当前位置:网站首页>Optimal Transport系列1
Optimal Transport系列1
2022-07-01 02:25:00 【Daft shiner】
鉴于Optimal Transport在Machine Learning领域的广泛使用,笔者想认真学习一下Optimal Transport,网上资料很多,但是由于笔者愚钝,找了很久才找到浅显易懂的资料。本博客旨在用最浅显的方式来描述清楚Optimal transport,由于数学能力有限,如果有讲错的地方希望各位看官能及时指正。
Prior Knowledge

L1 Distance: d L 1 ( ρ 1 , ρ 2 ) = ∫ − ∞ + ∞ ∣ ρ 1 ( x ) − ρ 2 ( x ) ∣ d x d_{L_1}(\rho_1,\rho_2)=\int_{-\infty}^{+\infty}|\rho_1(x)-\rho_2(x)|dx dL1(ρ1,ρ2)=∫−∞+∞∣ρ1(x)−ρ2(x)∣dx
KL divergence: d K L ( ρ 1 ∣ ∣ ρ 2 ) = ∫ − ∞ + ∞ ρ 1 ( x ) l o g ρ 1 ( x ) ρ 2 ( x ) d x d_{KL}(\rho_1||\rho_2)=\int_{-\infty}^{+\infty}\rho_1(x)log\frac{\rho_1(x)}{\rho_2(x)}dx dKL(ρ1∣∣ρ2)=∫−∞+∞ρ1(x)logρ2(x)ρ1(x)dx
如果要衡量上图(源自参考文献1)中 ρ 1 \rho_1 ρ1到 ρ 2 \rho_2 ρ2的距离和 ρ 1 \rho_1 ρ1到 ρ 3 \rho_3 ρ3的距离,可以发现使用L1 Distance和KL divergence都失效,其算出来的都是一样的。
注意:对了L1 Distance来说,距离相同很好理解,因为其计算的就是两个分布的面积。而对于KL divergence来说,首先需要注意他不是一个距离测度,Because it is not symmetric: the KL from ρ 1 ( x ) \rho_1(x) ρ1(x) to ρ 2 ( x ) \rho_2(x) ρ2(x) is generally not the same as the KL from ρ 1 ( x ) \rho_1(x) ρ1(x) to ρ 2 ( x ) \rho_2(x) ρ2(x). Furthermore, it need not satisfy triangular inequality. 我们将Kullback-Leibler Divergence变化一下形式可得 d K L ( ρ 1 ∣ ∣ ρ 2 ) = ∫ − ∞ + ∞ ρ 1 ( x ) l o g ( ρ 1 ( x ) ) − ρ 1 ( x ) l o g ( ρ 2 ( x ) ) d x d_{KL}(\rho_1||\rho_2)=\int_{-\infty}^{+\infty}\rho_1(x)log(\rho_1(x))-\rho_1(x)log(\rho_2(x))dx dKL(ρ1∣∣ρ2)=∫−∞+∞ρ1(x)log(ρ1(x))−ρ1(x)log(ρ2(x))dx然后把 ρ 1 ( x ) l o g ( ρ 1 ( x ) ) \rho_1(x)log(\rho_1(x)) ρ1(x)log(ρ1(x))和 ρ 1 ( x ) l o g ( ρ 2 ( x ) ) \rho_1(x)log(\rho_2(x)) ρ1(x)log(ρ2(x))看成两个新的分布,那么同样转化成了面积关系,由于前一项是一样的,所以主要要看后一项的差异。为了更好的理解,笔者用python写了个简单的demo:注意,这里笔者发现了一个大问题!!!
import math
import numpy as np
import matplotlib.pyplot as plt
def guassian(u, sig):
# 均值μ, 标准差δ
x = np.linspace(-30, 30, 1000000) # 定义域
y = np.exp(-(x - u) ** 2 / (2 * sig ** 2)) / (math.sqrt(2*math.pi)*sig) # 定义曲线函数
return x, y
x1, y1 = guassian(u=0, sig=math.sqrt(1))
x2, y2 = guassian(u=1, sig=math.sqrt(1))
x3, y3 = guassian(u=2, sig=math.sqrt(1))
plt.plot(x1,y1)
plt.plot(x2,y2)
plt.plot(x3,y3)
z1 = y1 * np.log2(y1) - y1 * np.log2(y2)
z2 = y1 * np.log2(y1) - y1 * np.log2(y3)
# plt.plot(x1, z1)
# plt.plot(x1, z2)
print(np.sum(z1))
print(np.sum(z2))
通过实验发现,实验结果和预期完全不一样,我使用KL divergence计算 ρ 1 \rho_1 ρ1到 ρ 2 \rho_2 ρ2的距离和 ρ 1 \rho_1 ρ1到 ρ 3 \rho_3 ρ3的距离并不是一样的,差异很大!!!
我可视化了后一项的分布曲线,发现完全不一样,且积分后的值也完全不同。(这里我考虑到了连续变成了离散的影响,所以调过x坐标范围和画的点数,没啥区别)后来研究一下发现,文章中给的曲线貌似不是高斯分布的曲线,感觉有点被误导,所以我换了一个例子来算,虽然是离散的分布,但是还是能比较直观的反映问题的(PS,这里其实很好奇为啥用高斯分布会不行,有大佬知道原因吗):
可以发现对于上述的分布,L1 Distance和KL divergence都失效了。
Optimal Transport
上一节讲了L1 Distance和KL divergence存在的问题,本节将详细描述Optimal Transport,首先定义问题。Optimal Transport的核心在于如何找到一个最优转化将一个分布转化为另一个分布,且要使得转化损失最小。(注意:这里的分布可以是连续或者离散的)这里用上图中的 ρ 1 \rho_1 ρ1和 ρ 2 \rho_2 ρ2举例:
为了方便理解,我们可以将 ρ 1 \rho_1 ρ1和 ρ 2 \rho_2 ρ2想象成一堆沙子,那么Optimal Transport问题就变成了如何把 ρ 1 \rho_1 ρ1形状的沙子堆成 ρ 2 \rho_2 ρ2的样子,且做功要最小。 π ( x , y ) \pi(x,y) π(x,y)代表从x位置搬多少质量的沙子到y位置,那么显然 ρ 1 ( x ) \rho_1(x) ρ1(x)表示x位置总共有多少质量的沙子(大白话就是x位置曲线的高度)。所以问题就可以用下式来表示: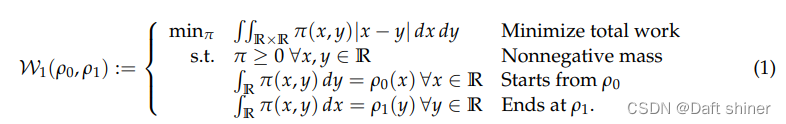
其中目标函数为搬运做功最小,因为搬运沙子的质量要大于等于0,所以约束的第一条也好理解,至于第二和第三条,是满足它初始和最终的分布。This amount of work is known as the 1-Wasserstein distance in optimal transport。接下来把他泛化到p-Wasserstein distance:
同样比较好理解,只是运输的距离发生了改变。问题定义完了以后,那么如何才能求得这个 π ( x , y ) \pi(x,y) π(x,y)呢?
Discrete Problems in One Dimension

对于一维问题有以上两种情况:D2D,D2C。对于D2D的数据,我们首先松弛原有的分布函数 ρ ( x ) \rho(x) ρ(x)到 μ 0 , μ 1 ∈ P r o b ( R ) \mu_0,\mu_1 \in Prob(\mathbb{R}) μ0,μ1∈Prob(R),Define the Dirac δ \delta δ-measure centered at x ∈ R x \in \mathbb{R} x∈R via (:=在数学中表示为定义为)
δ x ( S ) : = { 1 , i f x ∈ S 0 , O t h e r w i s e . \delta_x(S):= \begin{cases} 1, &if\ x\ \in\ S\\ 0, &Otherwise. \end{cases} δx(S):={ 1,0,if x ∈ SOtherwise.此时 μ 0 , μ 1 \mu_0,\mu_1 μ0,μ1分别为:
其中 ∑ i a 0 i = ∑ i a 1 i = 1 \sum_ia_{0i}=\sum_ia_{1i}=1 ∑ia0i=∑ia1i=1, a 0 i , a 1 i ≥ 0 a_{0i},a_{1i} \ge 0 a0i,a1i≥0。个人认为这里的 S S S是 [ x 01 , x 02 , ⋯ , x 0 k 0 ] [x_{01}, x_{02}, \cdots, x_{0k_0}] [x01,x02,⋯,x0k0]的子集。这时问题的计算为:
同样和上面的解释方法一样, T i j T_{ij} Tij表示从 x 0 i x_{0i} x0i运输到 x 1 j x_{1j} x1j的质量。 ∣ x 0 i − x 1 j ∣ p |x_{0i}-x_{1j}|^p ∣x0i−x1j∣p是从 x 0 i x_{0i} x0i运输到 x 1 j x_{1j} x1j的距离。 T i j T_{ij} Tij运输质量要大于等于0, x 0 i x_{0i} x0i和 x 1 j x_{1j} x1j处的质量要满足守恒条件。要求 T i j T_{ij} Tij,这是一个有限元的线性规划,可以使用许多经典算法求解,例如 simplex or interior point methods。而对于D2C的情况,每个离散的 μ 0 \mu_0 μ0都映射到一段连续的区间 μ 1 \mu_1 μ1,如下图所示: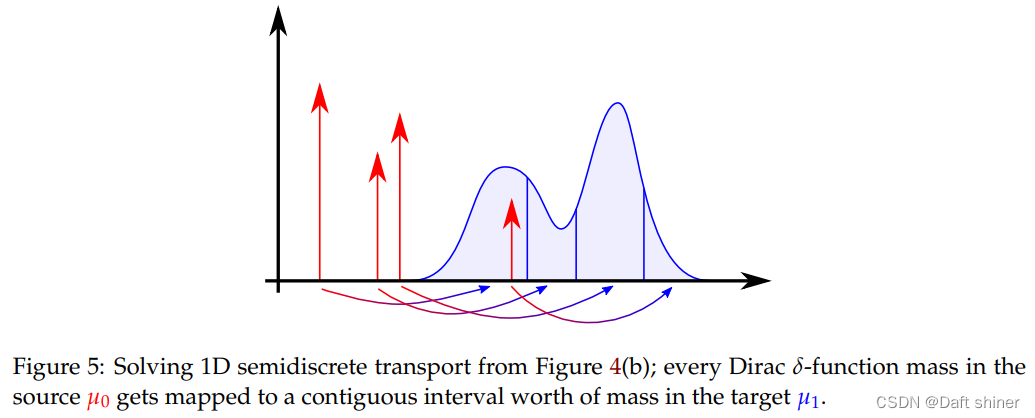
Conclusion
本节主要讲了Optimal Transport的两种形式(D2C,D2D),下一节将介绍其更加general的形式。
References
[1] Optimal Transport on Discrete Domains
[2] Kullback-Leibler Divergence
[3] Optimal Transport and Wasserstein Distance
边栏推荐
- SWT/ANR问题--ANR/JE引发SWT
- Template: globally balanced binary tree
- Pulsar Geo Replication/灾备/地域复制
- FL studio20.9 fruit software advanced Chinese edition electronic music arrangement
- MySQL insert \ pre update + judgment condition
- 7_OpenResty安装
- SWT/ANR问题--Deadlock
- [proteus simulation] Arduino UNO +74c922 keyboard decoding drive 4x4 matrix keyboard
- SWT/ANR问题--Native方法执行时间过长导致SWT
- Calculate special bonus
猜你喜欢

PMP是什麼?

centos 安装多个版本的php并切换
The latest CSDN salary increase technology stack in 2022 overview of APP automated testing

Rocketqa: cross batch negatives, de noised hard negative sampling and data augmentation

5款主流智能音箱入门款测评:苹果小米华为天猫小度,谁的表现更胜一筹?

手机edge浏览器无法打开三方应用
What is PMP?

LabVIEW计算相机图像传感器分辨率以及镜头焦距

AI edge computing platform - beaglebone AI 64 introduction

js中的图片预加载

随机推荐
十大劵商如何开户?还有,在线开户安全么?
How to realize the scene linkage of intelligent lock, lamp and intelligent curtain motor in zhiting?
URLs and URIs
Clickhouse 消除由group by产生的间隙
Windows quick add boot entry
Zero foundation self-study SQL course | window function
如何在智汀中实现智能锁与灯、智能窗帘电机场景联动?
(总结一)Halcon基础之寻找目标特征+转正
@ConfigurationProperties和@Value的区别
详解数据治理知识体系
机器学习10-信念贝叶斯分类器
SWT / anr problem - anr/je causes SWT
SQL语句关联表 如何添加关联表的条件 [需要null值或不需要null值]
pycharm 软件deployment 灰色 无法点
LabVIEW calculates the camera image sensor resolution and lens focal length
PMP是什麼?
Delete duplicate email
Do you write API documents or code first?
SWT/ANR问题--StorageManagerService卡住
Objects and object variables