ Use of common cat parameters
Communication between processes (pipeline communication)
分享六个实用的小程序插件
Excellent test / development programmers should make breakthroughs and never forget their original intentions, so that they can always