当前位置:网站首页>数据科学【八】:SVD(一)
数据科学【八】:SVD(一)
2022-07-02 06:10:00 【swy_swy_swy】
数据科学【八】:SVD(一)
本文旨在给出SVD的使用方法。具体原理或SVD本身的代码实现请参考其他资料。
SVD主要应用于数据特征提取,数据压缩等。
数据准备
将mnist存入csv
使用fetch_openml可以获得常用数据集,包括mnist_784。
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
X, y = fetch_openml(name="mnist_784", version=1, return_X_y=True, as_frame=False)
import pandas as pd
import numpy as np
full_data = np.c_[y, X]
full_df = pd.DataFrame(full_data)
full_df.to_csv("mnist.csv", index=False)
获得特征值
获得某个“0”的特征值
SVD可以调用numpy的linalg.svd。
import matplotlib.pyplot as plt
full_df = pd.read_csv("mnist.csv", low_memory = False)
full_data = full_df.values
plt.figure()
for n in range(100):
if full_data[n][0] == 0:
print(n)
data = full_data[n][1:].reshape(28, 28)
u, s, v = np.linalg.svd(data)
plt.plot(s)
break
plt.show()

数据压缩
我们可以通过保留部分特征值来进行数据的压缩或模糊。
单图片压缩
示例:通过将一些特征值设置为0,将“0”的图片压缩。
矩阵乘法可以通过numpy.matmul实现。
def image_svd(n, data):
u, s, v = np.linalg.svd(data)
svd = np.zeros((u.shape[0], v.shape[1]))
for i in range(n):
svd[i, i] = s[i]
img = np.matmul(u, svd)
img = np.matmul(img, v)
return img
plt.figure()
plt.subplot(1, 2, 1)
original_img = full_data[1][1:].reshape(28, 28)
plt.imshow(original_img, cmap="gray")
compress_img = image_svd(10, original_img)
plt.subplot(1, 2, 2)
plt.imshow(compress_img, cmap="gray")
plt.show()

全数据集压缩
示例:将整个数据集采用以上方法压缩并存入csv
X_data = full_data[:, range(1, 785)]
app_X = np.zeros(X_data.shape)
for i in range(X_data.shape[1]):
original = X_data[i].reshape(28, 28)
svd_img = image_svd(10, original)
app_X[i] = svd_img.reshape(1,784)
app_df = pd.DataFrame(app_X)
app_df.to_csv("app_mnist.csv", index=False)
一些现象
聚类离散性
首先,我们采用与上一篇同样的方法,对数据集进行十聚类并绘制聚类中心:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
app_df = pd.read_csv("app_mnist.csv", low_memory=False)
kmeans_app = KMeans(n_clusters=10)
kmeans_app.fit(app_df.values)
app_centers = kmeans_app.cluster_centers_
centers_2d = PCA(2).fit_transform(app_centers)
plt.scatter(centers_2d[:, 0], centers_2d[:, 1])
plt.show()
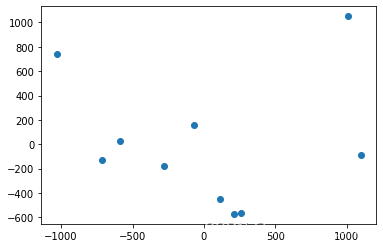
我们在压缩后的数据集上再来一遍:
org_df = pd.read_csv("mnist.csv", low_memory=False)
kmeans_org = KMeans(n_clusters=10)
kmeans_org.fit(org_df.values)
org_centers = kmeans_org.cluster_centers_
centers_2d = PCA(2).fit_transform(org_centers)
plt.scatter(centers_2d[:, 0], centers_2d[:, 1])
plt.show()

聚类准确性
分别计算原数据集与压缩数据集相对于ground truth的disagreement distance:
def disagreement_dist(P_labels, C_labels):
answer = 0
for i in range(len(P_labels)-1):
for j in range(i+1, len(P_labels)):
if (P_labels[i] == P_labels[j]) != (C_labels[i]==C_labels[j]):
answer += 1
return answer
import numpy as np
org_plabels = kmeans_org.labels_
app_plabels = kmeans_app.labels_
clabels = pd.read_csv("mnist.csv", low_memory=False).values[:, [0]]
clabels.reshape(1, len(clabels))
clabels.astype(np.int8)
print("Difference on original dataset:")
print(disagreement_dist(org_plabels, clabels))
print("Difference on approximated dataset:")
print(disagreement_dist(app_plabels, clabels))
Difference on original dataset:
288675700
Difference on approximated dataset:
2161020505
边栏推荐
- Spark overview
- Bgp Routing preference Rules and notice Principles
- AttributeError: ‘str‘ object has no attribute ‘decode‘
- 浏览器原理思维导图
- Replace Django database with MySQL (attributeerror: 'STR' object has no attribute 'decode')
- 网络相关知识(硬件工程师)
- 使用HBuilderX的一些常用功能
- 标签属性disabled selected checked等布尔类型赋值不生效?
- I/o multiplexing & event driven yyds dry inventory
- 深入学习JVM底层(四):类文件结构
猜你喜欢

Pbootcms collection and warehousing tutorial quick collection release
深入学习JVM底层(三):垃圾回收器与内存分配策略

复杂 json数据 js前台解析 详细步骤《案例:一》
BGP中的状态机
ROS2----LifecycleNode生命周期节点总结

The difference between session and cookies

神机百炼3.52-Prim

日志(常用的日志框架)

Support new and old imperial CMS collection and warehousing tutorials
CNN visualization technology -- detailed explanation of cam & grad cam and concise implementation of pytorch
随机推荐
深入学习JVM底层(四):类文件结构
Let every developer use machine learning technology
No subject alternative DNS name matching updates. jenkins. IO found, the reason for the error and how to solve it
CNN visualization technology -- detailed explanation of cam & grad cam and concise implementation of pytorch
The real definition of open source software
Contest3147 - game 38 of 2021 Freshmen's personal training match_ 1: Maximum palindromes
Browser principle mind map
深入了解JUC并发(二)并发理论
BGP 路由優選規則和通告原則
LeetCode 83. Delete duplicate elements in the sorting linked list
500. Keyboard line
Linear DP (split)
Cookie plugin and localforce offline storage plugin
uni-app开发中遇到的问题(持续更新)
Talking about MySQL database
LeetCode 283. 移动零
网络相关知识(硬件工程师)
Support new and old imperial CMS collection and warehousing tutorials
LeetCode 40. Combined sum II
数据回放伴侣Rviz+plotjuggler