当前位置:网站首页>ConcurrentSkipListMap——跳表原理
ConcurrentSkipListMap——跳表原理
2022-07-01 23:17:00 【HD243608836】
为了引出 ConcurrentSkipListMap,先来简单理解下什么是跳表。
对于单链表,即使链表是有序的,如果想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,跳表就不一样了。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整;而对跳表的插入和删除,只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,需要一个全局锁,来保证整个平衡树的线程安全;而对于跳表,则只需要部分锁即可。这样,在高并发环境下,就可以拥有更好的性能。就查询的性能而言,跳表的时间复杂度是 O(logn), 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
跳表的本质,是同时维护了多个链表,并且链表是分层的:

最低层的链表,维护了跳表内所有的元素,每上面一层链表,都是下面一层的子集。
跳表内所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素18。

查找18 的时候,原来需要遍历 18 次,现在只需要 7 次即可。针对链表长度比较大的时候,构建索引,查找效率的提升就会非常明显。
从上面很容易看出,跳表是一种利用空间换时间的算法。
使用跳表实现 Map,和使用哈希算法实现 Map 的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此,在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。
JDK 中实现这一数据结构的类是 ConcurrentSkipListMap。
边栏推荐
- Redis 主从同步
- Is there a piece of code that makes you convinced by human wisdom
- Depth first search and breadth first search of graph traversal
- Typescript enumeration
- URL introduction
- 学成在线案例实战
- Stm32f030f4 drives tim1637 nixie tube chip
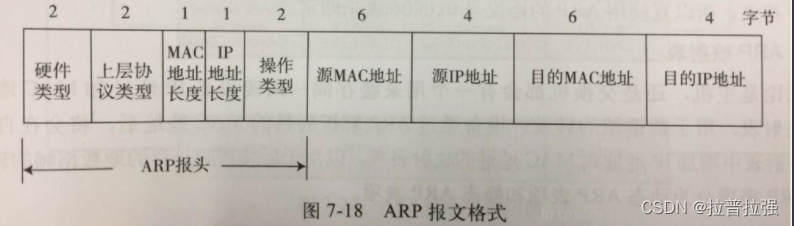
- ARP message header format and request flow
- Leetcode(34)——在排序数组中查找元素的第一个和最后一个位置
- Know --matplotlib
猜你喜欢







随机推荐
距离度量 —— 汉明距离(Hamming Distance)
Practical application and extension of plain framework
ShanDong Multi-University Training #3
共享电商的背后: 共创、共生、共享、共富,共赢的共富精神
ShanDong Multi-University Training #3
物联网开发零基础教程
Leetcode(34)——在排序数组中查找元素的第一个和最后一个位置
Switch to software testing, knowing these four points is enough!
mt管理器测试滑雪大冒险
sql 优化
为什么PHP叫超文本预处理器
What is the difference between memory leak and memory overflow?
Redis AOF log
MT manager test skiing Adventure
SWT / anr problem - SWT causes low memory killer (LMK)
Redis RDB快照
STM32F030F4驱动TIM1637数码管芯片
【微服务|Sentinel】@SentinelResource详解
有没有一段代码,让你为人类的智慧所折服
Huisheng Huiying 2022 intelligent, fast and simple video editing software