当前位置:网站首页>CUDA and Direct3D consistency
CUDA and Direct3D consistency
2022-07-02 06:27:00 【Little Heshang sweeping the floor】
CUDA And Direct3D Uniformity
Direct3D 9Ex、Direct3D 10 and Direct3D 11 Support Direct3D Interoperability .
CUDA Context can only be used with Direct3D Device interoperability : Direct3D 9Ex The device must be set to D3DDEVTYPE_HAL Of DeviceType And use D3DCREATE_HARDWARE_VERTEXPROCESSING logo BehaviorFlags establish ; Direct3D 10 and Direct3D 11 The device must be in DriverType Set to D3D_DRIVER_TYPE_HARDWARE Created in case of .
Can be mapped to CUDA Address space Direct3D Resources are Direct3D buffer 、 Texture and surface . These resources use cudaGraphicsD3D9RegisterResource()、cudaGraphicsD3D10RegisterResource() and cudaGraphicsD3D11RegisterResource() register .
The following code example uses the kernel to dynamically modify 2D width x height grid .
Direct3D 9 Version:
IDirect3D9* D3D;
IDirect3DDevice9* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
IDirect3DVertexBuffer9* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Initialize Direct3D
D3D = Direct3DCreate9Ex(D3D_SDK_VERSION);
// Get a CUDA-enabled adapter
unsigned int adapter = 0;
for (; adapter < g_pD3D->GetAdapterCount(); adapter++) {
D3DADAPTER_IDENTIFIER9 adapterId;
g_pD3D->GetAdapterIdentifier(adapter, 0, &adapterId);
if (cudaD3D9GetDevice(&dev, adapterId.DeviceName)
== cudaSuccess)
break;
}
// Create device
...
D3D->CreateDeviceEx(adapter, D3DDEVTYPE_HAL, hWnd,
D3DCREATE_HARDWARE_VERTEXPROCESSING,
¶ms, NULL, &device);
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
device->CreateVertexBuffer(size, 0, D3DFVF_CUSTOMVERTEX,
D3DPOOL_DEFAULT, &positionsVB, 0);
cudaGraphicsD3D9RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
Direct3D 10 Version
ID3D10Device* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D10Buffer* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Get a CUDA-enabled adapter
IDXGIFactory* factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void**)&factory);
IDXGIAdapter* adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D10GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// Create swap chain and device
...
D3D10CreateDeviceAndSwapChain(adapter,
D3D10_DRIVER_TYPE_HARDWARE, 0,
D3D10_CREATE_DEVICE_DEBUG,
D3D10_SDK_VERSION,
&swapChainDesc, &swapChain,
&device);
adapter->Release();
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D10_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D10_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D10_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D10RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
Direct3D 11 Version
ID3D11Device* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D11Buffer* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Get a CUDA-enabled adapter
IDXGIFactory* factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void**)&factory);
IDXGIAdapter* adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D11GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// Create swap chain and device
...
sFnPtr_D3D11CreateDeviceAndSwapChain(adapter,
D3D11_DRIVER_TYPE_HARDWARE,
0,
D3D11_CREATE_DEVICE_DEBUG,
featureLevels, 3,
D3D11_SDK_VERSION,
&swapChainDesc, &swapChain,
&device,
&featureLevel,
&deviceContext);
adapter->Release();
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D11_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D11_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D11RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
SLI Uniformity
In having more than one GPU In the system , All support CUDA Of GPU Both can pass CUDA The driver and runtime are accessed as separate devices . However , When the system is in SLI Mode time , There are special precautions as follows .
First , In a GPU On the one CUDA Allocation in the device will consume other GPU In the memory , these GPU yes Direct3D or OpenGL The equipment SLI Part of the configuration . therefore , The allocation may fail earlier than expected .
secondly , The application should create multiple CUDA Context , One for the SLI Each of the GPU. Although this is not a strict requirement , But it avoids unnecessary data transmission between devices . The application can cudaD3D[9|10|11]GetDevices() be used for Direct3D and cudaGLGetDevices() be used for OpenGL call , To identify the device currently performing rendering CUDA Device handle and next frame . In view of this information , Applications usually choose the right device and put Direct3D or OpenGL Resources are mapped to by cudaD3D[9|10|11]GetDevices() Or when deviceList Parameter set to cudaD3D[9|10 |11]DeviceListCurrentFrame or cudaGLDeviceListCurrentFrame.
Please note that , from cudaGraphicsD9D[9|10|11]RegisterResource and cudaGraphicsGLRegister[Buffer|Image] The returned resources can only be used on the device where the registration occurs . therefore , stay SLI Configuration in progress , When in different CUDA When calculating data of different frames on the device , It is necessary to register resources for each device separately .
of CUDA How to separate the runtime from Direct3D and OpenGL Details of interoperability , see also Direct3D Interoperability and OpenGL Interoperability .
边栏推荐
猜你喜欢

加密压缩文件解密技巧

sudo提权

It is said that Kwai will pay for the Tiktok super fast version of the video? How can you miss this opportunity to collect wool?

Cglib代理-代码增强测试
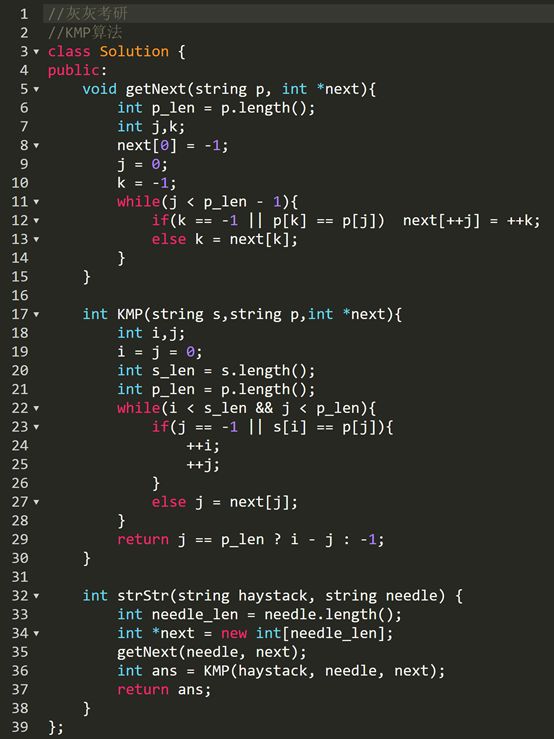
实现strStr() II

栈(线性结构)
Eco express micro engine system has supported one click deployment to cloud hosting

Distributed transactions: the final consistency scheme of reliable messages
Cglib agent - Code enhancement test

Monitoring uplink of VRRP
随机推荐
Sentinel rules persist to Nacos
LeetCode 90. Subset II
LeetCode 27. 移除元素
State machine in BGP
重载全局和成员new/delete
CUDA中内置的Vector类型和变量
Bgp Routing preference Rules and notice Principles
Redis——Cluster数据分布算法&哈希槽
Cglib代理-代码增强测试
压力测试修改解决方案
Learn about various joins in SQL and their differences
10 erreurs classiques de MySQL
Linear DP (split)
华为MindSpore开源实习机试题
NodeJs - Express 中间件修改 Header: TypeError [ERR_INVALID_CHAR]: Invalid character in header content
亚马逊aws数据湖工作之坑1
一口气说出 6 种实现延时消息的方案
LeetCode 39. 组合总和
Redis——大Key问题
Sentinel 阿里开源流量防护组件