当前位置:网站首页>Data science [viii]: SVD (I)
Data science [viii]: SVD (I)
2022-07-02 06:20:00 【swy_ swy_ swy】
Data Science 【 8、 ... and 】:SVD( One )
The purpose of this paper is to give SVD How to use . Specific principle or SVD Please refer to other resources for the code implementation of itself .
SVD It is mainly used in data feature extraction , Data compression, etc .
Data preparation
take mnist Deposit in csv
Use fetch_openml Common data sets can be obtained , Include mnist_784.
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
X, y = fetch_openml(name="mnist_784", version=1, return_X_y=True, as_frame=False)
import pandas as pd
import numpy as np
full_data = np.c_[y, X]
full_df = pd.DataFrame(full_data)
full_df.to_csv("mnist.csv", index=False)
Get eigenvalues
Get something “0” The eigenvalues of the
SVD You can call numpy Of linalg.svd.
import matplotlib.pyplot as plt
full_df = pd.read_csv("mnist.csv", low_memory = False)
full_data = full_df.values
plt.figure()
for n in range(100):
if full_data[n][0] == 0:
print(n)
data = full_data[n][1:].reshape(28, 28)
u, s, v = np.linalg.svd(data)
plt.plot(s)
break
plt.show()

data compression
We can compress or blur the data by retaining some eigenvalues .
Single image compression
Example : By setting some characteristic values to 0, take “0” Image compression for .
Matrix multiplication can be done by numpy.matmul Realization .
def image_svd(n, data):
u, s, v = np.linalg.svd(data)
svd = np.zeros((u.shape[0], v.shape[1]))
for i in range(n):
svd[i, i] = s[i]
img = np.matmul(u, svd)
img = np.matmul(img, v)
return img
plt.figure()
plt.subplot(1, 2, 1)
original_img = full_data[1][1:].reshape(28, 28)
plt.imshow(original_img, cmap="gray")
compress_img = image_svd(10, original_img)
plt.subplot(1, 2, 2)
plt.imshow(compress_img, cmap="gray")
plt.show()

Full data set compression
Example : The whole data set is compressed and stored in csv
X_data = full_data[:, range(1, 785)]
app_X = np.zeros(X_data.shape)
for i in range(X_data.shape[1]):
original = X_data[i].reshape(28, 28)
svd_img = image_svd(10, original)
app_X[i] = svd_img.reshape(1,784)
app_df = pd.DataFrame(app_X)
app_df.to_csv("app_mnist.csv", index=False)
Some phenomena
Clustering discreteness
First , We adopt and Last one Same method , Cluster the data set and draw the cluster center :
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
app_df = pd.read_csv("app_mnist.csv", low_memory=False)
kmeans_app = KMeans(n_clusters=10)
kmeans_app.fit(app_df.values)
app_centers = kmeans_app.cluster_centers_
centers_2d = PCA(2).fit_transform(app_centers)
plt.scatter(centers_2d[:, 0], centers_2d[:, 1])
plt.show()
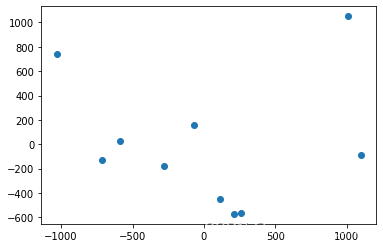
Let's do it again on the compressed data set :
org_df = pd.read_csv("mnist.csv", low_memory=False)
kmeans_org = KMeans(n_clusters=10)
kmeans_org.fit(org_df.values)
org_centers = kmeans_org.cluster_centers_
centers_2d = PCA(2).fit_transform(org_centers)
plt.scatter(centers_2d[:, 0], centers_2d[:, 1])
plt.show()

Clustering accuracy
Calculate the original data set and the compressed data set relative to ground truth Of disagreement distance:
def disagreement_dist(P_labels, C_labels):
answer = 0
for i in range(len(P_labels)-1):
for j in range(i+1, len(P_labels)):
if (P_labels[i] == P_labels[j]) != (C_labels[i]==C_labels[j]):
answer += 1
return answer
import numpy as np
org_plabels = kmeans_org.labels_
app_plabels = kmeans_app.labels_
clabels = pd.read_csv("mnist.csv", low_memory=False).values[:, [0]]
clabels.reshape(1, len(clabels))
clabels.astype(np.int8)
print("Difference on original dataset:")
print(disagreement_dist(org_plabels, clabels))
print("Difference on approximated dataset:")
print(disagreement_dist(app_plabels, clabels))
Difference on original dataset:
288675700
Difference on approximated dataset:
2161020505
边栏推荐
- Google Play Academy 组队 PK 赛,正式开赛!
- LeetCode 39. 组合总和
- Step by step | help you easily submit Google play data security form
- 官方零基础入门 Jetpack Compose 的中文课程来啦!
- 网络相关知识(硬件工程师)
- Replace Django database with MySQL (attributeerror: 'STR' object has no attribute 'decode')
- Contest3147 - game 38 of 2021 Freshmen's personal training match_ G: Flower bed
- 最新CUDA环境配置(Win10 + CUDA 11.6 + VS2019)
- Spark overview
- Community theory | kotlin flow's principle and design philosophy
猜你喜欢
State machine in BGP
Ruijie ebgp configuration case

栈(线性结构)

Lucene Basics

官方零基础入门 Jetpack Compose 的中文课程来啦!

Web components series (VIII) -- custom component style settings

Detailed steps of JS foreground parsing of complex JSON data "case: I"

Google Play Academy 组队 PK 赛,正式开赛!
In depth understanding of JUC concurrency (I) what is JUC

Summary of WLAN related knowledge points
随机推荐
In depth understanding of JUC concurrency (I) what is JUC
Use of Arduino wire Library
数据回放伴侣Rviz+plotjuggler
数据科学【八】:SVD(一)
程序员的自我修养—找工作反思篇
ROS create workspace
State machine in BGP
LeetCode 39. 组合总和
Scheme and implementation of automatic renewal of token expiration
LeetCode 283. Move zero
It is said that Kwai will pay for the Tiktok super fast version of the video? How can you miss this opportunity to collect wool?
TensorRT的功能
I/o impressions from readers | prize collection winners list
Frequently asked questions about jetpack compose and material you
IPv6 experiment and summary
Singleton mode compilation
Community theory | kotlin flow's principle and design philosophy
Style modification of Mui bottom navigation
Classic literature reading -- deformable Detr
LeetCode 83. 删除排序链表中的重复元素