当前位置:网站首页>【论文笔记】Understanding Long Programming Languages with Structure-Aware Sparse Attention
【论文笔记】Understanding Long Programming Languages with Structure-Aware Sparse Attention
2022-08-04 08:08:00 【m0_61899108】
论文

论文题目:Understanding Long Programming Languages with Structure-Aware Sparse Attention
收录于: SIGIR 2022
项目地址:GitHub - alibaba/EasyNLP: EasyNLP: A Comprehensive and Easy-to-use NLP Toolkit
参考博客:【SIGIR 2022】面向长代码序列的Transformer模型优化方法,提升长代码场景性能 - 掘金 (juejin.cn)
简介
基于编程的预训练语言模型(PPLM),如CodeBERT,在许多与下游代码相关的任务中取得了巨大的成功。但由于Transformer中自我注意的内存和计算复杂性随着序列长度的增加而呈二次曲线增长,因此PPLM通常将代码长度限制在512。然而,现实应用中的代码通常很长,例如代码搜索,现有的PPLM无法有效地处理这些代码。
为解决这一问题,本文提出结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于提升长代码场景下的效果和性能。由于self-attention模块的复杂度随序列长度呈次方增长,多数编程预训练语言模型(Programming-based Pretrained Language Models, PPLM)采用序列截断的方式处理代码序列。SASA方法将self-attention的计算稀疏化,同时结合了代码的结构特性,从而提升了长序列任务的性能,也降低了内存和计算复杂度。
模型框架
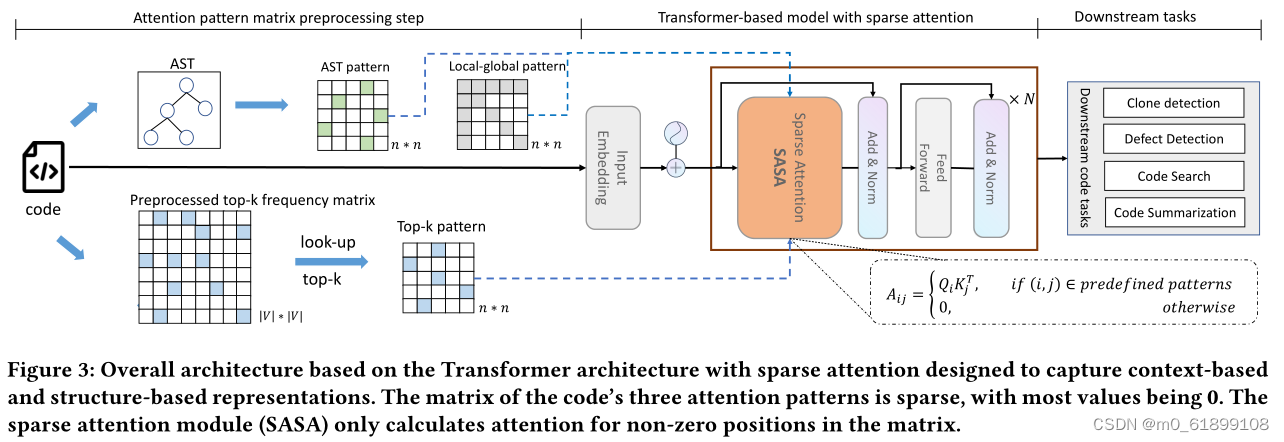
其中,SASA主要包含两个阶段:预处理阶段和Sparse Transformer训练阶段。
- 在预处理阶段得到两个token之间的交互矩阵,一个是top-k frequency矩阵,一个是AST pattern矩阵。Top-k frequency矩阵是利用代码预训练语言模型在CodeSearchNet语料上学习token之间的attention交互频率,AST pattern矩阵是解析代码的抽象语法树(Abstract Syntax Tree,AST ),根据语法树的连接关系得到token之间的交互信息。
- Sparse Transformer训练阶段以Transformer Encoder作为基础框架,将full self-attention替换为structure-aware sparse self-attention,在符合特定模式的token pair之间进行attention计算,从而降低计算复杂度。
SASA稀疏注意力一共包括如下四个模块:
- Sliding window attention:仅在滑动窗口内的token之间计算self-attention,保留局部上下文的特征,计算复杂度为O(n×w),n为序列长度,w是滑动窗口大小。
- Global attention:设置一定的global token,这些token将与序列中所有token进行attention计算,从而获取序列的全局信息,计算复杂度为O(n×g),g为global token个数。
- Top-k sparse attention:Transformer模型中的attention交互是稀疏且长尾的,对于每个token,仅与其attention交互最高的top-k个token计算attention,复杂度为O(n×k)。
- AST-aware structure attention:代码不同于自然语言序列,有更强的结构特性,通过将代码解析成抽象语法树(AST),然后根据语法树中的连接关系确定attention计算的范围。
为了适应现代硬件的并行计算特性,论文将序列划分为若干block,而非以token为单位进行计算,每个query block与w个滑动窗口blocks和g个global blocks以及k个top-k和AST blocks计算attention,总体的计算复杂度为O(n(w+g+k)b),b为block size。
每个sparse attention pattern 对应一个attention矩阵,以sliding window attention为例,其attention矩阵的计算为:
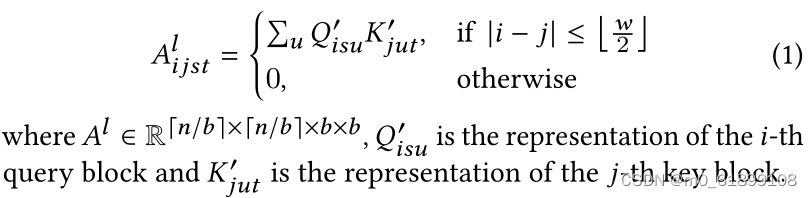
SASA伪代码:

实验结果
采用CodeXGLUE[1]提供的四个任务数据集进行评测,分别为code clone detection,defect detection,code search,code summarization。我们提取其中的序列长度大于512的数据组成长序列数据集,实验结果如下:
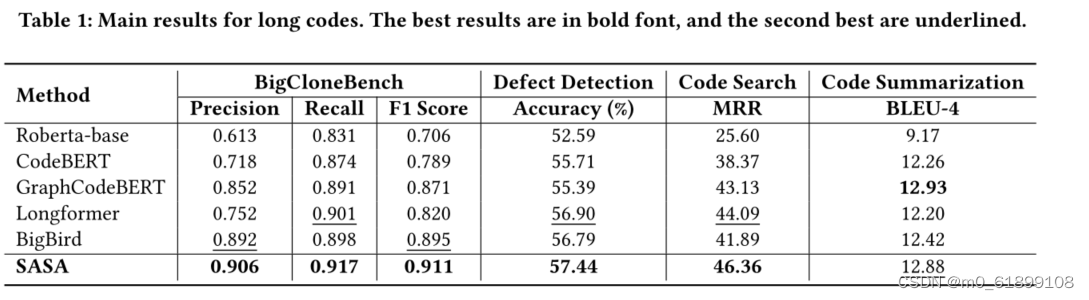
从实验结果可以看出,SASA在三个数据集上的性能明显超过所有Baseline。其中Roberta-base[2],CodeBERT[3],GraphCodeBERT[4]是采用截断的方式处理长序列,这将损失一部分的上下文信息。Longformer[5]和BigBird[6]是在自然语言处理中用于处理长序列的方法,但未考虑代码的结构特性,直接迁移到代码任务上效果不佳。
为了验证top-k sparse attention和AST-aware sparse attention模块的效果,在BigCloneBench和Defect Detection数据集上做了消融实验,结果如下:
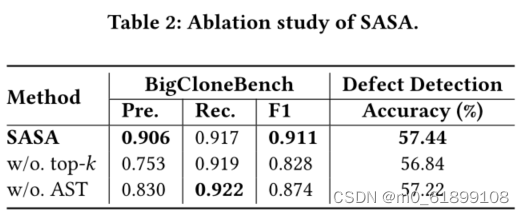
sparse attention模块不仅对于长代码的任务性能有提升,还可以大幅减少显存使用,在同样的设备下,SASA可以设置更大的batch size,而full self-attention的模型则面临out of memory的问题,具体显存使用情况如下图:
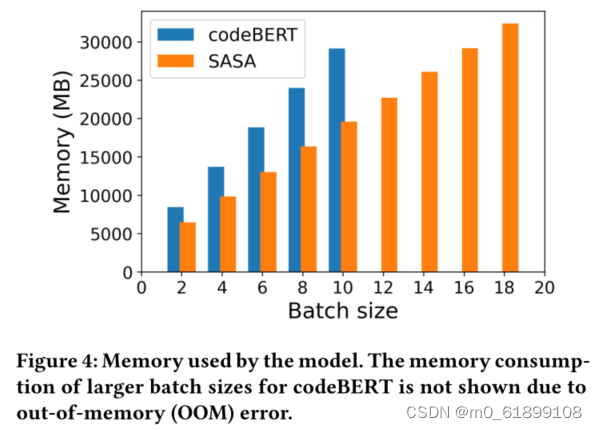
SASA作为一个sparse attention的模块,可以迁移到基于Transformer的其他预训练模型上,用于处理长序列的自然语言处理任务。
边栏推荐
- redis---分布式锁存在的问题及解决方案(Redisson)
- 图的基本概念
- powershell和cmd对比
- 给Unity Behavior Designer(Unity行为树) 的Can See Object 画圆锥辅助图
- 大家好,请教一个问题啊,我们通过flinkcdc把Oracle数据同步到doris,目前的问题是,只
- ShuffleNet v2 network structure reproduction (Pytorch version)
- 金仓数据库KingbaseES客户端编程接口指南-JDBC(9. JDBC 读写分离)
- C语言strchr()函数以及strstr()函数的实现
- ConstraintSet of animation of ContrstrainLayout
- 华为设备配置VRRP与路由联动监视上行链路
猜你喜欢



随机推荐
【JS 逆向百例】某网站加速乐 Cookie 混淆逆向详解
RT-Thread Studio学习(十一)IIC
怎么写专利更容易通过?
GBase 8c数据库集群中,怎么替换节点呢?比如设置A节点为gtm,换到B节点上。
金仓数据库的单节点如何转集群?
分布式计算MapReduce | Spark实验
js - the first letter that appears twice
线程的状态
Secondary network security competition C module MS17-010 batch scanning
ContrstrainLayout的动画之ConstraintSet
高等代数_证明_对称矩阵属于不同特征值的特征向量正交
『递归』递归概念与典型实例
leetcode 22.8.1 二进制加法
一天搞定JDBC02:开启事务
解决报错: YarnScheduler: Initial job has not accepted any resources
Use of MotionLayout
【NOI模拟赛】纸老虎博弈(博弈论SG函数,长链剖分)
分布式计算实验2 线程池
Typora颜色公式代码大全
The national vocational skills contest competition of network security emergency response