当前位置:网站首页>MySQL-FlinkCDC-Hudi enters the lake in real time
MySQL-FlinkCDC-Hudi enters the lake in real time
2022-08-02 07:51:00 【smile 0628】
服务器基础环境
Maven和JDK环境版本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4EqE9oCl-1659193677331)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728083523967.png)]](/img/ec/88c2eb164d11dab5ddee8320288818.png)
Hadoop版本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qgPV8pY6-1659193677333)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728083555302.png)]](/img/a4/aae3945a48b96fd49d9eb31cc2f235.png)
Hadoop环境变量配置
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HADOOP_CALSSPATH=`$HADOOP_HOME/bin/hadoop classpath`
Hudi编译环境配置
Maven的setting.xml配置修改
<mirrors>
<mirror>
<id>alimaven</id>
<mirrorOf>central,!cloudera</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
</mirrors>
下载Hudi源码包
git clone https://github.com/apache/hudi.git
修改Hudi集成Flink和Hive编译依赖版本配置
packaging/hudi-flink-bundle/
pom.xml文件根据hiveThe environment is modified by itself
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SNFpDjwS-1659193677334)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728084806825.png)]](/img/3b/5cf38e0249fd1371cd8cf3209ffbbc.png)
编译Hudi指定Flink和Hadoop和Hive版本信息
可加 –e –X 参数查看编译ERROR异常和DEBUG信息
说明:默认scala2.11、默认不包含hive依赖
mvn clean install -DskipTests-Drat.skip=true -Dflink1.13 -Dscala-2.11 -Dhadoop.version=3.1.3 -Pflink-bundle-shade-hive3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKSaZy2W-1659193677335)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728085143743.png)]](/img/5b/7f0ec50593379a83e185b563f2e47a.png)
Hudi编译结果说明
hudi-flink-bundle.jar是flink用来写入和读取数据
hudi-mr-bundle.jar 是hive需要用来读hudi数据
Flink环境配置
版本说明:Flink1.13.6和scala2.11版本
Flink_HOME下的yaml配置
# state.backend: filesystem
state.backend: rocksdb
# 开启增量checkpoint
state.backend.incremental: true
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.checkpoints.dir: hdfs://nameservice/flink/flink-checkpoints
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
FLINK_HOME的lib下添加依赖
flink-sql-connector-mysql-cdc-2.2.1.jar
flink-sql-connector-kafka_2.11-1.13.6.jar
--- Hadoop home lib下copy过来
hadoop-mapreduce-client-common-3.1.3.jar
hadoop-mapreduce-client-core-3.1.3.jar
hadoop-mapreduce-client-jobclient-3.1.3.jar
guava-27.0-jre.jar
--- hudi编译jar copy过来
hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F8SXRRKx-1659193677336)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728093326450.png)]](/img/98/dfa6417132a19ee62e9f0a1b83a92c.png)
启动Flink Yarn Session服务
export HADOOP_HOME='/opt/module/hadoop-3.1.3'
export HADOOP_CONF_DIR='/opt/module/hadoop-3.1.3/etc/hadoop'
export HADOOP_CONFIG_DIR='/opt/module/hadoop-3.1.3/etc/hadoop'
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CALSSPATH=`$HADOOP_HOME/bin/hadoop classpath`
bin/yarn-session.sh -s 2 -jm 2048 -tm 2048 -nm ys_hudi -d
各类UI查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HnyrTOmo-1659193677337)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728093429724.png)]](/img/74/8242c7dbc91a584100b646e78dc7d3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vNT128IS-1659193677337)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728093443418.png)]](/img/1b/b6b6cdde41eaef4c3e2c3036d5319a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iS4echuv-1659193677339)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728093457796.png)]](/img/dc/d6b4c717c8ba7c17b7d51e1f4d4173.png)
启动Flinksql Client
bin/sql-client.sh embedded -s yarn-session
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M8db9qHK-1659193677339)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728093758008.png)]](/img/ca/799988a83f02eeaa78012bbc7271dc.png)
FlinkCDC sink Hudi过程
MySQL测试建表语句
create table users_cdc(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default CURRENT_TIMESTAMP not null,
ts timestamp default CURRENT_TIMESTAMP not null
);
FlinkCDC DDL语句
CREATE TABLE mysql_users (
id BIGINT PRIMARY KEY NOT ENFORCED ,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector'= 'mysql-cdc',
'hostname'= 'bigdata',
'port'= '3306',
'username'= 'root',
'password'= 'root',
'server-time-zone'= 'Asia/Shanghai',
'debezium.snapshot.mode'='initial',
'database-name'= 'db1',
'table-name'= 'users_cdc'
);
查询mysql-cdc表
select * from mysql_users;
由于目前MySQL users_cdc表是空,所以flinksql 查询没有数据 只有表结构;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vcr0Hdwc-1659193677340)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094219815.png)]](/img/6c/54add64801ea767d1c69bfabc45da9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zVUD5QDe-1659193677341)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094237502.png)]](/img/63/1206185d678c977bdc94cdc1df20d6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IFkBA5f3-1659193677341)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094256898.png)]](/img/a4/faf320cf4d32fa3b72eef39396285c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wjuy1nQO-1659193677342)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094344070.png)]](/img/39/96e699baac7417d17bf8e9841cf7dd.png)
创建临时视图,增加分区列,方便同步hive分区表
create view mycdc_v AS SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') as `partition` FROM mysql_users;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uTLnJ8t2-1659193677343)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094457810.png)]](/img/24/e53209a6f456df2bafd0c592eb9302.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z6fzvLqt-1659193677344)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728094609578.png)]](/img/25/b9728d358c0102f9fa9d75cb5465bb.png)
设置checkpoint间隔时间,存储路径已在flink-conf配置设置全局路径
建议:测试环境 可设置秒级别(不能太小),生产环境可设置分钟级别
set execution.checkpointing.interval=30sec;
Flinksql 创建 cdc sink hudi文件,并自动同步hive分区表DDL 语句
CREATE TABLE mysqlcdc_sync_hive01(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
`partition` VARCHAR(20),
primary key(id) not enforced --必须指定uuid 主键
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi'
,'path'= 'hdfs://bigdata:8020/hudi/mysql_cdc_sync_hive_01'
, 'hoodie.datasource.write.recordkey.field'= 'id'-- 主键
, 'write.precombine.field'= 'ts'-- 自动precombine的字段
, 'write.tasks'= '1'
, 'compaction.tasks'= '1'
, 'write.rate.limit'= '2000'-- 限速
, 'table.type'= 'MERGE_ON_READ'-- 默认COPY_ON_WRITE,可选MERGE_ON_READ
, 'compaction.async.enabled'= 'true'-- 是否开启异步压缩
, 'compaction.trigger.strategy'= 'num_commits'-- 按次数压缩
, 'compaction.delta_commits'= '1'-- 默认为5
, 'changelog.enabled'= 'true'-- 开启changelog变更
, 'read.streaming.enabled'= 'true'-- 开启流读
, 'read.streaming.check-interval'= '3'-- 检查间隔,默认60s
, 'hive_sync.enable'= 'true'-- 开启自动同步hive
, 'hive_sync.mode'= 'hms'-- 自动同步hive模式,默认jdbc模式
, 'hive_sync.metastore.uris'= 'thrift://bigdata:9083'-- hive metastore地址
, 'hive_sync.jdbc_url'= 'jdbc:hive2://bigdata:10000'-- hiveServer地址
, 'hive_sync.table'= 'mysql_cdc_sync_hive_01'-- hive 新建表名
, 'hive_sync.db'= 'czs'-- hive 新建数据库名
, 'hive_sync.username'= 'root'-- HMS 用户名
, 'hive_sync.password'= 'root'-- HMS 密码
, 'hive_sync.support_timestamp'= 'true'-- 兼容hive timestamp类型
);
Flink sql mysql cdc数据写入hudi文件数据
insert into mysqlcdc_sync_hive01 select id,name,birthday,ts,`partition` from mycdc_v;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4JpHjhWT-1659193677345)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095247628.png)]](/img/36/ba363f74ff5449aad99894dcf68c35.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q9BxZxG6-1659193677346)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095336639.png)]](/img/20/a2d8ca9703c422d1fa684291e079c7.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ypr0uYOj-1659193677347)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095442238.png)]](/img/7c/b7a577c2faacabd169cec836d9cb38.png)
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IVHFBpJa-1659193677348)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095449769.png)\]](https://img-blog.csdnimg.cn/3949de15ec1c43768c0ee1e3b3f7a8d4.png)
说明:目前还没写入测试数据,hudi目录只生成一些状态标记文件,还未生成分区目录以及.log 和.parquet数据文件,具体含义可见hudi官方文档.
Mysql数据源写入测试数据
insert into users_cdc (name) values ('cdc01');
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kIhzA2v9-1659193677349)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095606811.png)]](/img/33/55595cfc0e8b6146714927e8a8bd0e.png)
Flinksql 查询mysql cdc insert数据
set sql-client.execution.result-mode=tableau;
select * from mysql_users; -- 查询到一条insert数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ggl6uyph-1659193677350)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095737921.png)]](/img/3d/b5db7eb91328a8b02b2e901140de1d.png)
Flink web UI页面可以看到DAG 各个环节产生一条测试数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mecyR5NC-1659193677351)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095835764.png)]](/img/85/d6c3ae6a1f94c1aaaa097d713e8ba7.png)
Flinksql 查询 sink的hudi表数据
select * from mysqlcdc_sync_hive01; --已查询到一条insert数据
Hdfs上Hudi文件目录变化情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WI1xHRoa-1659193677352)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728095926525.png)]](/img/1c/5855c44af7d382eace1b98fe725802.png)
Hive分区表和数据自动同步情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yquZzcVp-1659193677353)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728100025441.png)]](/img/ba/c63c61b06049f4bdf56f92794a5096.png)
查看自动创建hive表结构
show create table mysql_cdc_sync_hive_01_ro;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GWrY1l92-1659193677353)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728100141605.png)]](/img/b3/c65044ddc584e48946860ace17cbd5.png)
show create table mysql_cdc_sync_hive_01_rt;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E2OiDZLA-1659193677354)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728100219069.png)]](/img/96/9429181752f61abb3bdb153fe2829d.png)
查看自动生成的表分区信息
show partitions mysql_cdc_sync_hive_01_ro;
show partitions mysql_cdc_sync_hive_01_rt;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GPOEMyRY-1659193677355)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728100511300.png)]](/img/3e/c7f2527e64599fcce2ce3a93054682.png)
说明:已自动生产hudi MOR模式的ro、rt
ro表只能查parquet文件数据,input是HoodieParquetInputFormat
rt表parquet文件数据和log文件数据都可查,input是HoodieParquetRealtimeInputFormat
Hive访问Hudi数据
说明:需要引入hudi-hadoop-mr-bundle
引入方式如下:
- 引入到$HIVE_HOME/lib下
- 引入到$HIVE_HOME/auxlibCustom third-party dependency modification hive-site.xml配置文件
- Hive shell命令行引入 Session级别有效
其中1和3配置完后需要重启hive-server服务
查询Hive 分区表数据
select * from mysql_cdc_sync_hive_01_ro; --已查询到mysq insert的一条数据
select * from mysql_cdc_sync_hive_01_rt; --已查询到mysq insert的一条数据
select name,ts from mysql_cdc_sync_hive_01_ro where `partition`='20220728'; --条件查询
select count(1) from mysql_cdc_sync_hive_01_ro; --Hive ro表count查询
select count(1) from mysql_cdc_sync_hive_01_ro; --Hive rt表count查询
hive count异常解决
引入hudi-hadoop-mr-bundle依赖
hive> add jar hdfs://bigdata:8020/czs/hudi-hadoop-mr-bundle-xxx.jar;
hive> set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
Mysql数据源写入多条测试数据
insert into users_cdc (name) values ('cdc02');
insert into users_cdc (name) values ('cdc03');
insert into users_cdc (name) values ('cdc04');
insert into users_cdc (name) values ('cdc05');
insert into users_cdc (name) values ('cdc06');
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QTyOyoqO-1659193677356)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728102129796.png)]](/img/1d/2f7f89e0b3f81f07b5645b8f2c9a52.png)
Flink web UI DAG中数据链路情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YiiAA1st-1659193677357)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728102448147.png)]](/img/93/405c662ad441e7d034b13e7efa29ec.png)
Hdfs上Hudifile directory changes
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G5l6KLhV-1659193677357)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728102539505.png)]](/img/61/87c406138d3f788c7a1213f7411ebf.png)
状态文件说明:
(1)requested:表示一个动作已被安排,但尚未启动
(2)inflight:表示当前正在执行操作
(3)completed:表示在时间线上完成了操作
Flink jobmanager log sync hive过程详细日志
搜索mysqlcdc_sync_hive01即定义的hudi表名
Mysql数据源更新数据
update users_cdc set name = 'cdc05-bj'where id = 5;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F0Fejv7N-1659193677358)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103059014.png)]](/img/2b/0117804e5276e7b3df4a6e8bcf18ba.png)
Flinksql 查询cdc update数据 产生两条binlog数据
说明:flinksql 查询最终只有一条+I有效数据,且数据已更新
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qJo7hK8Y-1659193677359)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103624204.png)]](/img/34/05e59aaec0b0e026d3bab2d9b94be2.png)
Flink web UI DAG接受到两条binlog数据,但最终compact和sink只有一条有效数据
MySQLThe data source deletes the data
delete from users_cdc where id = 3;
select * from users_cdc;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TweF0jCz-1659193677360)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103707074.png)]](/img/3d/d90f0dc00b60fe085489706bcd884e.png)
Flink Web UI job DAG中捕获一条新数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u9JeYvo5-1659193677361)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103830934.png)]](/img/3d/bd734248c439ec2cbd811448eefcdc.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r21AedMU-1659193677362)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103857502.png)]](/img/4c/3c8956aa88be988ddef9454ad600e4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RytUzfmn-1659193677363)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728103941080.png)]](/img/f6/6be77f598ae5c816d298821c4b66d2.png)
Hudi文件类型说明:
(1)commits: 表示将一批数据原子性写入表中
(2)cleans: 清除表中不在需要的旧版本文件的后台活动
(3)delta_commit:增量提交是指将一批数据原子性写入MergeOnRead类型的表中,其中部分或者所有数据可以写入增量日志中
(4)compaction: 协调hudi中差异数据结构的后台活动,例如:将更新从基于行的日志文件变成列格式.在内部,压缩的表现为时间轴上的特殊提交
(5)rollback:表示提交操作不成功且已经回滚,会删除在写入过程中产生的数据
Flink CK情况
设置的30s一次CK
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fN7Gdykt-1659193677364)(C:\Users\Chen Zhangsheng\AppData\Roaming\Typora\typora-user-images\image-20220728104101134.png)]](/img/1b/c65dcdb17c67b666d805e50924d040.png)
边栏推荐
猜你喜欢

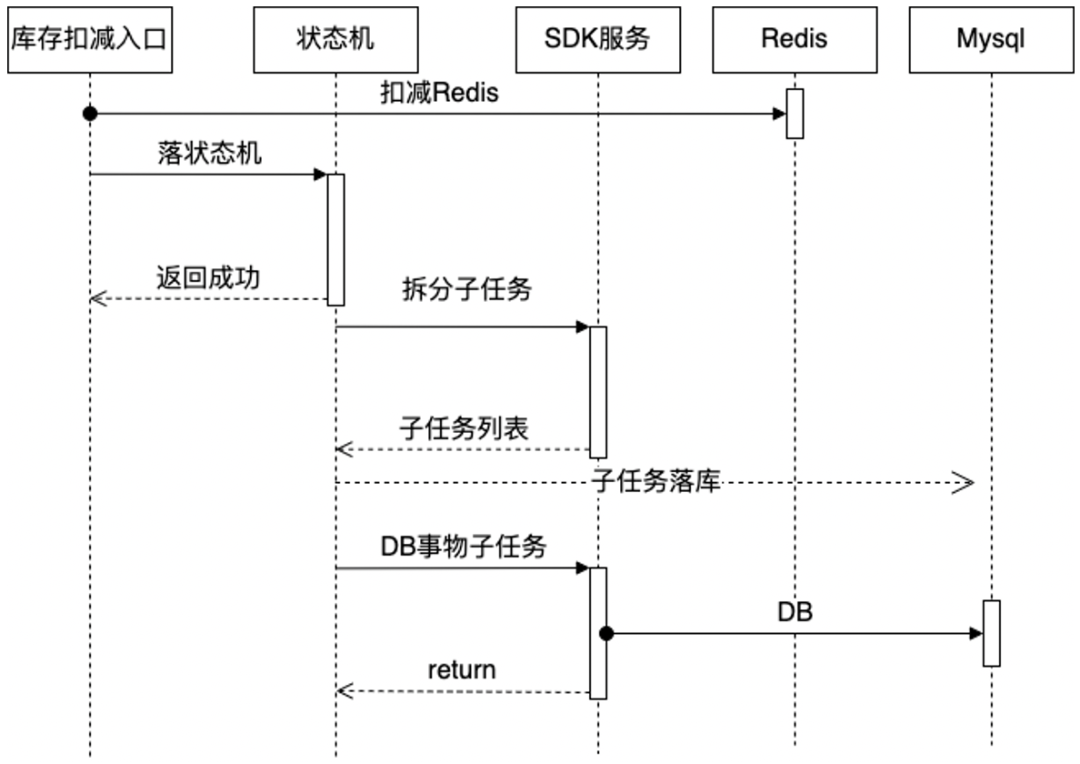
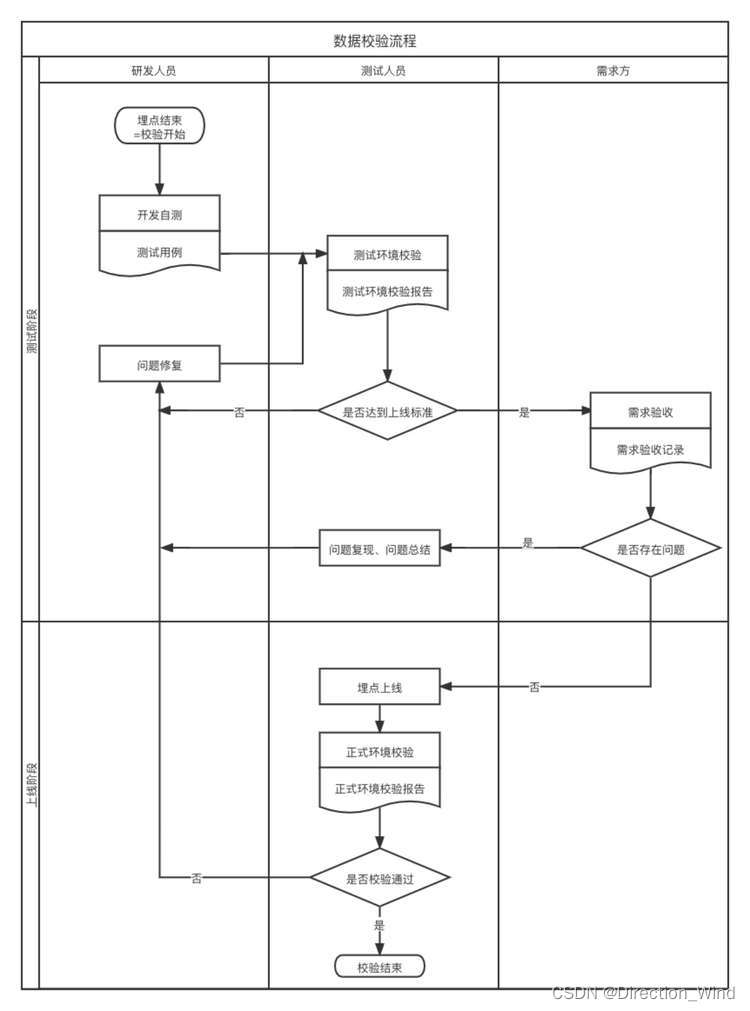



随机推荐
MySQL-多版本并发控制
Redis 常用命令和基本数据结构(数据类型)
解决Pytorch模型在Gunicorn部署无法运行或者超时问题
分离轴定理SAT凸多边形精确碰撞检测
59:第五章:开发admin管理服务:12:MongoDB的使用场景;(非核心数据,数据量比较大的非核心数据,人脸照片等隐私的小文件;)
CSRF-跨站请求伪造-相关知识
从云计算到函数计算
入门opencv,欢笑快乐每一天
Go 实现分布式锁
线程的创建方式
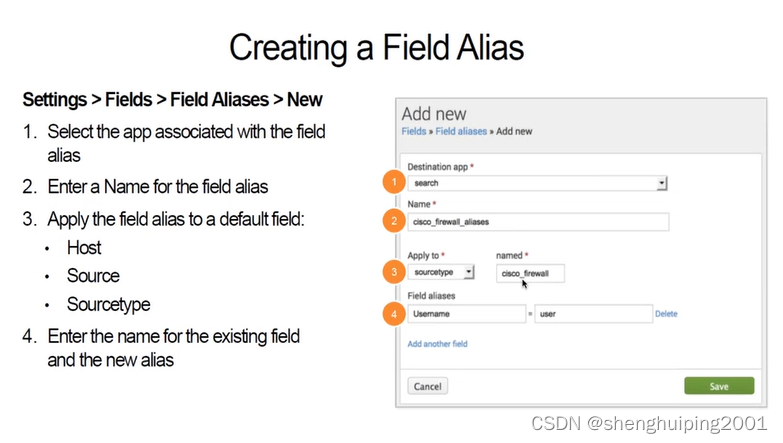
Splunk Filed Alias 字段改名
正则表达式的理解学习
堡垒机、堡垒机的原理
OC-NSArray
FaceBook社媒营销高效转化技巧分享
OC - NSSet (set)
图腾柱和推挽电路介绍
【ROS基础】map、odom、base_link、laser 的理解 及其 tf 树的理解
实例030:回文数
跨阻放大器