当前位置:网站首页>Deep learning vocabulary embedded, beam search
Deep learning vocabulary embedded, beam search
2022-07-27 03:19:00 【laluneX】
One 、 Vocabulary expression
1. code
① Hot coding alone | one-hot representation
Hot coding alone Refer to Use a position in a vector to represent a word
one-hot The shortcomings of as follows :
- Unable to express Between words Relationship
- And this too sparse vector , Resulting in inefficient computing and storage
② Word embedding | word embedding
Word embedding Refers to using Multiple features Come on To express a word , And this Multiple features It's just Formed a space ( Dimension is a quantity characterized by ), So it is equivalent to the word ( Multidimensional vectors ) Embedded in the space it belongs to .
Advantages of word embedding Yes :
- Can be Text adopt A low dimensional vector to express , Unlike one-hot As long as .
- Words with similar meanings stay Vector space Yes Quite similar
2. Vector similarity
① Cosine similarity
Cosine similarity By measuring Cosine of the angle between two vectors To measure the similarity . The cosine of any other angle is not greater than 1; And its minimum value is -1.
s i m ( u , v ) = u T v ∣ ∣ u ∣ ∣ ∗ ∣ ∣ v ∣ ∣ sim(u, v)=\frac{u^Tv}{||u||*||v||} sim(u,v)=∣∣u∣∣∗∣∣v∣∣uTv
② Euclidean distance
Euclidean distance It's used to measure The distance that an individual exists in space , distance The farther Explain the relationship between individuals The greater the difference
d ( u , v ) = ∣ ∣ u − v ∣ ∣ d(u, v)=||u-v|| d(u,v)=∣∣u−v∣∣
3. Word embedding algorithm
①Word2vec
Word2Vec It's for Generate word vectors Tools for .Word2Vec yes Lightweight neural networks , Its model includes only the input layer 、 Hidden layer and output layer , The model framework varies according to the input and output , It mainly includes CBOW( Predict the current word through the context ) and Skip-gram( Use the current word to predict the context ) Model .
1. CBOW
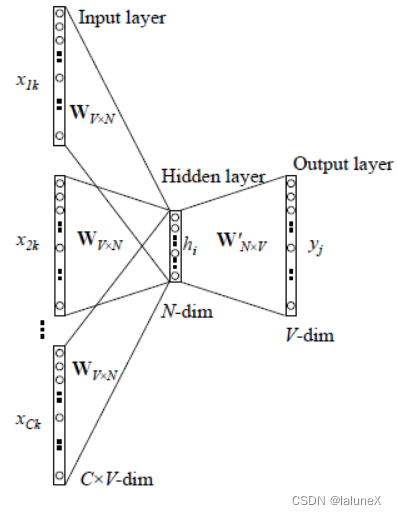
1、 Input layer : The contextual word is One-Hot Code word vector ,V For Glossary The number of words ,N For custom The dimension of the word vector ,C by Number of contextual words
2、 Initialize a Weight matrices W V × N W_{V×N} WV×N, Then use all Input One-Hot The coding word vector multiplies the matrix left , obtain Dimension is N Vector w 1 , w 2 , w 3 , . . . , w c w_1, w_2, w_3,..., w_c w1,w2,w3,...,wc, there N Set by yourself according to the needs of the task
3、 Put the resulting vector w 1 , w 2 , w 3 , . . . , w c w_1, w_2, w_3,..., w_c w1,w2,w3,...,wc Add and average as hidden layer vector h i h_i hi
4、 Initialize another Weight matrices W V × N ′ W_{V×N}^′ WV×N′, use Hidden layer vector h i h_i hi Left multiplication This matrix , obtain V Dimension vector y,y Each element of represents the corresponding probability distribution of each word
5、y The element with the highest probability The indicated word is Predicted target words (target word), and It is associated with true label Of One-Hot code Word vector do Compare , The smaller the error, the better ( Update the two weight matrices according to the error )
You need to define before training Loss function ( It's generally a cross entropy cost function ), use Gradient descent algorithm update W and W’. After training , Input each word and matrix of the layer W Multiply Of the resulting vector Is the word vector we want , It's also called word embedding. because One-Hot Only one element in the codeword vector is 1, Everything else is 0, So the first i Multiply a word vector by a matrix W What you get is the second of the matrix i That's ok
2. Skip-gram

1、 Input layer :V by The number of words in the vocabulary ,N For custom The dimension of the word vector ,C by Number of contextual words , First of all, we Choose a word in the middle of the sentence as our input word
2、 And then based on skip_window( It represents us from the present input word One side of ( Left or right ) Choose the number of words ) Come on Get the word in the window . Another parameter is num_skips, It represents us from Entire window in How many different words to choose As our output word. You end up with (input word, output word) Form of training data
3、 neural network Based on these Acquisition statistics of the number of occurrences of each pair of words in the training data , And output a probability distribution , This probability distribution represents how likely each word in our dictionary is to follow input word At the same time .
4、 adopt Gradient descent and back propagation update matrix W and W’
5、W Row vector in That is to say Of each word Word embedding
In the previous two sections, we introduced CBOW and Skip-gram The most ideal implementation , That is, training iteration Two matrices W and W’, After the Output layer use softmax function To calculate the output The probability of each word . But in Practical application The training of this method Costly , Not very practical , In order to make the model convenient for training , Some scholars have proposed that Hierarchical Softmax and Negative Sampling Two ways to improve .
3. Hierarchical Softmax( classification softmax)
Hierarchical Softmax The improvements to the original model mainly include At two o 'clock ,
- The first point It's from Input layer to hidden layer mapping , The original and matrix is not used W Multiply and add to average Methods , It is Sum all input word vectors directly . Suppose the input word vector is (0,1,0,0) and (0,0,0,1), Then the vector of the hidden layer is (0,1,0,1).
- Second point The improvement is to adopt Huffman tree To replace the original Matrix from hidden layer to output layer W’. The number of leaf nodes of Huffman tree is the number of words in the vocabulary V, A leaf node represents a word , The path from the root node to the leaf node determines the word vector finally output by this word .
Finally, when predicting the output vector , It turned out to be a multi classification problem , But by hierarchical softmax The technique of , hold V The problem of classification becomes log(V) The second category .
4. Negative Sampling( Negative sampling )
Even though Huffman tree The introduction of is the training of the model Reduce a lot of expenses , But for some uncommon 、 More obscure vocabulary , Huffman trees still need to do a lot of operations when calculating their word vectors .
Positive sampling Find one in the clause input word, Then find one word Do its context , Rear most target by 1
Negative sampling Is to choose the same positive sampling same input word, And then from Look for a word randomly in the dictionary ( Whether or not it appears in this sentence ), Rear most target by 0, share k Negative samples . This forms the training data 
That is to say, yes Training set the sampling , thus The size of the training set is reduced , It only took target Medium 1 And part 0
②GloVe
GloVe It's right Word2vec Method extension , It will Global statistics and Word2vec Context based Combined with learning .
Two 、Beam Search
1. Introduce
Beam Search( beam search ) It's a kind of Approximate search algorithm , It's for Reduce Search occupied Space and time , So in Depth expansion at each step When , Cut off some poor quality nodes , Keep some high quality nodes . but shortcoming There is There may be potential best practices that are discarded
Cluster width Is a parameter that needs to be set , It stands for Keep the number of high-quality nodes each time
beam search In essence greedy Thought , It just considers More candidate search spaces
2. Improvement of beam search
The original formula :
Because every conditional probability is less than 1, And for A long sentence Come on , Multiple less than 1 Multiply the values of , Meeting Make the algorithm's prediction of long sentences bad . and If the value is too small , Cause the floating-point representation of the computer Cannot store accurately , But take logarithm
resolvent : Yes beam search Improvement of the objective function of 
α∈[0,1] It's a super parameter , Usually take α = 0.7. if α = 0, Is not normalized ; if α = 1, Then the standard length is normalized .
3. Error analysis of beam search
stay Actual project in , When The model fitting effect is poor when , how Judgment is RNN Model or Beam Search Something went wrong. Well ?
In the translation task , y ∗ y^* y∗ Indicates the result of human translation , y ^ \hat{y} y^ Represents the result of the algorithm .
- The first reason for error : Expectations High probability , however Beam Search No expectations selected , yes Beam Search The problem of , Can pass increase B To improve .
- The second error reason :RNN Model The probability of error is given for the expected value , Give a good sentence a small probability , therefore RNN Model error , Need to be in RNN Spend more time on the model .
4. Bleu score
BLEU(Bilingual Evaluation Understudy), namely Bilingual evaluation substitute . The so-called substitute is Instead of humans, evaluate every output of machine translation .Bleu score What we did , Given a machine generated translation , Automatically calculate a score , Measure the quality of machine translation
B l e u = B P ∗ e x p ( 1 n ∑ i = 1 N P n ) Bleu=BP*exp(\frac{1}{n}\sum_{i=1}^NP_n) Bleu=BP∗exp(n1∑i=1NPn)
among ,BP Is the short penalty factor , The length of a sentence is too short , Prevent the phenomenon that the training results tend to be short sentences , The expression is :
3、 ... and 、 other
1. Reference link
- https://www.cnblogs.com/lfri/p/15032919.html
This article is only for personal learning and recording , Tort made delete
边栏推荐
- Hcip 13th day notes
- 消息被拒MQ
- window对象的常见事件
- Okaleido tiger is about to log in to binance NFT in the second round, which has aroused heated discussion in the community
- 185. All employees with the top three highest wages in the Department (mandatory)
- {“errcode“:44001,“errmsg“:“empty media data, hint: [1655962096234893527769663], from ip: 222.72.xxx.
- 朴素贝叶斯——文档分类
- “date: write error: No space left on device”解决
- Win10/win11 lossless expansion of C disk space, cross disk consolidation of C and e disks
- Coco test dev test code
猜你喜欢

After two years of graduation, I switched to software testing and got 12k+, and my dream of not taking the postgraduate entrance examination with a monthly salary of more than 10000 was realized

5、 MFC view windows and documents

Worthington过氧化物酶活性的6种测定方法
Idea 中添加支持@Data 插件

Portraiture5 new and upgraded leather filter plug-in artifact

Alibaba cloud technology expert Yang Zeqiang: Construction of observability on elastic computing cloud

客户案例 | 关注老年用户体验,银行APP适老化改造要避虚就实

How to use devaxpress WPF to create the first MVVM application in winui?

Pytoch loss function summary

【学习笔记之菜Dog学C】字符串+内存函数
随机推荐
HCIP第十四天笔记
一个测试类了解BeanUtils.copyProperties
[binary search medium] leetcode 34. find the first and last positions of elements in the sorted array
177. The nth highest salary (simple)
“满五唯一”和“满二唯一”是什么?有什么不同?
代码审查金字塔
A math problem cost the chip giant $500million!
Idea 中添加支持@Data 插件
Coco test dev test code
[learning notes, dog learning C] string + memory function
Worthington过氧化物酶活性的6种测定方法
商城小程序项目完整源码(微信小程序)
在线问题反馈模块实战(十五):实现在线更新反馈状态功能
DNS记录类型及相关名词解释
2513: 小勇学分数(公约数问题)
Submodule cache cache failure
Comprehensive care analysis lyriq Ruige battery safety design
Bulk copy baby upload prompt garbled, how to solve?
185. 部门工资前三高的所有员工(必会)
Portraiture5 new and upgraded leather filter plug-in artifact