当前位置:网站首页>Understand CRF
Understand CRF
2022-06-13 02:17:00 【zjuPeco】
List of articles
1 Preface
Conditional random field (conditional random field, CRF) It is a common module when building a sequence model , Its essence is to describe the observed sequence x ˉ \bar{x} xˉ Corresponding state sequence y ˉ \bar{y} yˉ Probability , Write it down as P ( y ˉ ∣ x ˉ ) P(\bar{y}|\bar{x}) P(yˉ∣xˉ). The horizontal line on the character here indicates that this is a sequence , All the sequences below will have this horizontal line , No horizontal line is not a sequence .
It is HMM Upgraded version , If you're not familiar with HMM Words , I suggest you look at my understand HMM This article , Don't read that , It doesn't matter to read this article directly .
Put forward CRF It's for improvement MEMM(maximum-entropy Markov model) Of label bias problem , And proposed MEMM Is to break HMM Of Observation independence Hypothesis . These will be explained further below .
This paper mainly refers to Log-Linear Models, MEMMs, and CRFs, Some additional things will be added , And add some understanding .
2 Log-linear model
CRF The source of is Log-linear model, It is a little bit improved by it .
Let us first assume that the observed variable is x x x, The observation set is X X X, Yes x ∈ X x \in X x∈X, such as x x x It's a word ; The state variable is y y y, The set of States is Y Y Y, Yes y ∈ Y y \in Y y∈Y, such as y y y It's a part of speech ; The function vector for feature extraction is ϕ ˉ ( x , y ) \bar{\phi}(x, y) ϕˉ(x,y), There is a horizontal line here , Indicates that there are multiple functions ; The weight between functions is w ˉ \bar{w} wˉ. So in the given x x x Under the circumstances , y y y The probability of is ( For example, words x x x Is part of speech y y y Probability )
p ( y ∣ x ; w ˉ ) = e x p ( w ˉ ⋅ ϕ ˉ ( x , y ) ) ∑ y ′ ∈ Y e x p ( w ˉ ⋅ ϕ ˉ ( x , y ′ ) ) (2-1) p(y|x;\bar{w}) = \frac{exp(\bar{w} \cdot \bar{\phi}(x, y))}{\sum_{y' \in Y} exp(\bar{w} \cdot \bar{\phi}(x, y'))} \tag{2-1} p(y∣x;wˉ)=∑y′∈Yexp(wˉ⋅ϕˉ(x,y′))exp(wˉ⋅ϕˉ(x,y))(2-1)
type ( 2 − 1 ) (2-1) (2−1) The molecule of represents a given x x x when , y y y The exponential formula when taking a certain value ; The denominator denotes a given x x x when , y y y Take the sum of the exponential formulas for all cases . To put it bluntly, it is a normalization operation .
Use index e x p exp exp To ensure that the probabilities are positive , w ˉ ⋅ ϕ ˉ ( x , y ) \bar{w} \cdot \bar{\phi}(x, y) wˉ⋅ϕˉ(x,y) Positive but negative .
Obvious , Under this definition... Can be guaranteed
∑ y ∈ Y p ( y ∣ x ; w ˉ ) = 1 (2-2) \sum_{y \in Y} p(y|x;\bar{w}) = 1 \tag{2-2} y∈Y∑p(y∣x;wˉ)=1(2-2)
Suppose we have n n n Group tagged data { ( x i , y i ) } i = 1 n \{(x_i, y_i)\}_{i=1}^{n} { (xi,yi)}i=1n, There is no sequence involved here , It can be understood as a word x i x_i xi Corresponding to a part of speech y i y_i yi Data set of .
Our aim is to adjust the parameters of the model w ˉ \bar{w} wˉ, This makes it most likely that a label correspondence such as a dataset will occur , That is to say
w ˉ ∗ = a r g max w ˉ ∏ i = 1 n p ( y i ∣ x i ; w ˉ ) (2-3) \bar{w}^* = arg \max_{\bar{w}} \prod_{i=1}^n p(y_i|x_i;\bar{w}) \tag{2-3} wˉ∗=argwˉmaxi=1∏np(yi∣xi;wˉ)(2-3)
For the sake of calculation , Usually take logarithm , namely
w ˉ ∗ = a r g max w ˉ ∑ i = 1 n l o g ( p ( y i ∣ x i ; w ˉ ) ) (2-4) \bar{w}^* = arg \max_{\bar{w}} \sum_{i=1}^n log(p(y_i|x_i;\bar{w})) \tag{2-4} wˉ∗=argwˉmaxi=1∑nlog(p(yi∣xi;wˉ))(2-4)
Usually in order not to let the model learn biased , hold w ˉ \bar{w} wˉ Learn to fool the past , Plus a regular term
w ˉ ∗ = a r g max w ˉ ∑ i = 1 n l o g ( p ( y i ∣ x i ; w ˉ ) ) − λ 2 ∣ ∣ w ˉ ∣ ∣ 2 (2-5) \bar{w}^* = arg \max_{\bar{w}} \sum_{i=1}^n log(p(y_i|x_i;\bar{w})) - \frac{\lambda}{2}||\bar{w}||^2\tag{2-5} wˉ∗=argwˉmaxi=1∑nlog(p(yi∣xi;wˉ))−2λ∣∣wˉ∣∣2(2-5)
This is the loss function , With the loss function, we can use the gradient descent method to find the parameters w ˉ ∗ \bar{w}^* wˉ∗ 了 .
This is only for non sequential datasets .
3 MEMM
3.1 Model overview
MEMM(maximum-entropy Markov model) Further change the question from p ( y ∣ x ) p(y|x) p(y∣x) Turn into p ( y ˉ ∣ x ˉ ) p(\bar{y}|\bar{x}) p(yˉ∣xˉ), Or you could write it as
p ( y 1 , y 2 , . . . , y m ∣ x 1 , x 2 , . . . , x m ) (3-1) p(y^1, y^2, ..., y^m|x^1, x^2, ..., x^m) \tag{3-1} p(y1,y2,...,ym∣x1,x2,...,xm)(3-1)
among , x j x^j xj Represents the... In the sequence j j j individual token, For example, the first in a sentence j j j Word ; y j y^j yj Represents the... In the sequence j j j A label , For example, the first in a sentence j j j Part of speech of words ; m m m Represents the length of the sequence .
use Y Y Y Represents all possible tag sets , This is a finite set , y j ∈ Y y^j \in Y yj∈Y.
Will type ( 3 − 1 ) (3-1) (3−1) If we use conditional probability to transform, we have
p ( y 1 , y 2 , . . . , y m ∣ x 1 , x 2 , . . . , x m ) = ∏ j = 1 m p ( y j ∣ y 1 , . . . , y j − 1 , x 1 , . . . , x m ) (3-2) p(y^1, y^2, ..., y^m|x^1, x^2, ..., x^m) = \prod_{j=1}^m p(y^j|y^1, ..., y^{j-1}, x^1, ..., x^m) \tag{3-2} p(y1,y2,...,ym∣x1,x2,...,xm)=j=1∏mp(yj∣y1,...,yj−1,x1,...,xm)(3-2)
type ( 3 − 2 ) (3-2) (3−2) Just a bunch of conditional probabilities , This is inevitable , There are no assumptions . If we put HMM Let's put the homogeneous Markov hypothesis in , Think y j y^j yj Receive only y j − 1 y^{j-1} yj−1 Influence , Then there is
p ( y 1 , y 2 , . . . , y m ∣ x 1 , x 2 , . . . , x m ) = ∏ j = 1 m p ( y j ∣ y j − 1 , x 1 , . . . , x m ) (3-3) p(y^1, y^2, ..., y^m|x^1, x^2, ..., x^m) = \prod_{j=1}^m p(y^j|y^{j-1}, x^1, ..., x^m) \tag{3-3} p(y1,y2,...,ym∣x1,x2,...,xm)=j=1∏mp(yj∣yj−1,x1,...,xm)(3-3)
It is still believed here that y j y^j yj By all x j x^j xj Influence , This is To break the HMM The observational independence assumption in . This is an unreasonable assumption in many tasks , therefore MEMM for HMM Improvements have been made. . Draw a probability diagram

There are a lot of CRF All of my articles start with probability graphs , But there is no need at all , No, I got the picture first 3-1 Only then has the formula ( 3 − 3 ) (3-3) (3−3), But first there is the formula ( 3 − 3 ) (3-3) (3−3) Only then had the picture 3-1, chart 3-1 Just let it go ( 3 − 1 ) (3-1) (3−1) It seems more convenient . I don't know the probability diagram , It doesn't matter at all .
But since we have drawn the probability diagram , Let me just say ,MEMM The probability diagram and HMM The difference between the probability graphs of x x x The direction of the arrow is reversed , From generative model to discriminant model ; as well as MEMM It's all x x x Point to each y j y^j yj, and HMM yes x j x^j xj Point to y j y^j yj, Breaking the observation independence Hypothesis .
good , Return to the form ( 3 − 3 ) (3-3) (3−3), utilize log-linear model Modeling , There is
p ( y j ∣ y j − 1 , x 1 , . . . , x m ) = e x p ( w ˉ ⋅ ϕ ˉ ( x 1 , . . . , x m , j , y j − 1 , y j ) ) ∑ y ′ ∈ Y e x p ( w ˉ ⋅ ϕ ˉ ( x 1 , . . . , x m , j , y j − 1 , y ′ ) ) (3-4) p(y^j|y^{j-1}, x_1, ..., x_m) = \frac{exp(\bar{w} \cdot \bar{\phi}(x^1,...,x^m, j, y^{j-1}, y^{j}))}{\sum_{y' \in Y} exp(\bar{w} \cdot \bar{\phi}(x^1,...,x^m, j, y^{j-1}, y'))} \tag{3-4} p(yj∣yj−1,x1,...,xm)=∑y′∈Yexp(wˉ⋅ϕˉ(x1,...,xm,j,yj−1,y′))exp(wˉ⋅ϕˉ(x1,...,xm,j,yj−1,yj))(3-4)
Pay attention to the comparison ( 3 − 4 ) (3-4) (3−4) Sum formula ( 2 − 1 ) (2-1) (2−1) The difference between , Is that the condition in the conditional probability changes .
Will type ( 3 − 4 ) (3-4) (3−4) Substituting ( 3 − 3 ) (3-3) (3−3) There is
p ( y 1 , y 2 , . . . , y m ∣ x 1 , x 2 , . . . , x m ) = ∏ j = 1 m e x p ( w ˉ ⋅ ϕ ˉ ( x 1 , . . . , x m , j , y j − 1 , y j ) ) ∑ y ′ ∈ Y e x p ( w ˉ ⋅ ϕ ˉ ( x 1 , . . . , x m , j , y j − 1 , y ′ ) ) (3-5) p(y^1, y^2, ..., y^m|x^1, x^2, ..., x^m) =\\ \prod_{j=1}^m \frac{exp(\bar{w} \cdot \bar{\phi}(x^1,...,x^m, j, y^{j-1}, y^{j}))}{\sum_{y' \in Y} exp(\bar{w} \cdot \bar{\phi}(x^1,...,x^m, j, y^{j-1}, y'))} \tag{3-5} p(y1,y2,...,ym∣x1,x2,...,xm)=j=1∏m∑y′∈Yexp(wˉ⋅ϕˉ(x1,...,xm,j,yj−1,y′))exp(wˉ⋅ϕˉ(x1,...,xm,j,yj−1,yj))(3-5)
Here, when training the model , Not a hold ( 3 − 5 ) (3-5) (3−5) This big guy went to training , It's training p ( y j ∣ y j − 1 , x 1 , . . . , x m ) p(y^j|y^{j-1}, x_1, ..., x_m) p(yj∣yj−1,x1,...,xm) This model .
With p ( y j ∣ y j − 1 , x 1 , . . . , x m ) p(y^j|y^{j-1}, x_1, ..., x_m) p(yj∣yj−1,x1,...,xm) after , Any x x x and y j − 1 y^{j-1} yj−1, y j y^j yj You can output a probability value when you enter , The question becomes how decoding, How to reason , The o
a r g max y 1 , . . , y m p ( y 1 , . . , y m ∣ x 1 , . . . , x m ) (3-6) arg\max_{y^1, .., y^m} p(y_1, .., y^m | x^1, ..., x^m) \tag{3-6} argy1,..,ymmaxp(y1,..,ym∣x1,...,xm)(3-6)
If we assume that Y Y Y There are k k k One element , that y 1 , . . . , y m y^1, ..., y^m y1,...,ym There is k m k^m km Combinations of , This calculation is too much . This is the time , Dynamic programming is needed , Dynamic programming here has its own name , be called viterbi Algorithm , It's actually dynamic programming .
We will build a matrix π [ j , y ] \pi [j, y] π[j,y], j = 1 , . . . , m j=1,...,m j=1,...,m also y ∈ Y y \in Y y∈Y. π [ j , y ] \pi [j, y] π[j,y] Stored in j j j A place , The state is y y y The maximum probability value and the sequence of the probability value y 1 , . . , y j y^1, .., y^j y1,..,yj. It can be expressed as
π [ j , y ] = max y 1 , . . . , y j − 1 ( p ( y ∣ y j − 1 , x 1 , . . . , x m ) ∏ k = 1 j − 1 p ( y k ∣ y k − 1 , x 1 , . . . , x m ) ) (3-7) \pi[j, y] = \max_{y^1, ..., y^{j-1}}(p(y|y^{j-1}, x^1, ..., x^m) \prod_{k=1}^{j-1}p(y^k|y^{k-1}, x^1, ..., x^m)) \tag{3-7} π[j,y]=y1,...,yj−1max(p(y∣yj−1,x1,...,xm)k=1∏j−1p(yk∣yk−1,x1,...,xm))(3-7)
among , The first is the initial variable , amount to HMM The initial probability in
π [ 1 , y ] = p ( y ∣ y 0 , x 1 , . . . , x m ) (3-8) \pi[1, y] = p(y | y^0, x^1, ..., x^m) \tag{3-8} π[1,y]=p(y∣y0,x1,...,xm)(3-8)
y 0 y^0 y0 Namely "<START>" Such a beginning token.
Then we get it through iteration
π [ j , y ] = max y ′ ∈ Y ( π [ j − 1 , y ′ ] ⋅ p ( y ∣ y ′ , x 1 , . . . , x m ) ) (3-9) \pi[j, y] = \max_{y' \in Y}(\pi[j-1, y'] \cdot p(y|y', x^1, ..., x^m)) \tag{3-9} π[j,y]=y′∈Ymax(π[j−1,y′]⋅p(y∣y′,x1,...,xm))(3-9)
take π [ j , y ] \pi[j, y] π[j,y] When this matrix is filled , There is
max y 1 , . . . , y m p ( y 1 , . . . , y m ∣ x 1 , . . . , x m ) = max y π [ m , y ] (3-10) \max_{y^1, ..., y^m}p(y^1, ..., y^m | x^1, ..., x^m) = \max_{y} \pi[m, y] \tag{3-10} y1,...,ymmaxp(y1,...,ym∣x1,...,xm)=ymaxπ[m,y](3-10)
MEMM Compared with HMM The advantage is that
- The observed variables are no longer independent
- You can design it yourself ϕ ˉ \bar{\phi} ϕˉ, More controllable to the result
3.2 label bias problem
MEMM There are also problems of its own , This question is called label bias problem , It's called Siyi , This is caused by the imbalance of training data labels , If the training data is large enough , The label is sufficiently balanced , There is no such problem . The root cause of this problem is p ( y j ∣ y j − 1 , x 1 , . . . , x m ) p(y^j|y^{j-1}, x^1, ..., x^m) p(yj∣yj−1,x1,...,xm) It is normalized at each time node , Lost some information .
Here is an example to illustrate , As long as there is an intuitive understanding , Don't worry too much about the rationality of the example .
Suppose we get the following figure through training 3-2 Such a probability value reasoning diagram , We type in [“the”, “cat”, “sat”], You can find [“ARTICLE”, “NOUN”, “VERB”] This is the highest probability , Yes 1.0 ∗ 0.9 ∗ 1.0 = 0.9 1.0*0.9*1.0=0.9 1.0∗0.9∗1.0=0.9.
however , When our input is [“cat”, “sat”] When , You will find [“NOUN”, “VERB”] The probability is 0.1 ∗ 1.0 = 0.1 0.1*1.0=0.1 0.1∗1.0=0.1, and [“ARTICLE”, “NOUN”] The probability of 0.9 ∗ 0.3 = 0.27 0.9*0.3=0.27 0.9∗0.3=0.27. This is because "cat" A sentence that begins with , Models are rarely seen . If you can bring the information that the model sees little in the calculation , We can avoid this problem .
Let's take a look at the following figure 3-2 The corresponding logic diagram , Here's the picture 3-3 Shown , There is no normalized graph .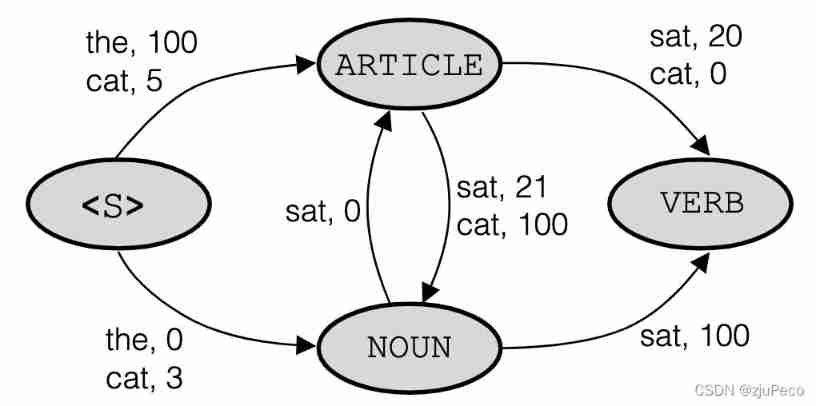
Normalization is e x e^x ex Such exponential normalization , You can start to calculate , Yes and FIG 3-2 The probability value of corresponds to . here [“cat”, “sat”] In this case [“NOUN”, “VERB”] Namely 3 + 100 = 103 3+100=103 3+100=103, and [“ARTICLE”, “NOUN”] It becomes 5 + 21 = 26 5+21=26 5+21=26. I use addition because there are log value .
That's all there is to say , Just to give an intuitive understanding , Want to study carefully , May have a look The Label Bias Problem, Or search for what other big guys say .
4 CRF
4.1 Model overview
With so many mattresses in front ,CRF(conditional random filed) It's easy to understand .MEMM It is the right form ( 3 − 4 ) (3-4) (3−4) Modeling , and CRF It is the right form ( 4 − 1 ) (4-1) (4−1) Modeling
p ( y 1 , . . . , y m ∣ x 1 , . . . , x m ) = p ( y ˉ ∣ x ˉ ) (4-1) p(y^1, ..., y^m|x^1, ..., x^m) = p(\bar{y}|\bar{x}) \tag{4-1} p(y1,...,ym∣x1,...,xm)=p(yˉ∣xˉ)(4-1)
Attention style ( 2 − 1 ) (2-1) (2−1), type ( 3 − 4 ) (3-4) (3−4) Sum formula ( 4 − 1 ) (4-1) (4−1) The difference between .CRF There is no local normalization , Only global normalization , To put it bluntly, it is a sequence log-linear Model .
p ( y ˉ ∣ x ˉ ; w ˉ ) = e x p ( w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ) ) ∑ y ˉ ′ ∈ Y m e x p ( w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ′ ) ) (4-2) p(\bar{y}|\bar{x};\bar{w}) = \frac{exp(\bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}))}{\sum_{\bar{y}' \in Y^m} exp(\bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}'))} \tag{4-2} p(yˉ∣xˉ;wˉ)=∑yˉ′∈Ymexp(wˉ⋅Φˉ(xˉ,yˉ′))exp(wˉ⋅Φˉ(xˉ,yˉ))(4-2)
among , Y m Y^m Ym To express with Y Y Y The element composition length in is m m m All possible sets of sequences of .
There are also ϕ ˉ \bar{\phi} ϕˉ Turned into Φ ˉ \bar{\Phi} Φˉ, Φ ˉ \bar{\Phi} Φˉ For the definition of
Φ ˉ ( x ˉ , y ˉ ) = ∑ j = 1 m ϕ ˉ ( x ˉ , j , y j − 1 , y j ) (4-3) \bar{\Phi}(\bar{x}, \bar{y}) = \sum_{j=1}^{m} \bar{\phi}(\bar{x}, j, y^{j-1}, y^{j}) \tag{4-3} Φˉ(xˉ,yˉ)=j=1∑mϕˉ(xˉ,j,yj−1,yj)(4-3)
there ϕ ˉ ( x ˉ , j , y j − 1 , y j ) \bar{\phi}(\bar{x}, j, y_{j-1}, y^{j}) ϕˉ(xˉ,j,yj−1,yj) and MEMM The one in is exactly the same , Are artificially defined characteristic functions . It just adds up the whole sequence .
CRF The probability graph model of is shown in the following figure 4-1 Shown , It's like a graph 3-1 Is the difference between the , y j y^j yj Becomes an undirected graph . Or that sentence , It's OK not to look at this picture .
4.2 model training
CRF Model training and log-linear The method of the model is basically the same . In short , We have n n n Training samples { ( x ˉ i , y ˉ i ) } i = 1 n \{(\bar{x}_i, \bar{y}_i)\}_{i=1}^n { (xˉi,yˉi)}i=1n, Every x ˉ i \bar{x}_i xˉi They're all sequences x i 1 , . . . , x i m x_i^{1}, ..., x_i^{m} xi1,...,xim, Every y ˉ i \bar{y}_i yˉi They are all sequences y i 1 , . . . , y i m y_i^{1}, ..., y_i^{m} yi1,...,yim.
Its objective function is
w ˉ ∗ = a r g max w ˉ ∑ i = 1 n l o g ( p ( y ˉ i ∣ x ˉ i ; w ˉ ) ) − λ 2 ∣ ∣ w ˉ ∣ ∣ 2 (4-4) \bar{w}^* = arg \max_{\bar{w}} \sum_{i=1}^n log(p(\bar{y}_i|\bar{x}_i;\bar{w})) - \frac{\lambda}{2}||\bar{w}||^2 \tag{4-4} wˉ∗=argwˉmaxi=1∑nlog(p(yˉi∣xˉi;wˉ))−2λ∣∣wˉ∣∣2(4-4)
The next task is the gradient descent .
4.3 Model decoding
CRF Conduct decoding The goal is
a r g max y ˉ ∈ Y m p ( y ˉ ∣ x ˉ ; w ˉ ) = a r g max y ˉ ∈ Y m e x p ( w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ) ) ∑ y ′ ∈ Y e x p ( w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ′ ) ) = a r g max y ˉ ∈ Y m e x p ( w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ) ) = a r g max y ˉ ∈ Y m w ˉ ⋅ Φ ˉ ( x ˉ , y ˉ ) = a r g max y ˉ ∈ Y m ∑ j = 1 m w ˉ ⋅ ϕ ˉ ( x ˉ , j , y j − 1 , y j ) (4-5) \begin{aligned} arg\max_{\bar{y} \in Y^m} p(\bar{y}|\bar{x};\bar{w}) &= arg\max_{\bar{y} \in Y^m} \frac{exp(\bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}))}{\sum_{y' \in Y} exp(\bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}'))} \\ &= arg\max_{\bar{y} \in Y^m} exp(\bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}))\\ &= arg\max_{\bar{y} \in Y^m} \bar{w} \cdot \bar{\Phi}(\bar{x}, \bar{y}) \\ &= arg\max_{\bar{y} \in Y^m} \sum_{j=1}^{m} \bar{w} \cdot \bar{\phi}(\bar{x}, j, y^{j-1}, y^{j}) \end{aligned} \tag{4-5} argyˉ∈Ymmaxp(yˉ∣xˉ;wˉ)=argyˉ∈Ymmax∑y′∈Yexp(wˉ⋅Φˉ(xˉ,yˉ′))exp(wˉ⋅Φˉ(xˉ,yˉ))=argyˉ∈Ymmaxexp(wˉ⋅Φˉ(xˉ,yˉ))=argyˉ∈Ymmaxwˉ⋅Φˉ(xˉ,yˉ)=argyˉ∈Ymmaxj=1∑mwˉ⋅ϕˉ(xˉ,j,yj−1,yj)(4-5)
ϕ ˉ ( x ˉ , j , y j − 1 , y j ) \bar{\phi}(\bar{x}, j, y^{j-1}, y^{j}) ϕˉ(xˉ,j,yj−1,yj) Part of it is with y j − 1 y^{j-1} yj−1 Relevant , It's called the transfer feature ; The other part is with y j − 1 y^{j-1} yj−1 Irrelevant , It's called state characteristics . It's all mixed up here , You don't have to care .
The decoding method is dynamic programming , Also define a π [ j , s ] \pi[j, s] π[j,s].
The initial probability is
π [ 1 , y ] = w ˉ ⋅ ϕ ˉ ( x ˉ , 1 , y 0 , y ) (4-6) \pi[1, y] = \bar{w} \cdot \bar{\phi}(\bar{x}, 1, y^{0}, y) \tag{4-6} π[1,y]=wˉ⋅ϕˉ(xˉ,1,y0,y)(4-6)
The iterative formula of probability is
π [ j , y ] = max y ′ ∈ Y ( π [ j − 1 , y ′ ] + w ˉ ⋅ ϕ ˉ ( x ˉ , j , y ′ , y ) ) (4-6) \pi[j, y] = \max_{y' \in Y} (\pi [j-1, y'] + \bar{w} \cdot \bar{\phi}(\bar{x}, j, y', y)) \tag{4-6} π[j,y]=y′∈Ymax(π[j−1,y′]+wˉ⋅ϕˉ(xˉ,j,y′,y))(4-6)
Find all the π [ j , y ] \pi[j, y] π[j,y] after , You can get the path with the greatest probability
max y 1 , . . . , y m ∑ j = 1 m w ˉ ⋅ ϕ ( x ˉ , j , y j − 1 , y j ) = max y π [ m , s ] (4-7) \max_{y^1, ..., y^m} \sum_{j=1}^{m} \bar{w} \cdot \phi (\bar{x}, j, y^{j-1}, y^j) = \max_{y} \pi[m, s] \tag{4-7} y1,...,ymmaxj=1∑mwˉ⋅ϕ(xˉ,j,yj−1,yj)=ymaxπ[m,s](4-7)
4.4 Summary
CRF It's solved HMM The irrationality of observation independence , Also solved MEMM in label bias The problem of , And the characteristic function can be added manually to interfere with the output of the model , There are some impossible situations , You can manually set the transition probability to be very small .
Usually the CRF Add to Bi-LSTM after , Make the output of the sequence model more controllable . If there is enough data , If it is balanced ,CRF It can also be omitted .
Reference material
[1] Log-Linear Models, MEMMs, and CRFs
[2] https://anxiang1836.github.io/2019/11/05/NLP_From_HMM_to_CRF/
[3] https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
[4] https://www.bilibili.com/video/BV19t411R7QU?p=4&share_source=copy_web
[5] The Label Bias Problem
边栏推荐
- [pytorch]fixmatch code explanation - data loading
- Introduction to arm Cortex-M learning
- 华为设备配置IP和虚拟专用网混合FRR
- Think: when do I need to disable mmu/i-cache/d-cache?
- Sensor: sht30 temperature and humidity sensor testing ambient temperature and humidity experiment (code attached at the bottom)
- 华为设备配置虚拟专用网FRR
- Test questions basic exercise 01 string
- js获取元素
- Solution of depth learning for 3D anisotropic images
- 16 embedded C language interview questions (Classic)
猜你喜欢

Paper reading - group normalization
![[pytorch]fixmatch code explanation - data loading](/img/0f/1165dbe4c7410a72d74123ec52dc28.jpg)
[pytorch]fixmatch code explanation - data loading

Armv8-m learning notes - getting started

Yovo3 and yovo3 tiny structure diagram

Mac使用Docker安装Oracle

Sqlserver2008 denied select permission on object'***** '(database'*****', schema'dbo')

ROS learning -5 how function packs with the same name work (workspace coverage)

华为设备配置IP和虚拟专用网混合FRR

Chapter7-10_ Deep Learning for Question Answering (1/2)

C language compressed string is saved to binary file, and the compressed string is read from binary file and decompressed.
随机推荐
Mbedtls migration experience
[sequence structure, branch structure, loop structure, continue statement, break statement, return statement] (learning Note 6 -- C language process control)
Sensor: MQ-5 gas module measures the gas value (code attached at the bottom)
Review the history of various versions of ITIL, and find the key points for the development of enterprise operation and maintenance
[keras learning]fit_ Generator analysis and complete examples
柏瑞凯电子冲刺科创板:拟募资3.6亿 汪斌华夫妇为大股东
[the third day of actual combat of smart lock project based on stm32f401ret6 in 10 days] communication foundation and understanding serial port
[the second day of actual combat of smart lock project based on stm32f401ret6 in 10 days] (lighting with library function and register respectively)
ROS learning-6 detailed explanation of publisher programming syntax
Number of special palindromes in basic exercise of test questions
Differences between constants and variables (detailed description) (learning note 3 -- variables and constants)
Can't use typedef yet? C language typedef detailed usage summary, a solution to your confusion. (learning note 2 -- typedef setting alias)
When AI meets music, iFLYTEK music leads the industry reform with technology
Paper reading - jukebox: a generic model for music
js-dom
Yovo3 and yovo3 tiny structure diagram
华为设备配置私网IP路由FRR
json,xml,txt
SQL server deletes all tables and all stored procedures in the database
华为设备配置虚拟专用网FRR