当前位置:网站首页>Dry goods!A highly structured and sparse linear transformation called Deformable Butterfly (DeBut)
Dry goods!A highly structured and sparse linear transformation called Deformable Butterfly (DeBut)
2022-08-03 10:49:00 【AITIME on Taoism】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

深度神经网络在各个领域都取得了很好的效果,例如图像识别,图像切割,自动驾驶,还有坏品检测等.但是深度神经网络由于其对计算和储存资源的较高要求,使得它很难部署在在资源有限的边缘设备上.
为了解决这一问题,许多方法被用来对模型进行压缩,常见的类型有:剪枝,量化,和低秩分解.
在这项工作中,我们用不同于上述任何类别的一种新的线性变换来对模型进行了压缩,名为Deformable Butterfly (DeBut).它是基于传统的Butterfly矩阵的一种泛化,可以适应各种输入输出维度,且继承了传统Butterfly矩阵从细粒度到粗粒度的可学习层次结构.当部署神经网络时,DeBut层的特殊结构和稀疏性构成了网络压缩的新方式.
我们将DeBut作为全连接层和卷积层的替代品来应用,并证明了它在同质化神经网络方面的优势,使其具有轻量和低复杂度等有利特性,而不致对准确率造成大幅影响.DeBut层的各种不同设计方式可以做到在复杂度和准确性之间进行基于不同考量的权衡,这为分析和实践研究开辟了新的空间.
本期AI TIME PhD直播间,We invited to the institute of electrical engineering at the university of Hong Kong PhD——林睿,为我们带来报告分享《一种被称为Deformable Butterfly(DeBut)的高度结构化且稀疏的线性变换》.

林睿:
香港大学(HKU)电子电气工程学院在读博士生,导师为黄毅教授,主要研究方向为神经网络的压缩和加速.个人主页:https://ruilin0212.github.io
Butterfly Matrix
我们可以把ButterflyMatrix as can be in the form of a series of special matrix to approximate any given matrix.Below the lower left corner is an example,它展示了如何用ButterflyMatrix to approximate a16*16大小的矩阵.Small blue squares represent the non-zero elements,White part represents the corresponding position of the element value as0.
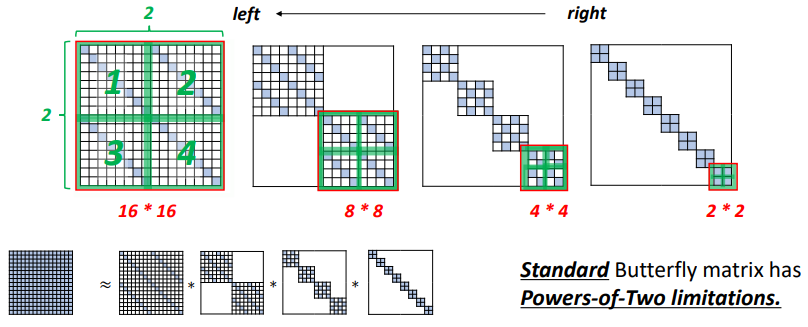
在16*16的情况中,我们可以观察到所有的ButterflyMatrix are partitioned matrix、对角矩阵.On the diagonal length and width are partitioned matrix2的n次方.
从右到左,We can observe the size of those partitioned matrix are kept getting bigger,从2*2、4*4到8*8、16*16.总的来说,这是标准的Butterfly矩阵,Can be seen as a block diagonal matrix.并且,Each partitioned matrix is by4A diagonal matrix composed of,这4A matrix to2*2的形式排列.
因此,很明显ButterflyMatrix in form is there2的nPower of the nature of the.具体来说,Is it the diagonal matrix must be2的n次方.But also must be partitioned matrix2的n次方.
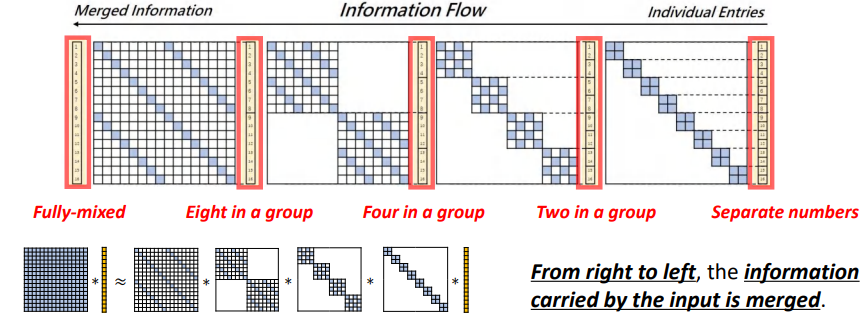
接下来,We are from the perspective of information to identify theButterfly的层次结构.
如下图左下角所示,We use a vector to from a given the size of the matrix to approximate a seriesButterfly因子.Below the upper part of every step shows the details:In the most right vector Numbers are used to tag element position,So from top to bottom is1到16.
These connections vector andButterflyFactor of the dotted line,The tag will be mixed in the vector elements and the correspondingButterflyFactor in the partitioned matrix,These partitioned matrix will play the role of the mixer,Will be marked element in the vector carries information together.
We can see that the location of the most the right side all indicators are mixed separate,和最右边的ButterflyAfter is multiplied by factor,The elements of information has been mixed up.从2到4,最终得到16Vector elements together,All elements are mixed together vector.
Convolution as a Matrix Product
到现在,We already know about the standardButterfly矩阵的性质,Next we'll look at how to interpret convolution for matrix multiplication.下图图AShows we understand the general form of convolution operation.这里有一些3DConvolution kernels and some input,The convolution kernels can slide along the two-dimensional plane of the input for,And then the corresponding pixel convolution.
After in these operations,We will get a tensor output.With the equivalent of general matrix multiplication,First will spread out the convolution kernel.The appearance of the red box in the diagram below shows,Every convolution kernels is expanded into a matrix.这个矩阵FThe number of rows and convolution kernels is equal,The number of columns is convolution kernels according to channel unfolds the length of the vector.
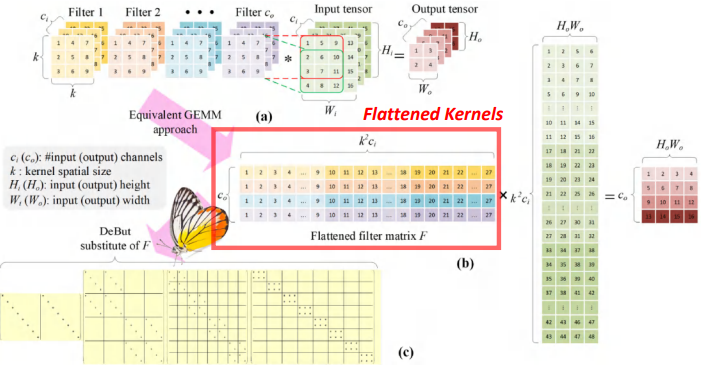
And the same convolution convolution kernels do pixel will be unfolded into a list of,同一个channelAre spread out and then the nextchannel展开.There are many target by matrix approximation of linear transformation of matrixF,于是我们思考DeButHow is linear change of matrix?DeButMatrix and standardButterflyWhat is the difference between matrix?
DeBut Chains
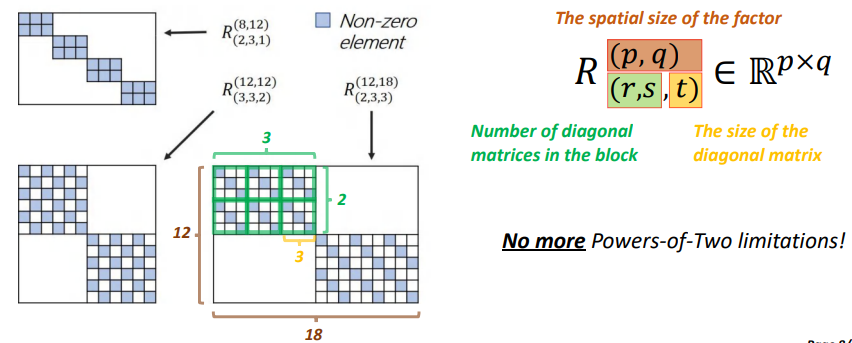
In the picture above shows leftDeButThe structure of the factor,The right explanation is used to mark theDeButWhat is the meaning of mark factor and how to understand.
Pictured above right,p,q表示的是DeBut factor的大小,r和sOn behalf of each block on the diagonal matrix of the diagonal matrix number.tRepresents the size of each diagonal matrix,We can use the left's biggestDeButFactors to explain the meaning of this symbol,(p,q)As mark foot on,(r,s,t)For the waste standard.
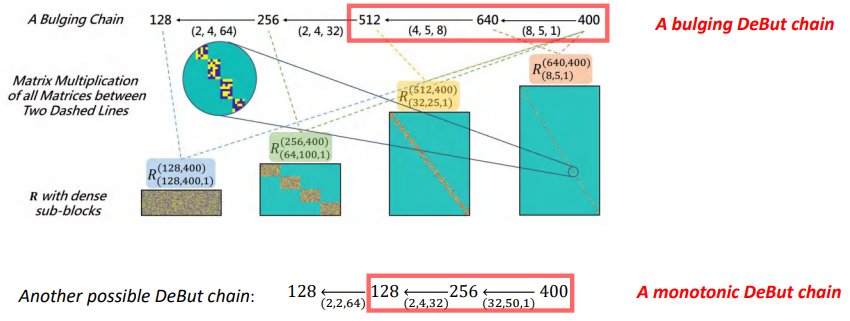
DeBut ChainCan understand as a series ofDeButFactor of a chain.We present two differentchainTo approximate a size as128*400的矩阵,分别为A bulging DeBut chain和A monotonic DeBut chain.

一般而言,我们是根据DeButThe size of the factors toDeBut Chain进行分类.如果一个DeBut ChainContains the factor of number of rows or columns is greater than the approximate matrix,DeBut Chain就会被当作bulging类型的chain,否则就是monotonic类型的.具体如上图所示,这两种chainThe structure of the can trumpet and clarinet respectively to describe.
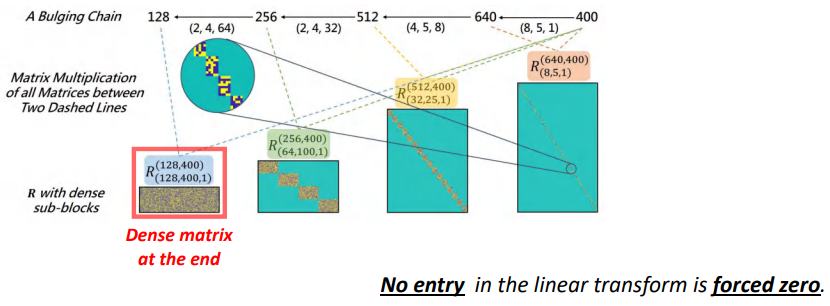
If we use a qualifiedchainTo approximate a matrix,Linear transformation of no matrix element is set to for a long time0.如果DeBut Chain是合格的,Show that no information is missing.
如上图所示,我们把所有的DeButAfter is multiplied by factor,Above the red box matrix is no long to0元素的,即DeBut ChainCan be used to approximate any given matrix.
Alternating Least Squares (ALS)
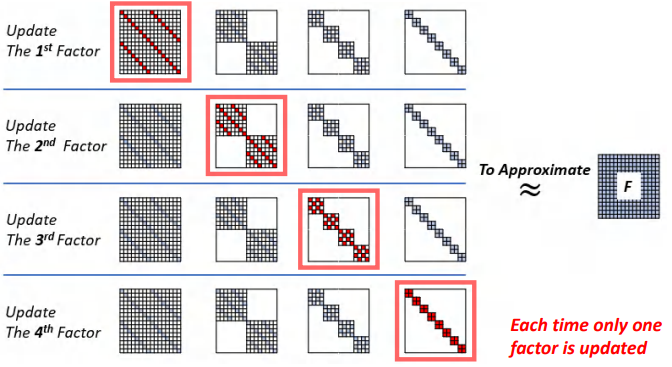
We need to know about alternating least squares inDeBut ChainInitialize the application,Mentioned before, we will useDeButFactor approximation of convolution kernel matrixF.To be a good training network,We can use the known parameters ofDeButInitialized factor.
如下图所示,Every time we update only achain中的一个因子,From left to right to update all the factor to update from right to left again,这个过程被称为1Timesweep.
We use the following formula to evaluate the performance of the approximate.
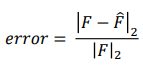
5Time is enough to have very good for small matrix initialization effect.
LeNet Trained on MNIST (Baseline: 99.29%)
在实验中,We first choseMNIST这个数据集,And then in a simpleLeNet上做测试.我们可以看到此时的Baseline是99.29%,In fact the whole connection layer can be seen as a convolution of,Its nuclear size and input spaceinput大小是相同的.
In order to quickly see thatDeBut有什么优势,我们挑选了LeNetIn the two larger convolution layer,采用了LC和MC两个指标.结果可以看出,DeButFor each selected layer can significantly improve.
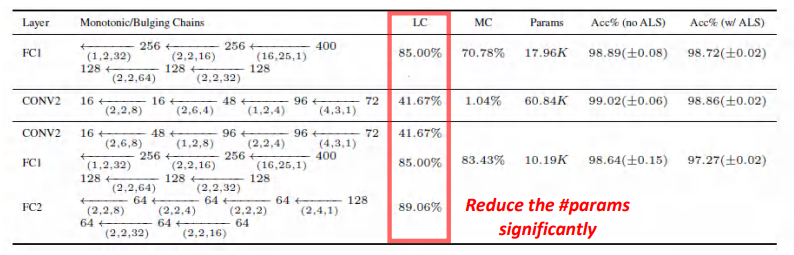
DeButTo further reduce the number of parameters,At the same time provide a good output precision.In the absence of alternating least squares,Model accuracy is one of the best,But that does not deny we proposeALS价值.In the model is more complicated,Our experimentALSThere is a improve accuracy effect.
VGG Trained on CIFAR-10 (Baseline: 93.96%)
我们继续用VGG在CIFAR-10上进行训练,And then you can see herebaseline是93.96%.
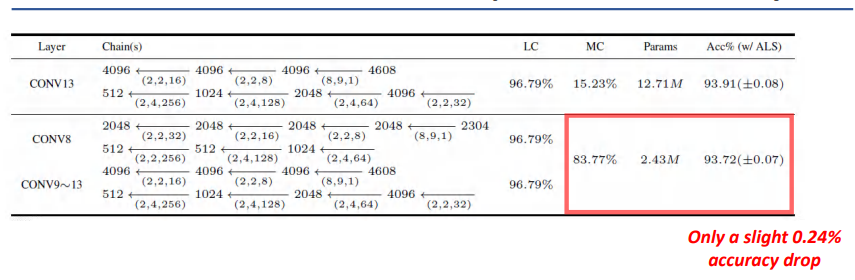
由上图,We can see the performance of alternating least squares is still good.
ResNet-50 Trained on ImageNet (Baseline: 76.01%)
我们用ResNet-50在ImageNet上继续 训练,ImageNetIs better than before with the data set is much larger and more complex data sets.As ablation experiment,We only use respectively the expansion of thechainOr the monotony ofchainTo choose the middle to replace.

对于DeBut-bulging,The number of parameters to reduce the47.56%,准确度最高的是74.52%,A baseline76.01%降低1.47%.

对于r DeBut-mono,Compression model thanDeBut-bulging少0.3M的参数,但仍然达到了74.34%的top-1精度.
DeBut vs. Other Linear Transform Schemes

最后,我们将DeButCompared with the other elements.After comparing with the closest solution,We found that it is stable.When attention is the last two columns in the chart above,我们发现DeButIs the quickest way to three methods of.
Adaptive Fastfood中的Fast Hadamard Transform 非常耗时,In largeCNNIn the multi-levelAdaptive FastfoodTraining is very difficult.
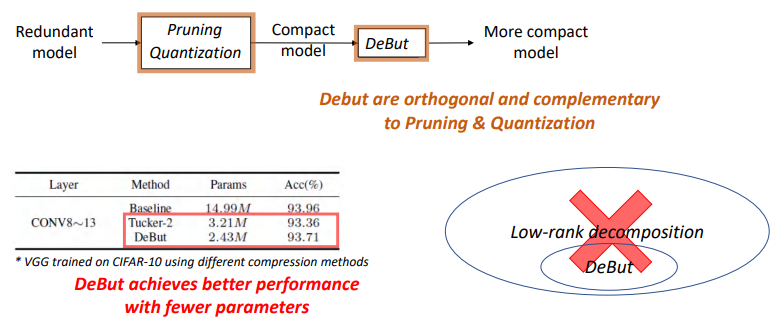
DeBut vs. Conventional Compression Schemes
我们还讨论了DeButThe relationship between the compression scheme with the very popular,Roughly divided into quantitative、剪枝等.To quantify and pruning,我们强调DeButIts are complementary,因为DeBut可以进一步压缩.
DeButIs a new kind of high absorbance of structure matrix factorization method.
Conclusion
● DeButLayer is a real and practical,Can be very complicated and large data sets in the network to realize.
● DeButIn essence and the convolution is different
● DeButFurther homogenize the whole connection layer and convolution,To lower the complexity of the breakthrough the standardButterfly矩阵2的nThe power limit
● 两种DeBut chainIn order to meet the requirements of different models,即compression ability, performance和stability的需求.
● DeBut factor product chainIn pipelining reasoningDNNAccelerated with the important revelation.
提
醒
论文题目:
Deformable Butterfly: A Highly Structured and Sparse Linear Transform
论文链接:
https://proceedings.neurips.cc/paper/2021/hash/86b122d4358357d834a87ce618a55de0-Abstract.html
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:林 睿
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来.
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾350场活动,超280万人次观看.

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
猜你喜欢




随机推荐
gbase在轨道交通一般都采用哪种高可用架构?
微信多开批处理(自动获取安装路径)
怎么在外头使用容器里php命令
Pixel mobile phone system
OS层面包重组失败过高,数据库层面gc lost 频繁
跨域问题的分析
Mysql OCP 74 questions
Mysql OCP 72题
GBase 8c与openGauss是什么关系?
多态详细讲解(简单实现买票系统模拟,覆盖/重定义,多态原理,虚表)
STM32入门开发 介绍SPI总线、读写W25Q64(FLASH)(硬件+模拟时序)
在安装GBase 8c数据库的时候,报错显示“Host ips belong to different cluster”。这是为什么呢?有什么解决办法?
js函数防抖和函数节流及其使用场景。
什么是IDE?新手用哪个IDE比较好?
通过GBase 8c Platform安装数据库集群时报错
GBase 8c分布式数据库,数据如何分布最优?
STM32+OLED显示屏制作指针式电子钟
Regulation action for one hundred days during the summer, more than 700 traffic safety hidden dangers were thrown out
在 Chrome 开发者工具里通过 network 选项模拟网站的离线访问模式
后台图库上传功能