当前位置:网站首页>K-means based user portrait clustering model
K-means based user portrait clustering model
2022-07-01 21:37:00 【Desperately_ petty thief】
One 、 summary
Use K-means The main purpose of user clustering is to realize the film recommendation system of user portrait , The recommendation consists of two parts , The first part realizes movie recommendation through collaborative filtering , The second part , Build user portrait to realize movie recommendation , The implementation is realized through static attributes : User's gender , Age , regional , role ( Student 、 Office worker 、 unemployed )、 regional 、 Marital status , Use clustering (K-mens) The algorithm divides the crowd , Realize the movie recommendation of the same crowd , Secondly, dynamic properties : By recording user behavior data , Search record usage word2vec The model realizes similar search keywords and recommends movies .( I will explain the recommendation system later )
The language used in the text is python3.6 The above implementation , The tool used is jupyter-notebook Development , Mainly used python Of sklearn、pandas、faker、matplotlib Wait for the library to realize .
Abstract : This article mainly describes the second part of the use of K-means Clustering builds user portrait model to realize the recommendation of movies loved by the same users .
Two 、 theory
K-means It is an unsupervised clustering algorithm , The main idea is to randomly select K Objects as the initial clustering center . Then calculate the distance between each object and each seed cluster center , To find similar objects .
3、 ... and 、 Realization
- Data acquisition
We need data information before clustering : Including name, 、 Age 、 Gender 、 Address 、 Type of work 、 Marital status, etc , But our thorny problem , Where does the data come from , At present, there are two ways to obtain data : First, you can use web crawler technology to crawl information related personal information , The second kind python Have a powerful library faker It can help us realize the automatic simulation generation of user information .faker You can refer to the blog I wrote before ~ faker Generating user information
from faker import Faker
import pandas as pd
import numpy as np
from collections import OrderedDict
fake = Faker(locale='zh_CN')
sex_dict = OrderedDict([(' male ', 0.52), (' Woman ', 0.48)])
married_dict = OrderedDict([(' unmarried ', 0.4), (' married ', 0.5), (' Divorce ', 0.1), ])
work_dict = OrderedDict([(' on-the-job ', 0.7), (' freelance ', 0.3), ])
type_dict = OrderedDict([(' white collar ', 0.45), (' Teachers' ', 0.1), (' Worker ', 0.2), (' Civil servants ', 0.1), (' sales ', 0.15)])
name = []
age = []
address = []
sex = []
work = []
married = []
type = []
# Number of people generated
num = 1000
# Generate name age address
for i in range(num):
name.append(fake.name())
age.append(fake.random_int(min=16,max=45))
address.append(fake.province())
sex.append(fake.random_element(sex_dict))
work.append(fake.random_element(work_dict))
type.append(fake.random_element(type_dict))
married.append(fake.random_element(married_dict))
data = {'name':name,'age':age,'sex':sex,'address':address,'work':work,'married':married,'type':type}
users = pd.DataFrame.from_dict(data)
- Data processing
Above, we have successfully used faker The library generates user information , But let's think about , It is impossible for computer algorithms to understand the meaning of Chinese , So how to make kmeans The model knows the meaning of these data ? We need to vectorize the data generated above , There are many methods of text vectorization , for example :one-hot、tfidf wait , Of course, different vectorization methods have their own advantages and disadvantages , If you are interested, you can learn about it alone , There is no detailed answer here .
In this article, we use one-hot The idea is to transform the data of different dimensions into data vectors by dictionary mapping .
sex_map = {' male ':0, ' Woman ':1}
married_map = {' unmarried ':0,' married ':1,' Divorce ':2}
work_map = {' on-the-job ':0, ' freelance ':1}
type_map = {' white collar ':0,' Teachers' ':1,' Worker ':2,' Civil servants ':3,' sales ':4}
addr_map = {' Shanghai ':0,' Yunnan Province ':1,' Inner Mongolia Autonomous Region ':2,' The Beijing municipal ':3,' Taiwan Province ':4,' Jilin Province ':5,' Sichuan Province ':6,' tianjin ':7,' Ningxia Hui Autonomous Region ':8
,' Anhui Province ':9,' Shandong Province ':10,' Shanxi Province ':11,' Guangdong province, ':12,
' Guangxi Zhuang Autonomous Region ':13,' Xinjiang Uygur Autonomous Region ':14,' Jiangsu Province ':15,' Jiangxi Province ':16,' Hebei Province ':17,' Henan province ':18,' Zhejiang Province ':19,' Hainan ':20,' Hubei province ':21,' Hunan province ':22,' Macao SAR ':23,' Gansu Province ':24,
' Fujian Province ':25,' Tibet Autonomous Region ': 26,' Guizhou Province ':27,' Liaoning Province ':28,' Chongqing City ':29,' Shaanxi Province ':30,' Qinghai Province ':31,' Hong Kong Special Administrative Region ':32,' Heilongjiang Province ':33}
And then use pandas Medium map Method vectorize each dimension data according to the above dictionary type , After conversion, as shown in the figure below :
users['married'] = users['married'].map(married_map)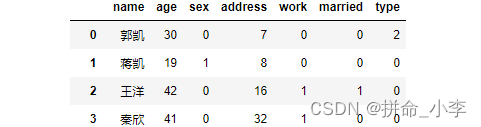
- Model implementation
We use sklearn Machine learning library creation kmeans Model , What we need to pay attention to is that we are using kmeans Before classification , The data is normalized once .
The purpose of data standardization is to readjust the value of each dimension of data , Make the final data vector fall in [0,1] Within the interval , After standardized treatment , The original data is transformed into dimensionless index evaluation value , Each index value is at the same quantity level , Comprehensive evaluation and analysis can be carried out . If the original index value is directly used for analysis , It will highlight the role of indicators with higher values in comprehensive analysis , Relatively weaken the role of indicators with low numerical level .
I will standardize the steps and kmeans The model makes a connection, so they are all put together , The implementation code is as follows :
model = Pipeline([
('BN',preprocessing.StandardScaler()),('KMS',KMeans())
])
model.fit(X)
# Save the model
joblib.dump(model, "./model/model.pkl")
model = joblib.load("./model/model.pkl")
y_pred = model.predict(X)
# Store the prediction results in the vectorized total data
users['lable'] = y_pred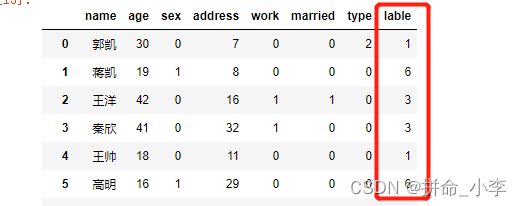
- The model is saved and tested
model = joblib.load("./model/model.pkl")
y_pred = model.predict([X[0]])
y_pred- Visualization of clustering results
Use adviz The principle of visualization is to map a series of points in multi-dimensional space to two-dimensional space through nonlinear method .
import matplotlib.pyplot as plt
from pandas.plotting import radviz
"""
adviz The visualization principle is a visualization technology that maps a series of points in multi-dimensional space to two-dimensional space through nonlinear method , It is a multi-dimensional visualization method based on the design idea of circular parallel coordinate system . circular m Bar radius representation m Dimensional space , Use a point in the coordinate system to represent many information objects , Its realization principle refers to the force balance theorem of objects in physics .
mm Points in dimensional space {Ai1,Ai2,...,AimAi1,Ai2,...,Aim} The position mapped to the two-dimensional visual space is determined by the spring gravity analysis model .
First, divide a circle into mm Share , The number of bisectors is determined by the data dimension , Record the bisection points as {R1,R2,...,RnR1,R2,...,Rn}, A spring is fixed on each bisection point , The elastic coefficient of each spring is different , Spring jj The coefficient of elasticity is AijAij, That is the first. jj Value of dimension , all mm The other end of a spring is fixed on a small circle , If the small circle finally reaches an equilibrium position Bi={Xi,Yi}TBi={Xi,Yi}T, Then the elastic balance point {Xi,Yi}{Xi,Yi} Namely m Dimensional space points { Ai1,Ai2,...,AimAi1,Ai2,...,Aim} Projection point in two-dimensional space .
Blog :https://blog.csdn.net/Haiyang_Duan/article/details/78985225
"""
plt.figure(' User portrait clustering ',figsize=(15, 7.5), dpi=80)
plt.title('radviz')
radviz(users.loc[:,'age':], class_column='lable')
plt.show()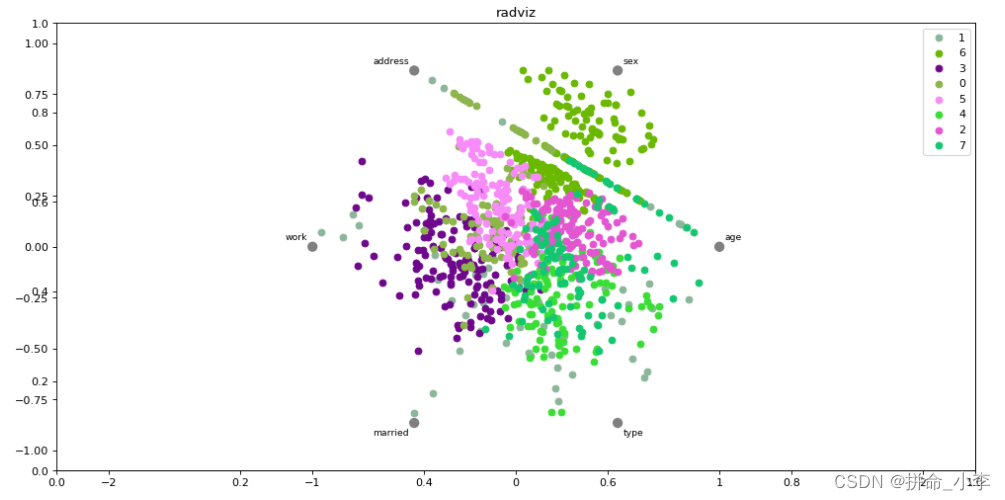
边栏推荐
猜你喜欢






随机推荐
Importance of EDA tools to chip industry knowledge popularization
一次调试去了解redis集群的slot机制
基于YOLOv5的口罩佩戴检测方法
GCC编译
deb文件安装
个人炒股怎样开户?安全吗。
杰理之、产线装配环节【篇】
String类型转换BigDecimal、Date类型
Détection des cibles - série Yolo
PLC模拟量输入 模拟量转换FB S_ITR(三菱FX3U)
能升职加薪?PMP证书含金量浅析
Kuberntes云原生实战一 高可用部署架构
Difference and use between require and import
require与import的区别和使用
《QTreeView+QAbstractItemModel自定义模型》:系列教程之三[通俗易懂]
功利点没啥!
CNN卷积神经网络原理讲解+图片识别应用(附源码)[通俗易懂]
PCB线路板塞孔工艺的那些事儿~
【级联分类器训练参数】Training Haar Cascades
新版图解网络PDF即将发布