当前位置:网站首页>SSD: Single Shot MultiBox Detector
SSD: Single Shot MultiBox Detector
2022-07-23 12:55:00 【TJMtaotao】
Wei Liu1 , Dragomir Anguelov2 , Dumitru Erhan3 , Christian Szegedy3 , Scott Reed4 , Cheng-Yang Fu1 , Alexander C. Berg1 1UNC Chapel Hill 2Zoox Inc. 3Google Inc. 4University of Michigan, Ann-Arbor [email protected], [email protected], 3 {dumitru,szegedy}@google.com, [email protected], 1 {cyfu,aberg}@cs.unc.edu
摘要:我们提出了一种用单一的深层神经网络我们的方法名为SSD,它将在不同纵横比和比例上将框绑定到一组默认框中根据功能图位置在预测时,网络为在每个默认框中显示每个对象类别,并对更好地匹配对象形状的框此外,该网络将来自多个分辨率不同的特征地图的预测结合起来,以自然地处理各种大小的物体相对于需要对象的方法,ssd很简单建议,因为它完全消除了建议生成和后续像素或特征重采样阶段并将所有计算封装在单个网络这使得SSD易于训练,并且易于集成到需要检测组件的系统中PASCAL上的实验结果VOC、COCO和ILSVRC数据集证实SSD具有竞争性的准确性使用附加的对象建议步骤并且速度更快的方法,而为训练和推理提供统一的框架对于300×300输入,ssd达到74.3%map1在nvidia泰坦上以59 fps的速度进行voc2007测试X,对于512×512的输入,SSD达到了76.9%的mAP,优于同类的最先进的更快R-CNN模型与其他单级方法相比,SSD在输入图像较小的情况下具有更好的精度代码是网址:https://github.com/weiliu89/caffe/tree/ssd。
关键词:实时目标检测;卷积神经网络
1介绍
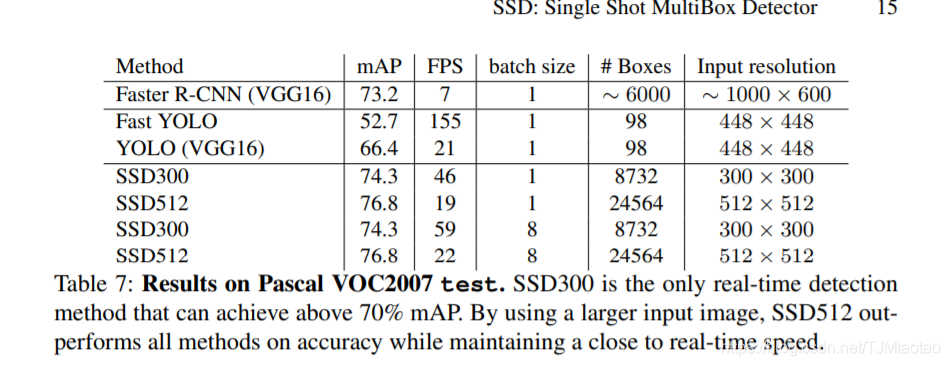
当前最先进的对象检测系统是以下方法的变体:假设边界框,对每个框重新采样像素或特性,并应用高质量的分类器。这条管道已经在检测基准上取得了成功,因为自主动搜索工作[1]以来,通过目前在PASCAL VOC、COCO和ILSVRC上的领先结果,所有的检测都基于更快的R-CNN[2],尽管有更深的特性,如[3]。虽然这些方法是准确的,但是对于em层的系统来说,这些方法的计算量太大,即使对于高端硬件,对于实时应用来说速度也太慢。
通常,这些方法的检测速度是以秒为单位来计算的(SPF),即使是最快的高精度检测器,也只有每秒7帧(FPS)。已经有许多尝试通过攻击检测管道的每个阶段来构建更快的检测器(参见第4节中的相关工作),但是到目前为止,显著提高速度的代价是显著降低检测精度。
本文提出了第一个基于深度网络的目标检测器,它不需要对像素或边界框假设特征进行重新采样,并且与ap方法一样精确。这使得高精度检测的速度有了显著提高(在VOC2007测试中,mAP 74.3%为59帧/秒,而mAP 73.2%为R-CNN 7帧/秒,mAP 63.4%为YOLO 45帧/秒)。速度的根本改进来自消除边界框建议和随后的像素或有限元重采样阶段。我们并不是第一个这样做的(cf[4,5),但是通过添加一系列的改进,我们能够显著提高精度。我们的改进包括使用一个小的卷积过滤器来预测包围盒位置中的对象类别和偏移量,使用独立的预测器(过滤器)来检测不同的长宽比,并将这些过滤器应用到网络后期的多个特征映射上,以执行多尺度的检测。通过这些修改—特别是使用多层来在不同的尺度上进行预测—我们可以使用相对较低的分辨率输入来实现高精度,从而进一步提高检测速度。虽然这些独立的贡献可能看起来很小,但我们注意到,最终的系统提高了实时检测PASCAL VOC的准确性,从YOLO的63.4%提高到SSD的74.3%。这是一个较大的相对提高检测精度比从最近,非常高调的工作,残余网络[3]。此外,显著提高高质量检测的速度,拓宽了计算机视觉有用的设置范围
我们的贡献总结如下-我们引入了SSD,一种用于多个类别的单镜头探测器,它比以前的单镜头探测器(YOLO)速度更快,而且明显更准确,实际上与执行显式区域建议和池(包括更快的R-CNN)的较慢技术一样准确。SSD的核心是使用应用于特征图的小卷积过滤器来预测一组固定的默认边界框的类别分数和框偏移量。为了实现较高的检测精度,我们从不同尺度的特征图中生成不同尺度的预测,并通过纵横比明确地分离预测。这些设计特点导致了简单的端到端训练和高精度,甚至在低分辨率的输入图像,进一步提高了速度与精度的权衡。实验包括时间和准确性分析模型与不同的输入大小评估帕斯卡VOC。和ILSVRC,并与一系列最新的最先进的方法进行比较。
2单步检测器(SSD)
本节介绍我们提出的用于检测的SSD框架(第2.1节)和相关的培训方法(第2.2节)。然后,第3节给出了具体数据集的模型细节和实验结果。

图1:SSD框架。(a) SSD只需要在训练过程中为每个对象输入图像和地面真值框。以卷积的方式,我们在几个不同尺度的feature map(如(b)和(c)中的8 x 8和4 x 4)中对每个位置上不同长宽比的一个小集合(如4)求值。对于每个默认框,我们预测所有对象类别((c1, C2,…C))。在训练时,我们首先将这些默认框与地面真相框匹配。例如,我们为猫匹配了两个默认框,为狗匹配了一个默认框,这两个默认框被认为是积极的,其余的被认为是消极的。模型损失是局部化损失(如光滑L1[6])和置信损失(如Softmax)之间的加权和。
2.1模型
SSD方法基于一个前向卷积网络,该网络生成一个固定大小的边界框集合,并根据这些框中对象类实例的存在程度进行评分,然后执行一个非最大抑制步骤,以产生最终的检测结果。早期的网络层基于用于高质量图像分类(在任何分类层之前截断)的标准体系结构,我们将其称为基础网络2。然后在网络中加入辅助结构,产生以下关键特征的检测:
在截断后的基网络的末端加入卷积特征层进行检测。这些层的大小逐渐减小,可以预测在多个尺度上的探测。对于每个特征层(cf Overfeat[4]和YOLO[5],它们在单一尺度的特征图上操作),用于预测检测的卷积模型是不同的。
用于检测的卷积预测器每个添加的特征层(或者可选地从基础网络中提取一个辅助特征层)可以使用一组卷积过滤器生成一组固定的检测预测。这些在图2中SSD网络结构的顶部表示。对于具有p通道的大小为m x n的特征层,预测潜在检测参数的基本方法是使用一个3x3xp小内核,它可以生成一个类别的分数,或者相对于默认框坐标的形状偏移量。在应用内核的m x n个位置上,它都会产生一个输出值。包围框偏移量输出值相对于默认值进行测量

图2:SSD和YOLO[5]两种单镜头检测模型的对比。我们的SSD模型在基本网络的末端添加了几个功能层,这些功能层预测不同规模和高宽比的默认盒的偏移量及其相关的置信度。输入尺寸为300×300的SSD在VOC2007测试的准确性上显著优于其448×448 YOLO版本,同时也提高了速度。
相对于每个feature map位置的box位置(参考YOLO[5]的架构,该架构使用一个中间的全连接层,而不是卷积过滤器)。
对于网络顶部的多个功能映射,我们将一组默认的边界框与每个功能映射单元关联起来。默认框以卷积方式平铺特征映射,因此每个框相对于其相应单元格的位置是固定的。在每个feature map单元格中,我们预测相对于单元格中的默认框形状的偏移量,以及每个类的分数,这些分数表示每个框中存在一个类实例。具体地说,对于给定位置上k之外的每个方块,我们计算cclass分数和相对于原始默认方块形状的4个偏移量。这将导致在特征映射的每个位置周围应用(c+4)k个过滤器,从而产生m x n特征映射的(c+4)kmn输出。有关默认框的说明,请参见图1。我们的默认框类似于fast R-CNN[2]中使用的锚框,但是我们将它们应用于不同分辨率的几个功能图。允许在几个功能图中使用不同的默认框形状,可以有效地离散可能的输出框形状空间。
2.2培训
训练SSD和训练典型的使用区域建议的检测器之间的关键区别在于,地面真值信息需要分配给固定的检测器输出集合中的特定输出。在YOLO[5]的训练和更快的R-CNN[2]和多盒[7]的区域建议阶段也需要一些版本。一旦这个分配被确定,损失函数和反向传播端到端被应用。训练还包括为检测选择一组默认的方框和刻度,以及硬负面挖掘和数据扩充策略。
在训练过程中,我们需要确定哪些默认的盒子与地面真实检测相匹配,并相应地训练网络。对于每个ground truth框,我们选择的是根据位置、长宽比和比例而变化的默认框。我们首先将每个ground truth框与具有最佳jaccard重叠的默认框匹配(如MultiBox[7])。与MultiBox不同的是,我们将默认框与jaccard重叠大于阈值(0.5)的任何ground truth匹配。这简化了学习问题,允许网络预测多个重叠的默认框的高分,而不是要求它只选择重叠最大的那个。



















总结,具体分析:
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小。由于各类物体有不同的形状、大小和数量,加上物体间还会相互遮挡, 因此目标检测一直都是机器视觉领域中最具挑战性的难题之一。
如上图所示,目标检测就是用一个矩形来定位一个物体并判断该物体是什么?现阶段,主流算法中表现最好的是SSD和YOLO,前者就是本文要用到的算法。实际上,不管是用SSD还是YOLO,目标检测过程都可以分解为两个独立的操作:

- 定位(location): 用一个矩形(bounding box)来框定物体,bounding box一般由4个整数组成,分别表示矩形左上角和右下角的x和y坐标,或矩形的左上角坐标以及矩形的长和高。
- 分类(classification): 识别bounding box中的(最大的)物体。
- “Single Shot”指的是单目标检测。
- “Box”就像是拍摄用的取景框,“Single Shot”的范围只限于框内,框外的内容一律屏蔽。
- “MultiBox”指的是用各种不同大小、形状的取景框覆盖整个图像。
- SSD 300 中输入图像的大小是 300x300,特征提取部分使用了 VGG16(5个卷积层+3个全连接层) 的卷积层,并将 VGG16的两个全连接层转换成了普通的卷积层(图中conv6和conv7),之后又接了多个卷积(conv8_1,conv8_2,conv9_1,conv9_2,conv10_1,conv10_2),最后用一个Global Average Pool来变成1x1的输出(conv11_2)。 从图中我们可以看出,SSD将conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2都连接到了最后的检测分类层做回归。具体细节如下图:

观察上述两幅图,我们可以初步得到SSD网络预测过程的基本步骤:
1、输入一幅图片(300x300),将其输入到预训练好的分类网络(改进的传统的VGG16 网络)中来获得不同大小的特征映射;
2、抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的Default boxes。然后分别进行检测和分类,生成多个初步符合条件的Default boxes;
3、将不同feature map获得的Default boxes结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的Default boxes,生成最终的Default boxes 集合(即检测结果);
设计理念
对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。
相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。
其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,
另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;
二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
1、采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如下图所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。

而其作用可以从下面的图片中的例子中得到很好的体现。图(a)中,浅层网络特征图很适合用来识别猫这一目标(蓝色方框),但面对狗这一目标,选框尺寸显得太小无法很好地将目标检测到。而到了深层网络,由于特征图经过池化层后尺寸减小,感受野变大。因此,红色选框可以较准确地识别到狗。究其原因,正是因为每一个特征图中都只能用尺度相同的选框(应称为Default boxes,后文会介绍),导致目标尺寸与选框尺寸差距过大时,无法完成理想检测。
从图(b)中更是可以直接感受到,采用多尺度特征用于检测可以提高识别的准确度。
2. 设置Default boxes
SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的Default boxes,预测的边界框(bounding boxes)是以这些Default boxes为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异。
对应上一条核心思想我们知道,Default boxes其实就是在某一feature map上每一点处选取的不同长宽比的选框。与YOLO不同的是,YOLO在每个位置只选取正方形选框,但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。
Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,共提取了6个特征图,其大小分别是(38,38)(19,19)(10,10)(5,5)(3,3)(1,1)。但是不同特征图设置的先验框数目不同。先验框的设置,包括尺度(scale)和长宽比(aspect ratio)两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:

这里smin是0.2,表示最底层的尺度是0.2,;smax是0.9,表示最高层的尺度是0.9。通过这种计算方法,可以得出6个特征图的default box尺度分别为:[30,60,111,162,213,264]。第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。
那么对于Conv4_3:k=1 min_size=s1x300 max_size=s2x300

边栏推荐
- The protection circuit of IO port inside the single chip microcomputer and the electrical characteristics of IO port, and why is there a resistor in series between IO ports with different voltages?
- 【Error】TypeError: expected str, bytes or os.PathLike object, not int
- Flutter | 给 ListView 添加表头表尾最简单的方式
- MySQL multi table query_ Inner connection_ Show internal connections
- Calendar日历类
- 快速学会使用文件的权限
- C#中单例模式的实现
- Transparent proxy server architecture of squid proxy service
- COPU副主席刘澎:中国开源在局部领域已接近或达到世界先进水平
- Do you know why PCBA circuit board is warped?
猜你喜欢









随机推荐
Squid 代理服务之透明代理服务器架构搭建
16 automated test interview questions and answers
Middle aged crisis, retired at the age of 35, what do migrant workers take to compete with capitalists?
Redis key has no expiration time set. Why was it actively deleted
学习笔记7--交通环境行为预测
AC自动机和Fail树
Redis' expiration strategy and memory elimination mechanism. Why didn't you release memory when the key expired
【2022新生学习】第二周要点
FreeRTOS个人笔记-创建/删除动态任务,启动调度器
946. Verify stack sequence ●● & sword finger offer 31. stack push in and pop-up sequence ●●
ICML 2022 | sparse double decline: can network pruning also aggravate model overfitting?
(resolved) idea compilation gradle project prompt error no symbol found
Calendar日历类
anchor free yolov1
Fastadmin, non super administrator, has been granted batch update permission, but it still shows no permission
Introduction to Huawei's new version of datacom certification
pytest接口自动化测试框架 | 控制测试用例执行
fio性能测试工具
【C语言】结构体、枚举和联合体
20220722挨揍记录