当前位置:网站首页>Make your own dataset in FCN and train it
Make your own dataset in FCN and train it
2022-07-31 10:17:00 【Keep_Trying_Go】
目录
2.FCN项目实战(使用PASCAL VOC 2012数据集)
3.Collection of image datasets
5. The location of the dataset file
1.FCN论文详解
https://mydreamambitious.blog.csdn.net/article/details/125966298
2.FCN项目实战(使用PASCAL VOC 2012数据集)
https://mydreamambitious.blog.csdn.net/article/details/125774545
注:
深度学习领域语义分割常用数据集:深度学习领域语义分割常用数据集:PASCAL VOC 2007 ,2012 NYUDv2 SUNRGBD CityScapes CamVid SIFT-Flow 7Introduction to large datasets_Keep_Trying_Go的博客-CSDN博客
3.Collection of image datasets
Here is a training data set made by myself through the downloaded pictures,只有39张图片,Readers can use this dataset for training first,There is no problem and then follow this to make your own data set(The collection of datasets themselves can also be collected from life,It doesn't have to be downloaded from the Internet either,This might make more sense).
链接:https://pan.baidu.com/s/1hUZYmy0iQ5dG4dbDD69ZwA
提取码:25d6
4.工具的选择
(1)工具一
labelmeis a polygon annotation tool,Outlines can be accurately marked,常用于分割.
labelme:I have not used this tool,In fact, this method of use and the following will be introducedlabelImg使用方式一样.
安装:pip install labelme
打开:Enter directly in the downloaded environment:labelme参考链接:https://blog.csdn.net/weixin_44245653/article/details/119150966
(2)工具二
labelimg,Is a rectangle annotation tool,Commonly used for object recognition and object detection,可直接生成yolo读取的txt标签格式,But it can only be used for rectangle frame annotation.Since this tool is mainly used for image recognition and object detection,So why can it be used to make a segmentation dataset,Mainly it can be made herePASCAL VOC数据集,But at the end the tag file is not generated,So this tool is mainly used to generate in our actual combat project.xml文件.
安装:pip install labelImg打开:Enter directly in the downloaded environment:labelImg首先打开工具:



It will be generated after clicking save.xml 文件:

That's it for the simple use of this tool,更多的可以参考B站视频学习.
(3)工具三
安装:
第一步:pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
第二步:pip install eiseg -i https://pypi.tuna.tsinghua.edu.cn/simple打开:eisegMaybe it will report this error after the installation is complete.
AttributeError: module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline'
解决方法:
pip install --user --upgrade opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
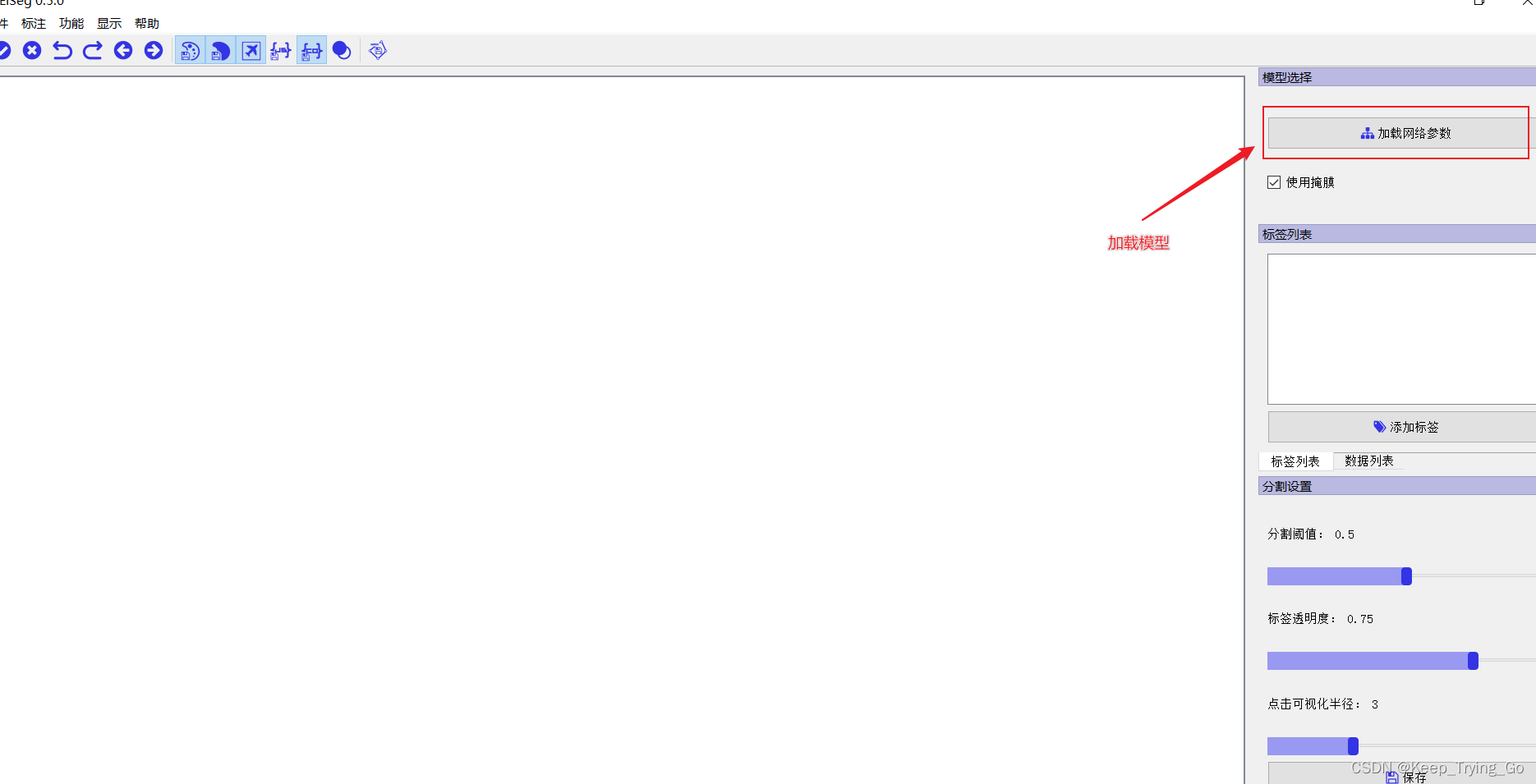
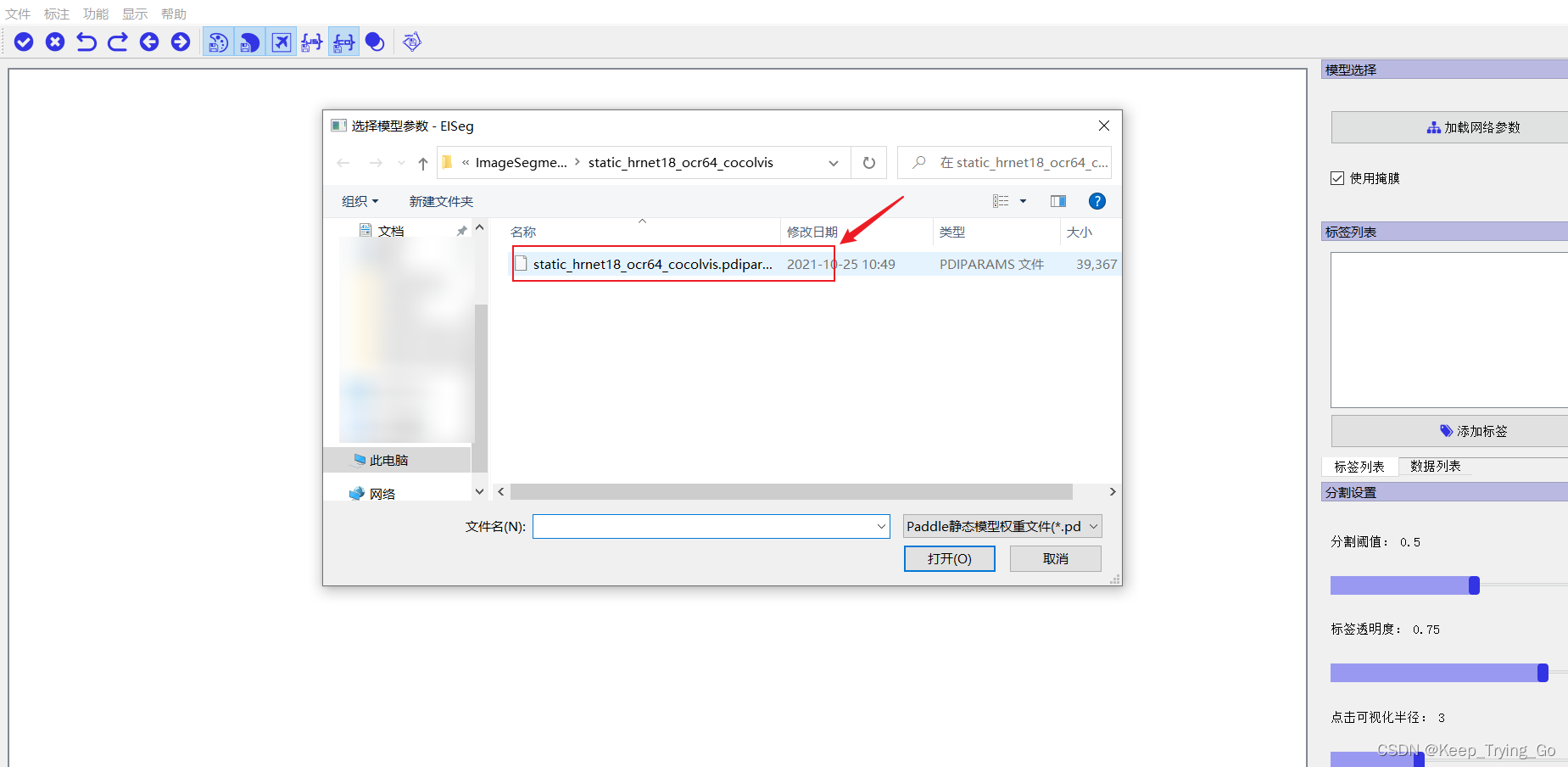
The first step starts by loading the model parameters:
| 模型类型 | 适用场景 | 模型结构 | 模型下载地址 |
| 高精度模型 | 通用场景的图像标注 | HRNet18_OCR64 | static_hrnet18_ocr64_cocolvis |
| 轻量化模型 | 通用场景的图像标注 | HRNet18s_OCR48 | static_hrnet18s_ocr48_cocolvis |
| 高精度模型 | Universal Image Annotation | EdgeFlow | static_edgeflow_cocolvis |
| 高精度模型 | Portrait scene annotation | HRNet18_OCR64 | static_hrnet18_ocr64_human |
| 轻量化模型 | Portrait scene annotation | HRNet18s_OCR48 | static_hrnet18s_ocr48_human |
注:The model loaded here is based on the data set it has labeled,For example, what scenario does it apply to.
 第二步打开文件:
第二步打开文件:
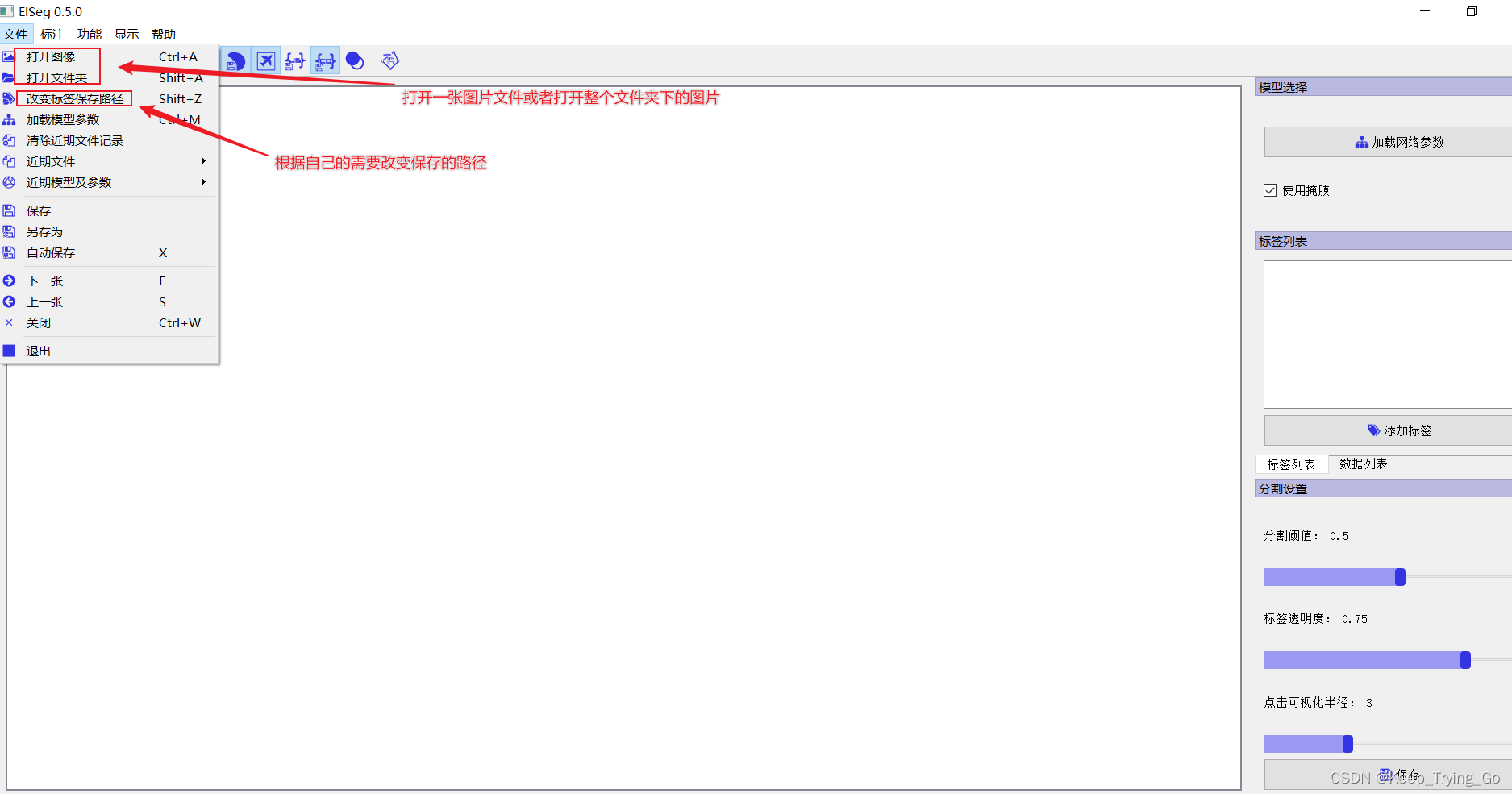

The third step is to add labels:
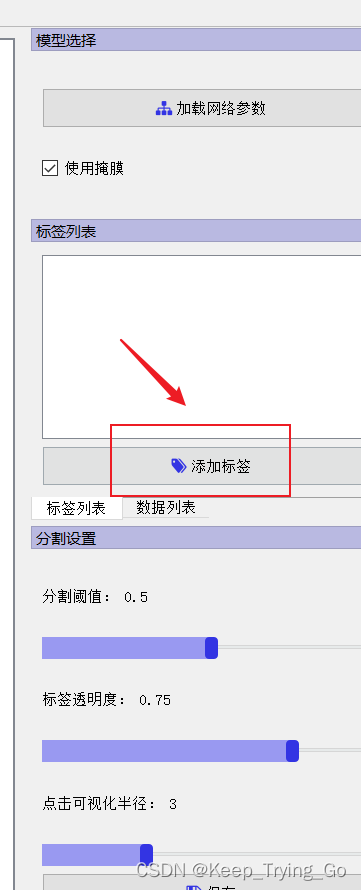
 The fourth step selects the data format to save:JSON或者COCO
The fourth step selects the data format to save:JSON或者COCO
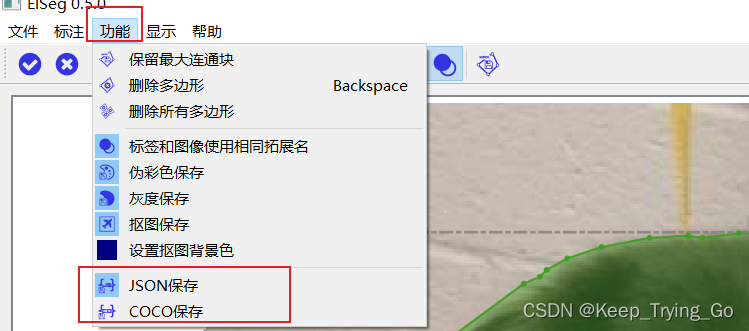 选择JSONOne for each image will be savedJSON文件,COCOThe data format will only be saved in oneJSON文件中.
选择JSONOne for each image will be savedJSON文件,COCOThe data format will only be saved in oneJSON文件中.
The fifth step is to click on the target to perform image annotation(Just click on the target in the image):

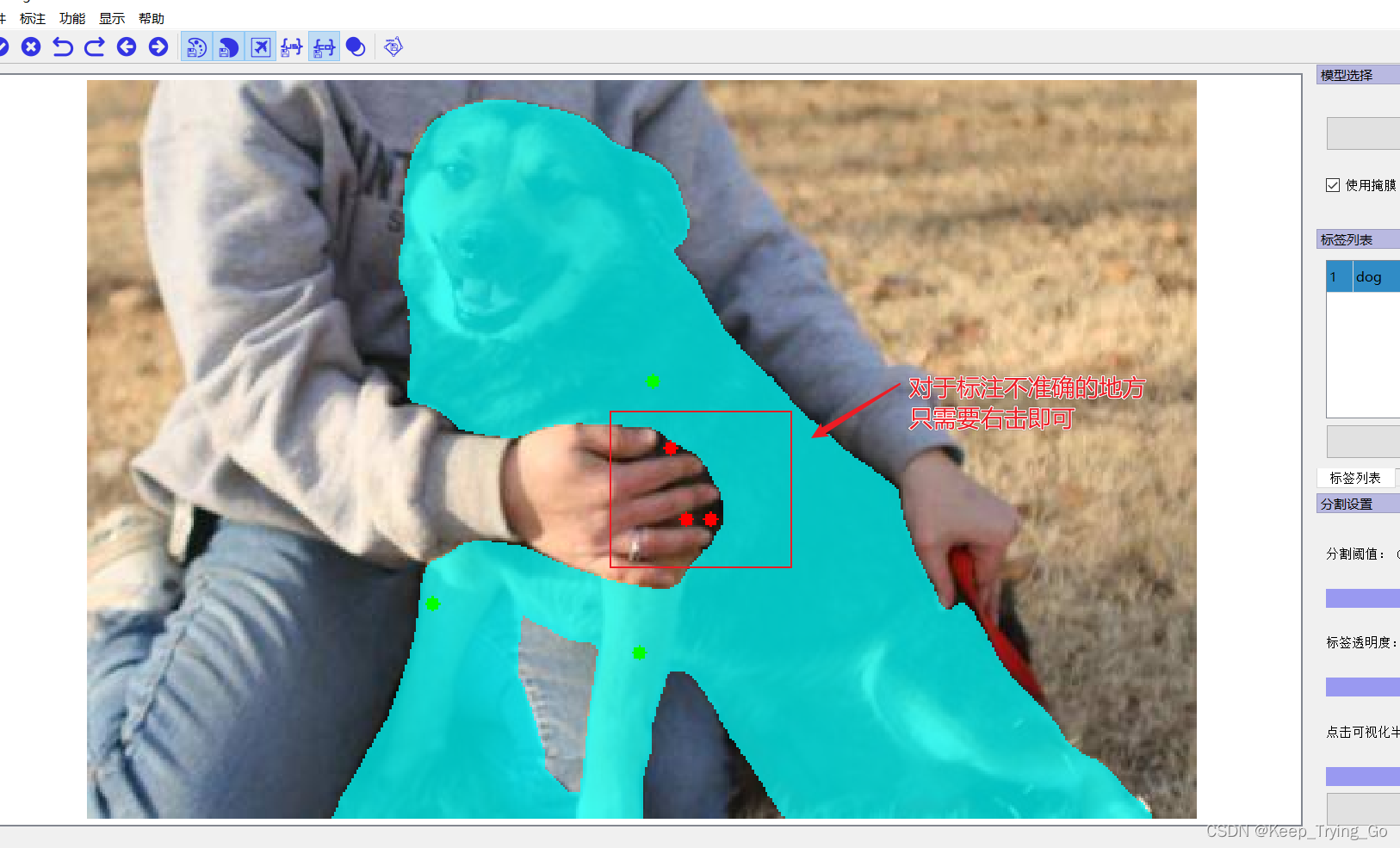
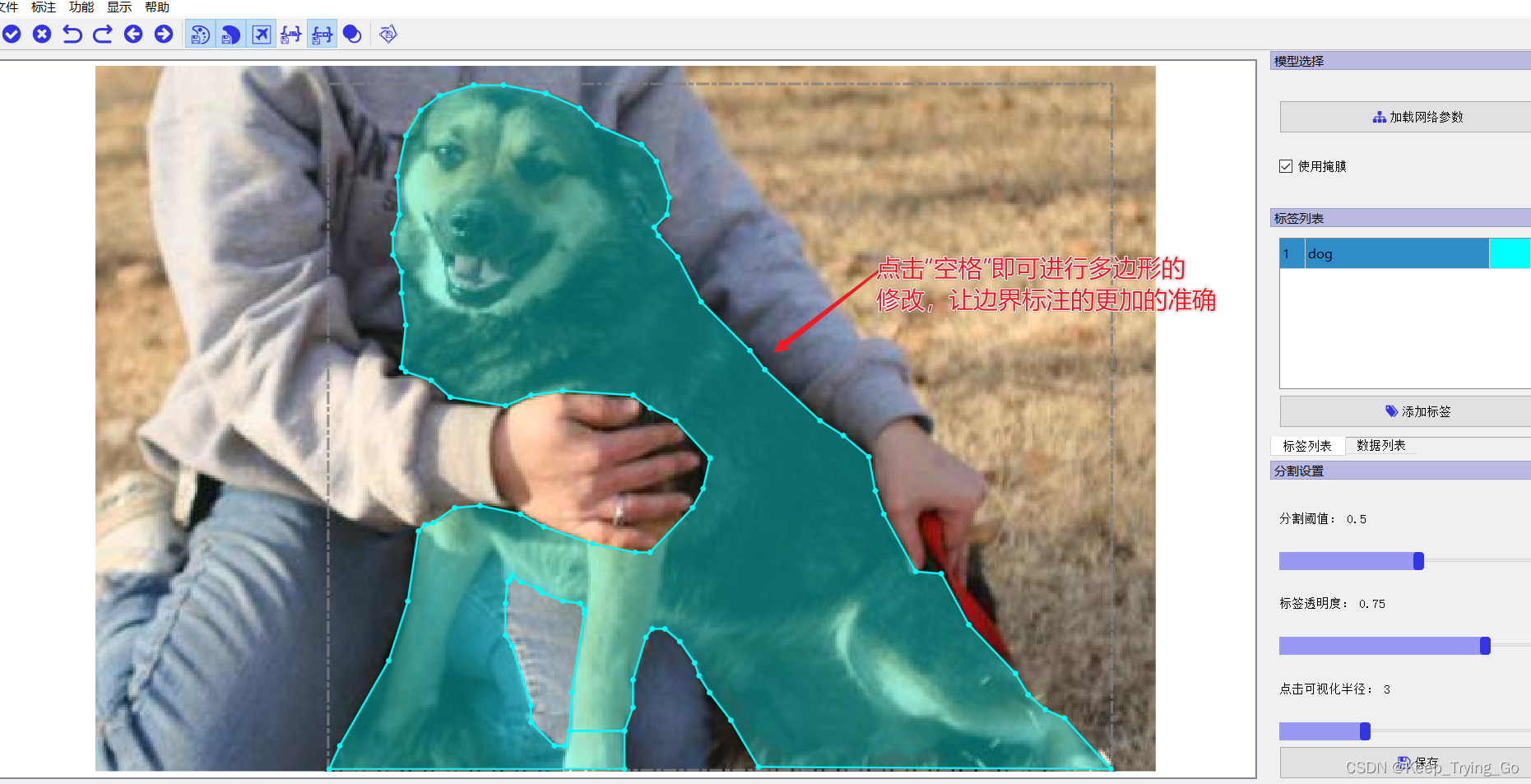


Although what we want is such a grayscale image,But it's not very good to look at it directly,So we'll add it to the palette:
import os
import cv2
import numpy as np
from PIL import Image
def palette():
#获取当前目录
root=os.getcwd()
#The location of the grayscale image
imgFile=root+'\\img'
#Add all grayscale images to the palette
for i,img in enumerate(os.listdir(imgFile)):
filename, _ = os.path.splitext(img)
#This place needs to add the image path completely,Otherwise, the image file to be read later does not exist
img='img/'+img
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
save_path=root+'\\imgPalette\\'+filename+'.png'
img = Image.fromarray(img) # 将图像从numpy的数据格式转为PIL中的图像格式
palette = []
for i in range(256):
palette.extend((i, i, i))
#这里设置21个颜色,The background is black,总共21个类别(包括背景)
palette[:3 * 21] = np.array([[0, 0,0],[0,255,255],[0, 128, 0],[128, 128, 0],[0, 0, 128],
[128, 0, 128],[0, 128, 128],[128, 128, 128],[64, 0, 0],[192, 0, 0],
[64, 128, 0],[192, 128, 0],[64, 0, 128],[192, 0, 128],[64, 128, 128],
[192, 128, 128],[0, 64, 0],[128, 64, 0],[0, 192, 0],[128, 192, 0],[0, 64, 128]
], dtype='uint8').flatten()
img.putpalette(palette)
# print(np.shape(palette)) 输出(768,)
img.save(save_path)
if __name__ == '__main__':
print('Pycharm')
palette()
代码参考:https://blog.csdn.net/weixin_39886251/article/details/111704330
The labeling of the dataset is completed at the same time as the tool is selected,The file location where the following dataset is stored can be performed.
5. The location of the dataset file
Anyway, the dataset is stored no matter how it is stored,It all depends on the operation of the program,Not that it has to be the same as mine,You can make changes to the program(If there is any error,不要害怕,Follow the error prompt to continue to modify).
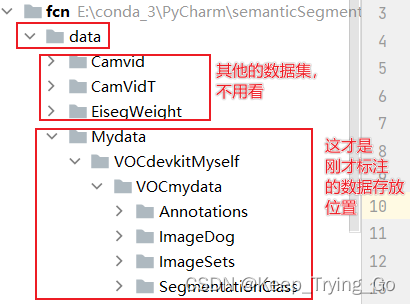
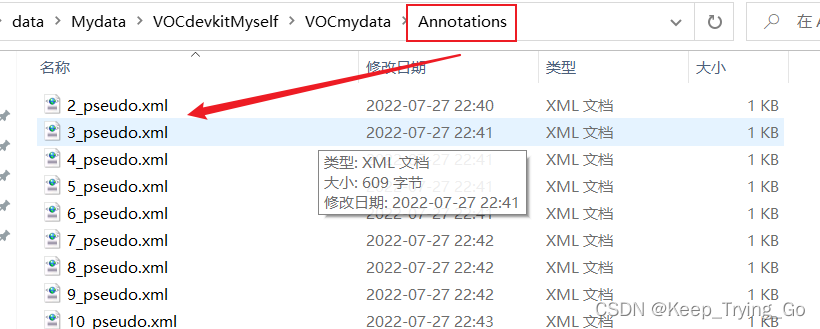


注:If you don't understand where the above files are placed,You can download that yourselfPASCAL VOC 2012数据集,Check for yourself how the file location of this dataset is placed(In fact, you can modify the program yourself,It doesn't have to be in this format).
深度学习领域语义分割常用数据集:深度学习领域语义分割常用数据集:PASCAL VOC 2007 ,2012 NYUDv2 SUNRGBD CityScapes CamVid SIFT-Flow 7Introduction to large datasets_Keep_Trying_Go的博客-CSDN博客

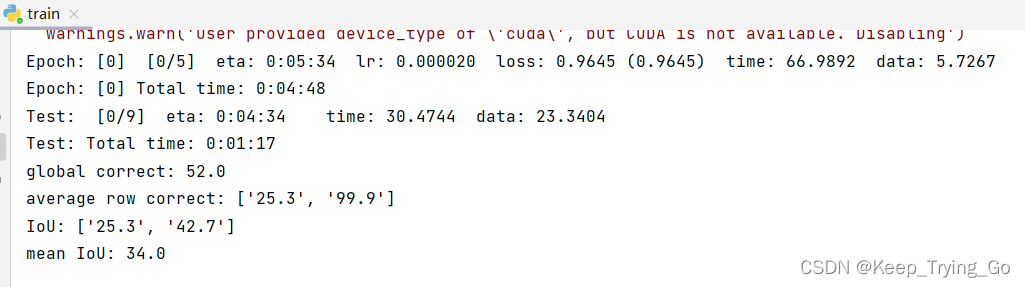
6.训练数据集
train.pySome places in the file need to be modified:数据集的位置,类别数.Others can be modified according to your needs.
#The location of the dataset file
parser.add_argument("--data-path", default="data/Mydata/", help="VOCdevkit root")
#数据集的类别数
parser.add_argument("--num-classes", default=1, type=int)
#Whether to use auxiliary branches
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")
#默认使用CPU设备
parser.add_argument("--device", default="cuda", help="training device")
#使用的batchsize大小
parser.add_argument("-b", "--batch-size", default=4, type=int)
#迭代的数量
parser.add_argument("--epochs", default=30, type=int, metavar="N",
help="number of total epochs to train")
#训练的学习率
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')
#Momentum of training
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
#weight delay
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
#训练多少个epoch打印一次
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
#When training breaks,Reload starts training from the last interrupted weight file
parser.add_argument('--resume', default='', help='resume from checkpoint')
#开始训练的epoch
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")

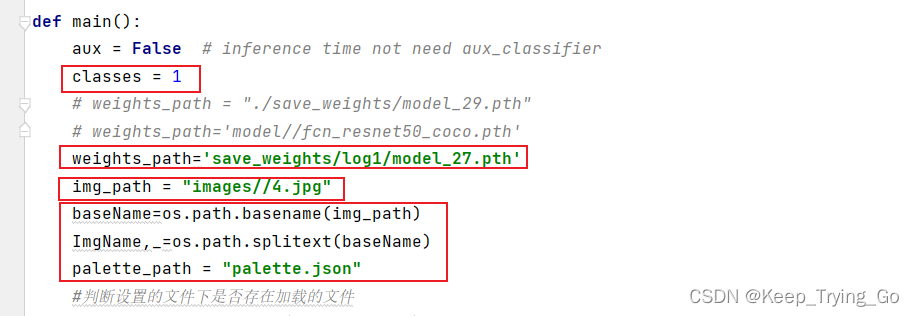
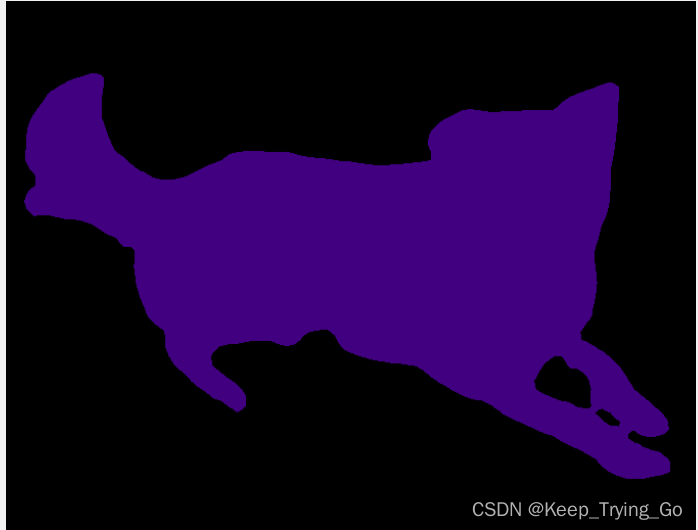
file to make predictionspredict.py:

边栏推荐
猜你喜欢





随机推荐
NowCoderTOP17-22 Binary search/sort - continuous update ing
Open Kylin openKylin automation developer platform officially released
GZIPInputStream 类源码分析
loadrunner-controller-目标场景Schedule配置
我们能做出来数据库吗?
模块八
浅谈Attention与Self-Attention,一起感受注意力之美
Web系统常见安全漏洞介绍及解决方案-XSS攻击
【23提前批】北森云计算-测开面经
湖仓一体电商项目(二):项目使用技术及版本和基础环境准备
SQL——左连接(Left join)、右连接(Right join)、内连接(Inner join)
前序、后序及层次遍历实现二叉树的序列化与反序列化
OpenGL es 导读篇
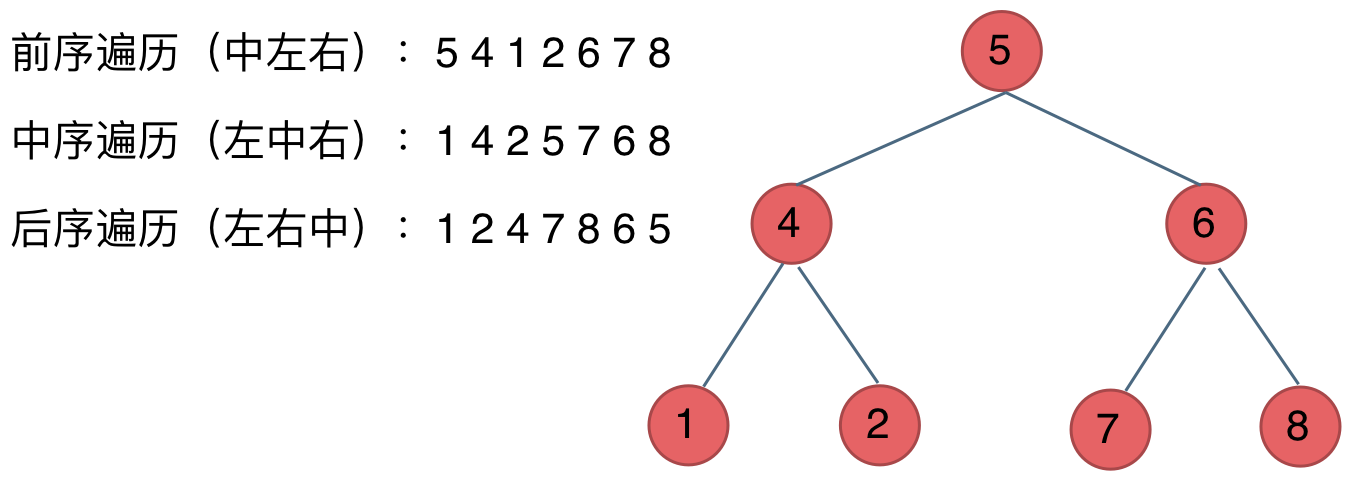
Come n times - 07. Rebuild the binary tree
Dart Log tool class
“chmod 777-R 文件名”什么意思?
nodeJs--querystring模块
金鱼哥RHCA回忆录:CL210管理OPENSTACK网络--开放虚拟网络(OVN)简介(课后练习)
loadrunner脚本--添加集合点
SQLSERVER将子查询数据合并拼接成一个字段