当前位置:网站首页>pyhon爬虫之爬取图片(亲测可用)
pyhon爬虫之爬取图片(亲测可用)
2022-08-04 17:08:00 【我不是萧海哇~~~~】
爬取网站 https://image.baidu.com/
先打开页面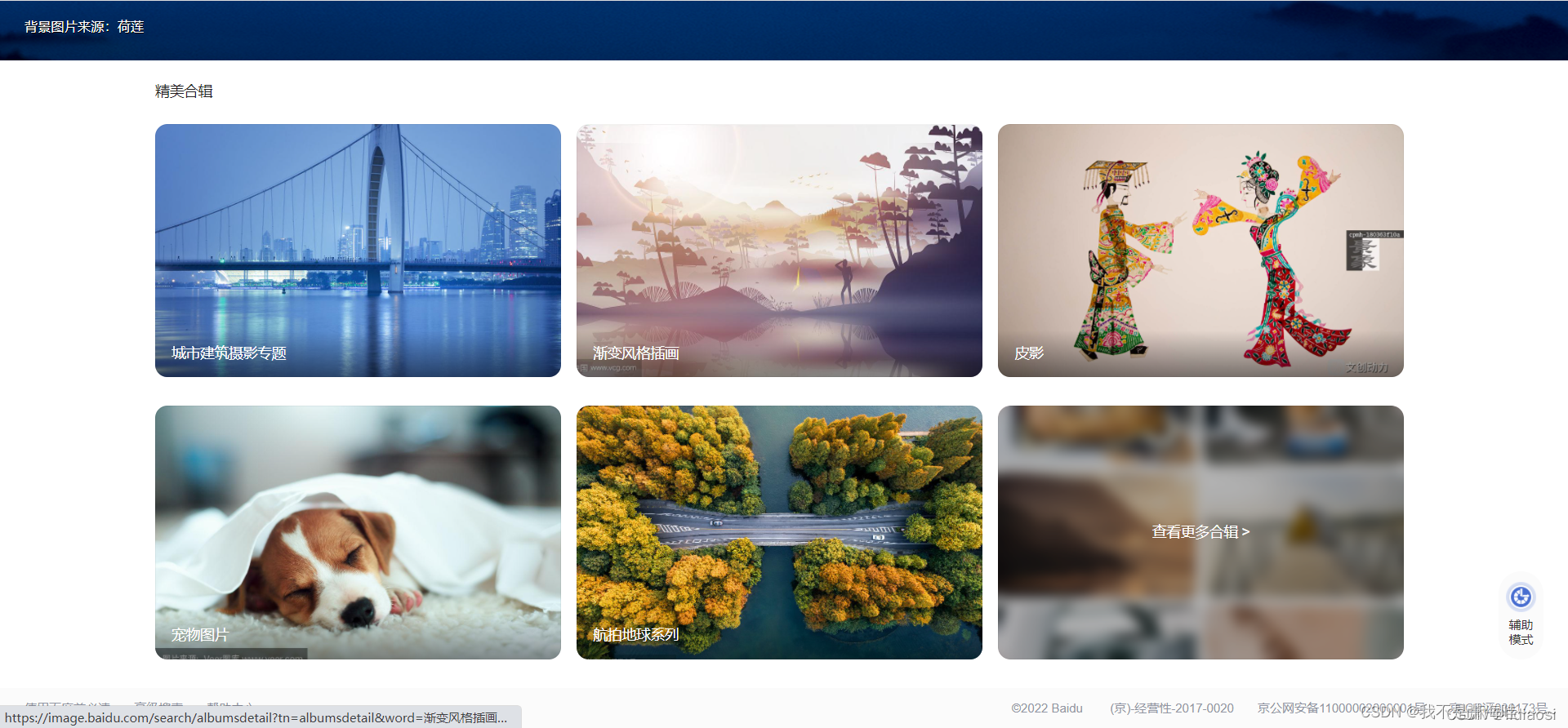
然后点击动物图片 当然选择哪个都可以我这里只是喜欢动物的所以选择这个分类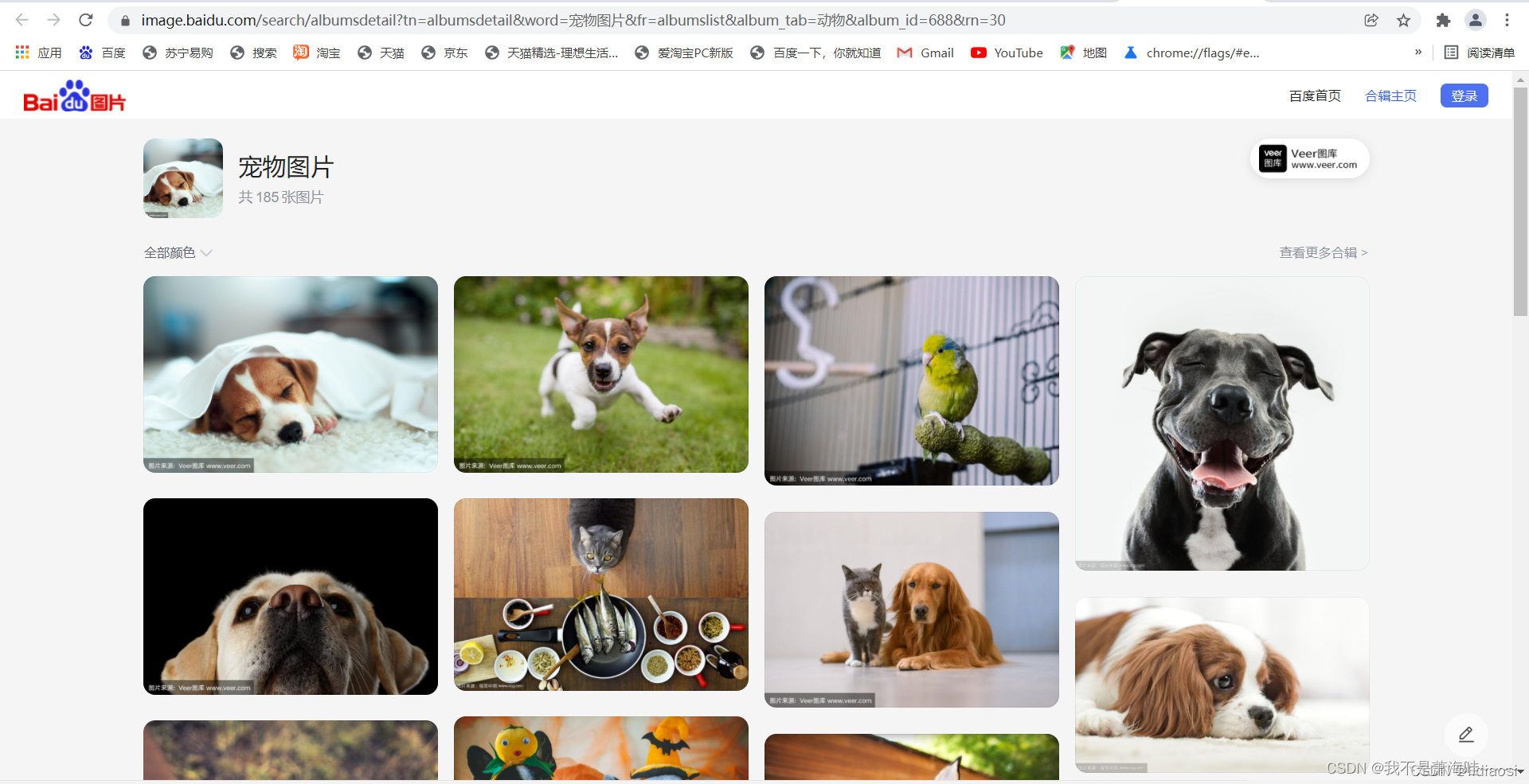
爬取任何数据 第一步就是先确定数据来源 先打开 f12 来看一下
先点击随便一个图片右键 然后点击检查 就会跳到那个图片所在的位置 如下: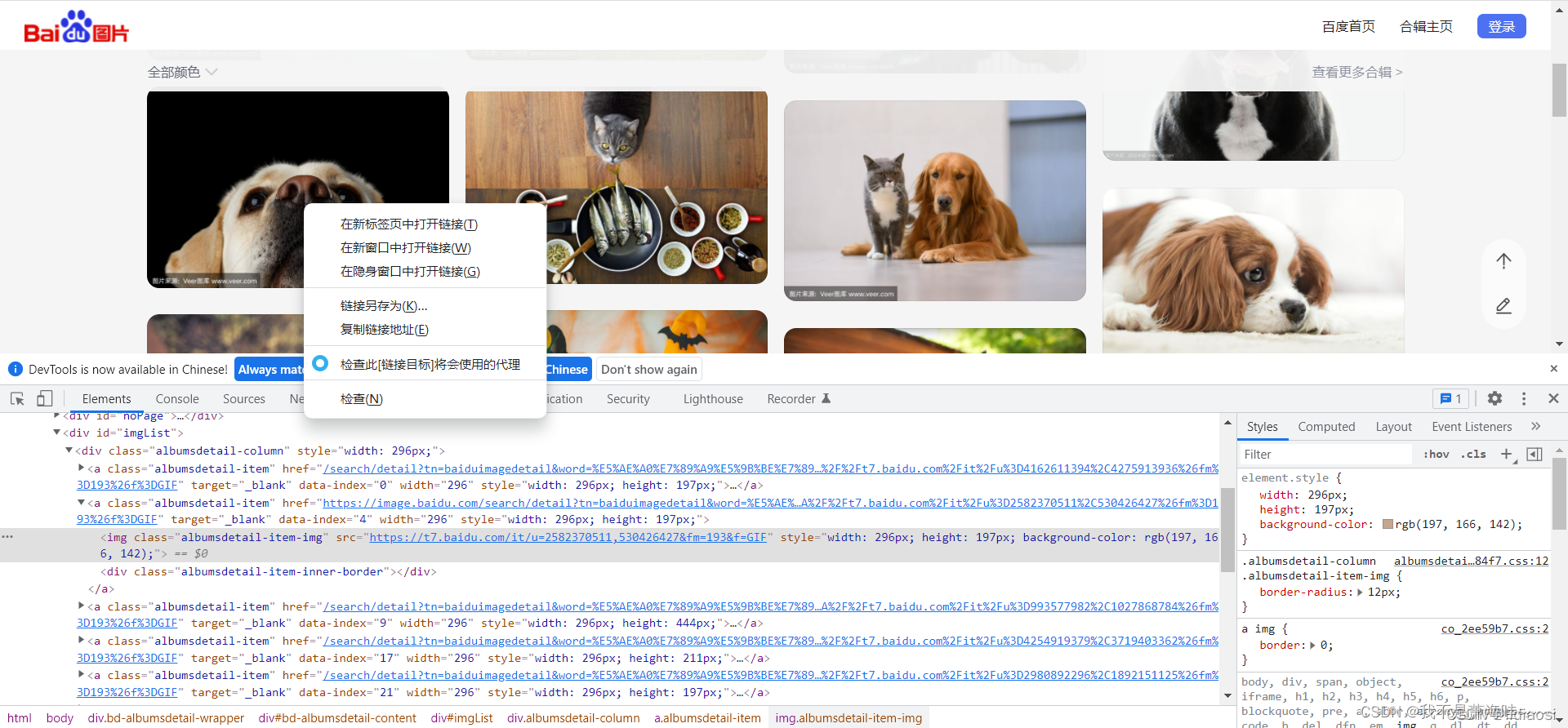
当看你看到响应里有确切的地址的时候 先不要着急爬取 先复制这个链接然后点击查看页面源代码(快捷键:ctr+U) 查找一下里面有没有这个地址
可以看的出来网页 源代码里面没有 到这一步就可以确定是用ajax异步来传送的数据
然后我们再f12 里面 点击Network 下面的XHR 进行页面刷新如下:
如果还没有出来数据 就把滚动条往下拉一下就可以看到有新的请求链接 记得多往下滚动一下 做一下对比 如下: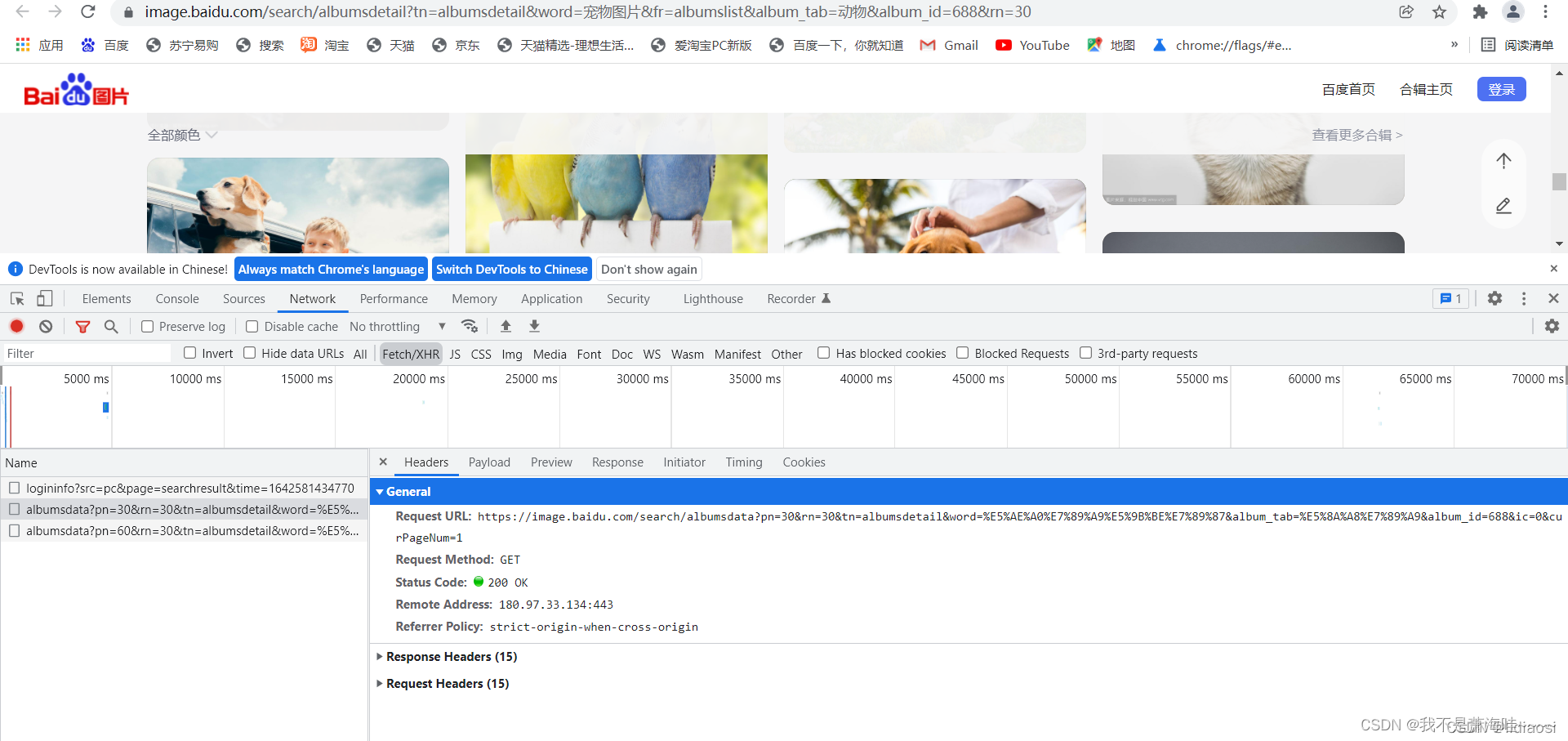
我们点开previem 可以看到是json格式 然后打开可以看到有30个图片的数据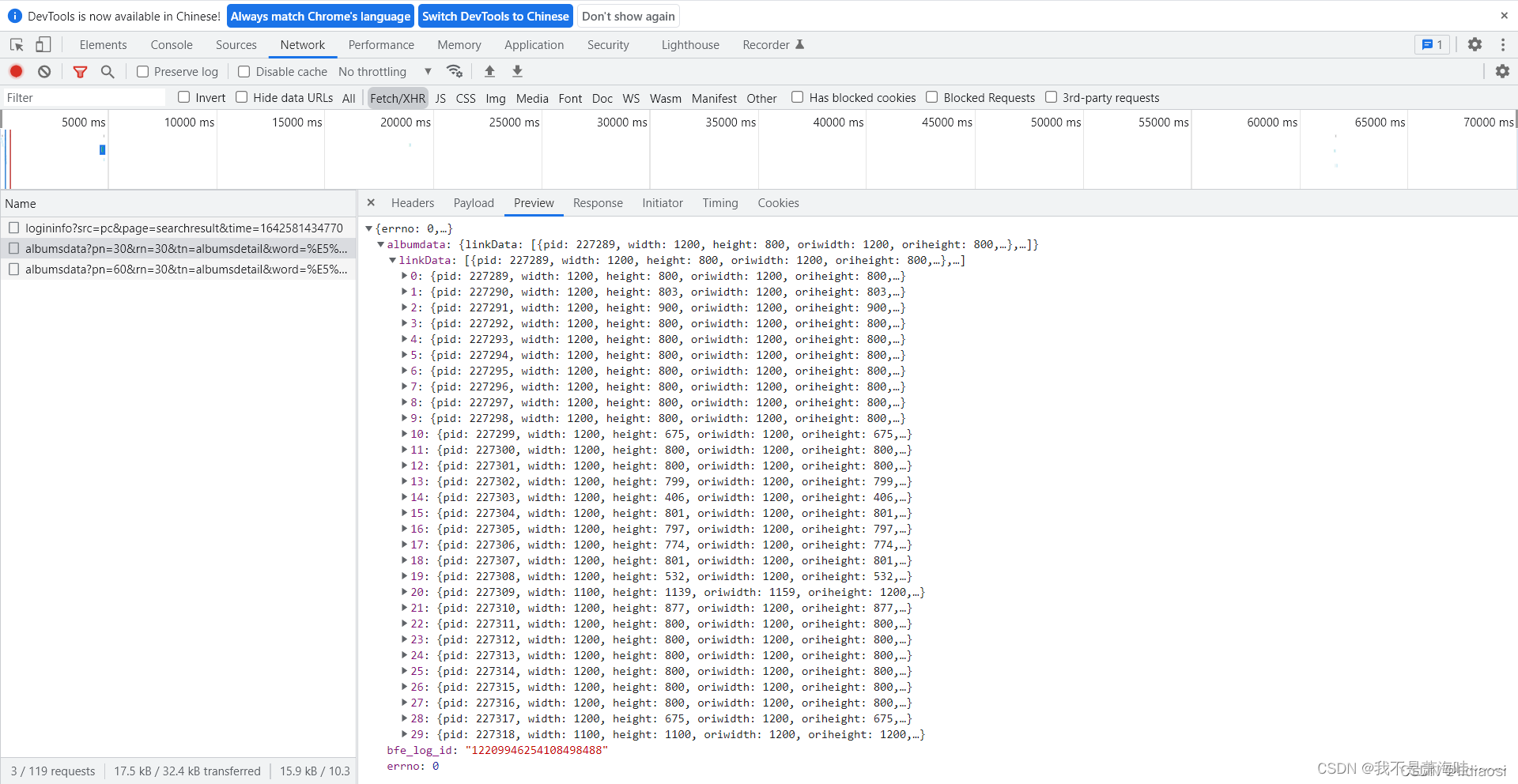
我们随便点开一个就可以看到里面 有明确的图片的源地址 我们可以复制打开一下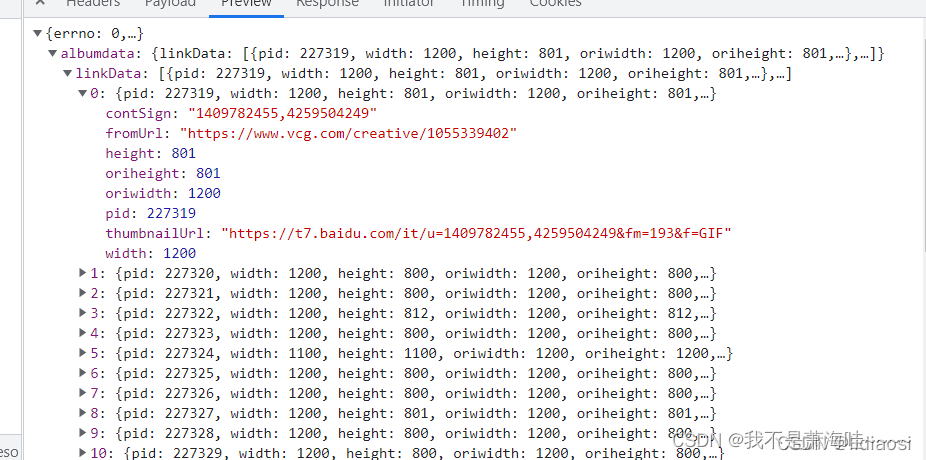
thumbnailUrl: 这里面就是源地址 可以打开看下 如下:
我们现在知道的图片的地址 但是要抓取所以图片就需要进行二级页面的爬虫
我们先把所有图片的地址抓取下来 先观察一下url
我们往下滑动就可以看到每一个请求都是pn值 和PageNum值 会变 那我们只需要再爬取的时候吧这两个值变动一下就可以了 我们可以看到每一个请求只有30个数据 那么还需要进行处理一下
接下来我们就开始写代码
我们先把所需要的模块导入进来如下:
# -*- coding:utf-8 -*-
# Author:Mr.屌丝
import json
import os.path
from hashlib import sha1
import requests
from fake_useragent import UserAgent
然后我们创建一个类 先吧所需要的headers 头和url 初始化一下如下:
class BaiduSpider: def __init__(self): # 初始化一下 头部 把刚刚变动的数据改成大括号 便于后面传参 我们中间的很长的那些是一些中文字 可以再页面看到的 这里我就不多说了 self.url = 'https://image.baidu.com/search/albumsdata?pn={}&rn=30&tn=albumsdetail&word=%E5%AE%A0%E7%89%A9%E5%9B%BE%E7%89%87&album_tab=%E5%8A%A8%E7%89%A9&album_id=688&ic=0&curPageNum={}' self.headers = {
'User-Agent': UserAgent().random
}
我这里还做了一个sha1加密功能函数 便于后期做增量 这里我是没有做的 只是应用于保存图片的名称
def sha1(self, href):
s = sha1()
s.update(href.encode())
return s.hexdigest()
接下来我们就开始爬数据了 第一个先爬取所以图片的源地址 代码如下:
def parse_html(self, url):
img_html = requests.get(url=url, headers=self.headers).text
# 我们这里需要把数据转换成json格式的数据
img_json = json.loads(img_html)
print(img_json)
def crawl(self):
# 这里进行计算是应该我们看到有185个图片 一个请求只有30个 所以我们计算一下需要发送几个请求
page = 185 // 30 if 185 % 30 == 0 else 185 // 30 + 1
for number in range(page):
number=number+1
pn = number * 30
self.parse_html(self.url.format(pn, number))
if __name__ == '__main__':
baidu = BaiduSpider()
baidu.crawl()
然后我们启动一下
然后我们打印一下抓取到的数据格式 如下: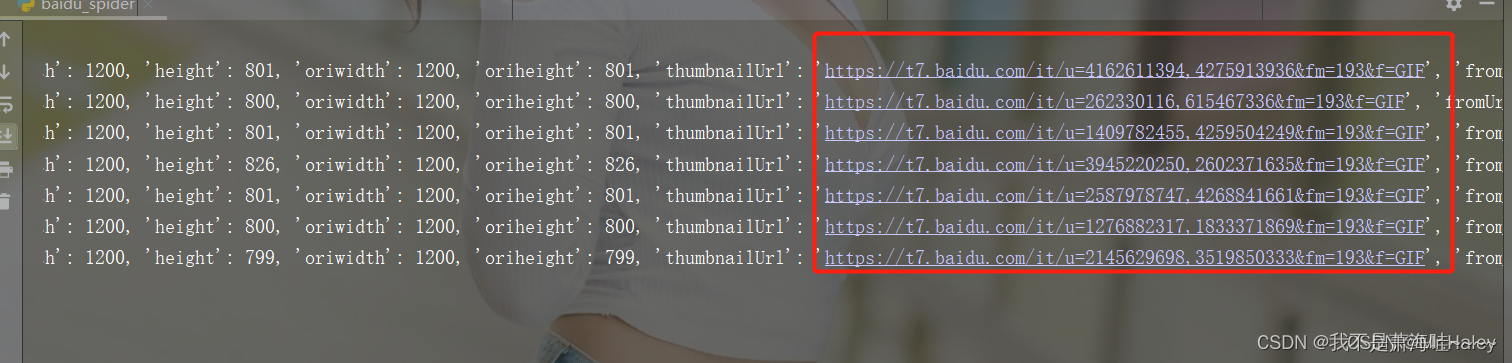
可以看到这里有我们的图片url 我们需要把所需要的rul提取出来 代码如下:
def parse_html(self, url):
img_html = requests.get(url=url, headers=self.headers).text
# 我们这里需要把数据转换成json格式的数据
img_json = json.loads(img_html)
# print(img_json)
for href in img_json['albumdata']['linkData']:
img_href = href['thumbnailUrl']
# 我们提取出来之后打印一下rul
print(img_href)
def crawl(self):
# 这里进行计算是应该我们看到有185个图片 一个请求只有30个 所以我们计算一下需要发送几个请求
page = 185 // 30 if 185 % 30 == 0 else 185 // 30 + 1
for number in range(page):
number=number+1
pn = number * 30
self.parse_html(self.url.format(pn, number))
if __name__ == '__main__':
baidu = BaiduSpider()
baidu.crawl()
结果如下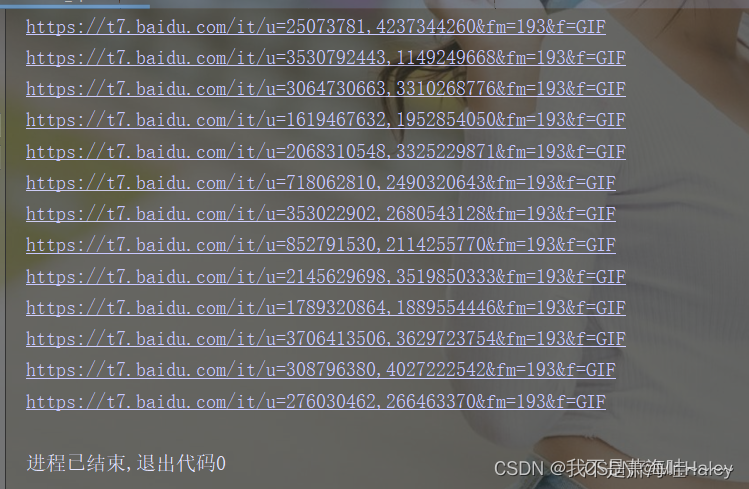
可以看到我们这里的结果没有问题 接下来我们需要把这些链接的图片下载保存在本地了
需要再写一个函数方法 方便与以后修改 代码如下:
def img_info(self, href):
# 二级页面请求 下载图片
html = requests.get(url=href, headers=self.headers).content
# 进行一个sha1的加密
sha1_r = self.sha1(href)
# 创建一个保存图片的路径
file = 'F:\Study\Spider\img\\'
# 完整保存图片的链接
filename = file + sha1_r + '.jpg'
# 判断有没有这个保存图片的路径 没有则创建
if not os.path.exists(file):
os.mkdir(file)
# 进行图片保存
with open(filename, 'wb') as f:
f.write(html)
# 打印一下图片的信息
print(filename)
好了 代码到这里就结束了 可能我说的不太好 多谢体谅
完整代码如下:
import json import os.path from hashlib import sha1 import requests from fake_useragent import UserAgent class BaiduSpider: def __init__(self): self.url='https://image.baidu.com/search/albumsdata?pn={}&rn=30&tn=albumsdetail&word=%E5%AE%A0%E7%89%A9%E5%9B%BE%E7%89%87&album_tab=%E5%8A%A8%E7%89%A9&album_id=688&ic=0&curPageNum={}' self.headers={
'User-Agent':UserAgent().random}
def sha1(self,href):
s=sha1()
s.update(href.encode())
return s.hexdigest()
# 爬取图片的原地址
def parse_html(self,url):
img_html=requests.get(url=url,headers=self.headers).text
# 转换成json
img_json=json.loads(img_html)
# print(img_json)
for href in img_json['albumdata']['linkData']:
img_href = href['thumbnailUrl']
# print(img_href)
self.img_info(img_href)
def crawl(self):
page=185//30 if 185%30==0 else 185 //30 +1
for number in range(page):
number=number+1
pn=number*30
self.parse_html(self.url.format(pn,number))
def img_info(self,href):
html=requests.get(url=href,headers=self.headers).content
# 进行sha1加密
sha1_r=self.sha1(href)
#创建一个保存图片的路径
file="baidu_img"
filename=file+"\\"+sha1_r+".jpg"
if not os.path.exists(file):
os.mkdir(file)
with open(filename,'wb') as f:
f.write(html)
print(filename)
if __name__ == "__main__":
print('hello')
baidu=BaiduSpider()
baidu.crawl()
边栏推荐
- Understand Chisel language. 32. Chisel advanced hardware generator (1) - parameterization in Chisel
- Hubei Telecom Tianyi TY1608_S905L3B_MT7668_ card brush firmware package
- 海报 | 夏季高温,危化品安全风险的注意事项必须get!
- 码蹄集 - MT2094 - 回文之时:第4组数据错误
- 【商家联盟】云平台—异业联盟,打造线上线下商业相结合的系统
- LeetCode 0167. 两数之和 II - 输入有序数组
- 不需要服务器,教你仅用30行代码搞定实时健康码识别
- 移动魔百盒CM211-1_YS代工_S905L3B_RTL8822C_线刷固件包
- 机器学习入门到大神专栏总览
- Compose 类型稳定性注解:@Stable & @Immutable
猜你喜欢





随机推荐
"Distributed cloud best practices" BBS, on August 11, shenzhen
乐享购(分享购)的模式:优势、亮点、收益
nyist 301 递推求值(矩阵快速幂)
JSP的Web监听器(Listener)
吃透Chisel语言.32.Chisel进阶之硬件生成器(一)——Chisel中的参数化
机器学习(十四):K均值聚类(kmeans)
机器人示教编程与离线编程的优缺点对比
码蹄集 - MT2165 - 小码哥的抽卡之旅1
hi, 请问下这是什么问题, 我看官网的example就是mysql的, 咋提示不支持?
开一个羽毛球馆大概需要多少钱?大约15万左右可以搞定!
九联_UNT400G_S905L2_(联通)_线刷固件包
软件基础的理论
机器学习(十一):KNN(K近邻)
浅谈运用低代码技术如何实现物流企业的降本增效
AtCoder Beginner Contest 262 部分题解
yarn detailed introductory tutorial
MySQL学习笔记-4.数据更新时的性能问题
RTL8762DK 远端设备配对
WEB 渗透之XXE&XML
yarn详细入门教程