当前位置:网站首页>NLP four paradigms: paradigm 1: fully supervised learning in the era of non neural networks (Feature Engineering); Paradigm 2: fully supervised learning based on neural network (Architecture Engineeri
NLP four paradigms: paradigm 1: fully supervised learning in the era of non neural networks (Feature Engineering); Paradigm 2: fully supervised learning based on neural network (Architecture Engineeri
2022-07-03 16:35:00 【u013250861】

natural language processing (Natural Language Processing,NLP) It's computer science , Artificial intelligence , Linguistics is the field of interaction between computers and human natural language , It is an important direction in the field of computer science and artificial intelligence .
Natural language processing has a long history , As early as 1949 In the year , American Weaver put forward the design scheme of machine translation , It can be regarded as the beginning of the field of natural language processing , Since then, natural language processing has been developing , In the last century, the methods in this field are mainly rule-based methods and statistical methods , This kind of method is inefficient , Labor cost , And cannot handle large data sets , Therefore, the field of natural language processing has been tepid .
2008 Since then , With the deep learning, it has achieved success in the field of speech recognition and image processing , Researchers began to use deep learning methods to deal with natural language processing problems , From the initial word vector , To 2013 Year of word2vec, Until then 2018 Year of bert, Finally, up to now prompt, Natural language processing technology has developed rapidly in the past decade .
CMU Dr. liupengfei of summarized four paradigms in the development of natural language processing technology , Each paradigm represents a type of natural language processing , This article combines some simple examples , To sum up NLP Four paradigms in .
One 、 First normal form : Fully supervised learning in the age of non neural networks ( Feature Engineering )
The first paradigm refers to before the introduction of Neural Networks NLP How to deal with the field , Extract some features from natural language corpus , Use specific rules or Mathematics 、 Statistical models to match and utilize features , And then complete a specific NLP Mission . Common methods such as the following methods to classify sequences 、 Sequence labeling and other tasks :
- Bayes
- veterbi Algorithm
- hidden Markov model
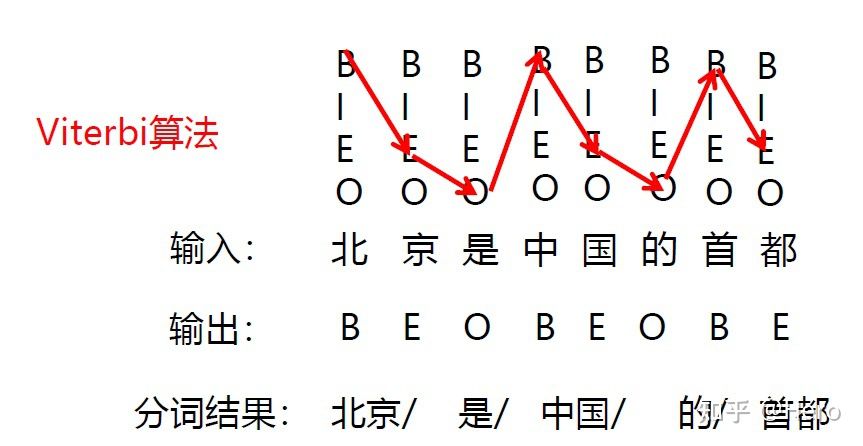
Two 、 Second normal form : Fully supervised learning based on neural network ( Architecture Engineering )
The second paradigm refers to After the introduction of neural network , Before the pre training model appeared NLP Research methods in the field .
Such methods do not need to manually set features and rules , It saves a lot of human resources , However, it is still necessary to manually design a suitable neural network architecture to train the data set . Common methods like CNN、RNN、 In machine translation Seq2Seq Models and so on .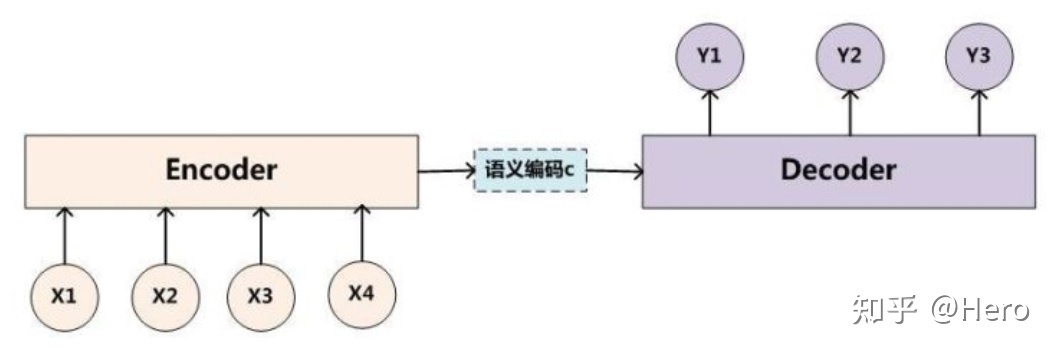
3、 ... and 、 Third normal form : Preliminary training , Fine tuning paradigm ( Target project )
The third paradigm refers to pre training on a large unsupervised data set , Learn some common grammatical and semantic features , Then use the pre trained model on the specific data set of downstream tasks fine-tuning, Make the model more suitable for downstream tasks .
GPT、Bert、XLNet And other models belong to the third paradigm , Its characteristic is that it does not need a large amount of supervised downstream task data , The model is mainly trained on large unsupervised data , Only a small amount of downstream task data is needed to fine tune a small amount of network layer .
Four 、 Fourth normal form : Preliminary training , Tips , Prediction paradigm (Prompt engineering )
The fourth paradigm refers to Redefine the modeling method of downstream tasks : Through the right prompt( Prompt 、 The clue word ) To solve downstream tasks directly on the pre training model , This model requires very little ( You don't even need to ) Downstream task data , Make a small sample 、 Zero sample learning becomes possible .
The third paradigm mentioned above fine-tuning The process is to adjust the pre training model , Make it more suitable for downstream tasks , Then the fourth paradigm is just the opposite ,prompt The process is to adjust downstream tasks , Make it better match the pre training model . That is, the third paradigm is that the pre training model accommodates downstream tasks , The fourth paradigm is the downstream task accommodation pre training model .
So how to transform the downstream tasks to better accommodate the pre training model ? With Bert For example ,Bert There are two pre training tasks ,Masked LM Cloze task and Next Sentence Prediction Next sentence prediction task , For these two different and training tasks ,prompt The types of can also be divided into two categories :
- Cloze prompt
- Fill in the blanks prompt: Such as emotion classification task , Input is 【 This toy is good 】, Can be prompt Change to : This toy is good , too 【Z】,Z The output of is “ Great ”.
- classification 、 matching 、 choice Related tasks often use cloze prompt( Self coding )
- Prefix hint prompt
- Prefix hint prompt: For example, machine translation tasks , Input is 【 study hard 】, Can be prompt Change to : study hard , Translate into English :【Z】,Z The output of is "good good english".
- Generate Related tasks often use prefix prompts prompt( Autoregression ).
1、 2. Classified tasks prompt Example
Suppose there is an emotion classification task , Input sentences X, Output their emotional tags Y{ positive , Negative }.
For example, for " The service in this restaurant is really good ." This sentence classifies emotions ,
- First construct prompt:_____ Satisfied , The service in this restaurant is really good , Change the input sentence into this prompt,
- Then put the label Y It maps to { very , No }( Very satisfied represents positive , Dissatisfaction means negative ).
Due to the normal Bert Of MLM The pre training task is to predict the whole vocabulary , And the above prompt Only two words predicted { very , No }, Therefore, we need to adjust the vocabulary , Then the cross entropy loss function is used to model .
therefore , The whole process of the fourth paradigm is :
- First construct the input as prompt,
- Then construct the corresponding prompt The label of ,
- Then map the input sentence 、 Map the original label of the downstream task ,
- Use mapped prompt Input and fine tune the model with the new label .
2、 Match task prompt Example
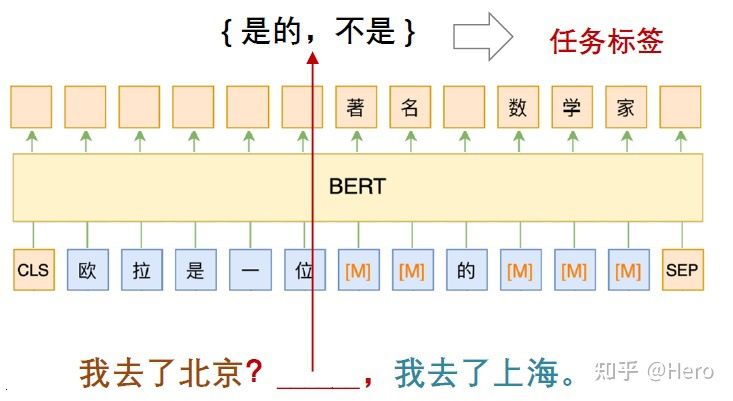
For example, judgment " I went to Beijing " and " I went to Shanghai " The connection between these two sentences , You can use cloze to construct prompt:
- I went to Beijing ?_____, I went to Shanghai .
Map the two input sentences to prompt, Then remove the label from { matching , Mismatch } It maps to { Yes , No }, With the help of MLM Model training .
3、 There are three main problems in the research field of the fourth paradigm
There are three main problems in the research field of the fourth paradigm :
- For input : How to construct prompt, Better modeling of downstream tasks , To be able to Stimulate the potential of the pre training model ;
- For output : how Map the original tag to prompt Corresponding new label ;
- For the model : How to fine tune the pre training model ;
3.1 structure prompt
First , about prompt, Mainly refers to " Attach a supplementary description to the original input , Through this supplementary description statement, we can realize task transformation and task solution , This description statement and the original input together form a semantically reasonable statement as prompt The input of ".
in other words , For input text x, It can be generated in two steps prompt:
- First step : Use a template ( Natural language fragments ), The template contains two empty locations , Used to fill in x And generate answer text z
- The second step is to fill the input into x Location
Reference material :
NLP Four paradigms of
边栏推荐
- IDEA-配置插件
- SVN使用规范
- 记一次jar包冲突解决过程
- [combinatorics] non descending path problem (outline of non descending path problem | basic model of non descending path problem | non descending path problem expansion model 1 non origin starting poi
- Golang 匿名函数使用
- Remote file contains actual operation
- 【剑指 Offer 】57 - II. 和为s的连续正数序列
- 1287. Elements that appear more than 25% in an ordered array
- Is it safe to open an account with tongdaxin?
- Register in PHP_ Globals parameter settings
猜你喜欢
![[web security] - [SQL injection] - error detection injection](/img/18/5c511871dab0e5c684b6b4c081c061.jpg)
[web security] - [SQL injection] - error detection injection

NSQ源码安装运行过程

Unreal_DataTable 实现Id自增与设置RowName
![[proteus simulation] 74hc595+74ls154 drive display 16x16 dot matrix](/img/d6/3c21c25f1c750f17aeb871124e80f4.png)
[proteus simulation] 74hc595+74ls154 drive display 16x16 dot matrix

Cocos Creator 2. X automatic packaging (build + compile)
Détails du contrôle de la congestion TCP | 3. Espace de conception

0214-27100 a day with little fluctuation
Explore Netease's large-scale automated testing solutions see here see here

线程池执行定时任务

什么是质押池,如何进行质押呢?
随机推荐
【声明】关于检索SogK1997而找到诸多网页爬虫结果这件事
面试官:JVM如何分配和回收堆外内存
在ntpdate同步时间的时候出现“the NTP socket is in use, exiting”
[web security] - [SQL injection] - error detection injection
EditText request focus - EditText request focus
Svn usage specification
PyTorch 1.12发布,正式支持苹果M1芯片GPU加速,修复众多Bug
Thread pool executes scheduled tasks
相同切入点的抽取
8 cool visual charts to quickly write the visual analysis report that the boss likes to see
Nifi from introduction to practice (nanny level tutorial) - flow
Golang decorator mode and its use in NSQ
word 退格键删除不了选中文本,只能按delete
用通达信炒股开户安全吗?
MySQL single table field duplicate data takes the latest SQL statement
How to initialize views when loading through storyboards- How is view initialized when loaded via a storyboard?
Register in PHP_ Globals parameter settings
Mixlab编辑团队招募队友啦~~
爱可可AI前沿推介(7.3)
Unreal_ Datatable implements ID self increment and sets rowname