当前位置:网站首页>Inventory of CV neural network models from 2021 to 2022
Inventory of CV neural network models from 2021 to 2022
2022-06-12 22:26:00 【Wood calyx】
stay transformer Sweep up CV After the field , It has set off an upsurge of new neural network models . In just a year or two , Researchers from different structural fields impact SOTA, Yes ViT Of , Yes CNN Of , And even pure MLP Of . among , There are some Enlightening and foundational The emergence of models , I vaguely feel that these two years are the outbreak years of basic models .ViT Leading the way 2012 year AlexNet and 2015 year ResNet After that, the third basic model broke out . therefore , Mu Zhan makes an incomplete summary of this blog post , Organize for everyone to browse , Maybe you can meet someone who is helpful trick. Besides , I still have some in ImageNet Some conclusions can be drawn from the experience of repetition on , Attached to the comments on each model .
This article covers 8 An excellent model , The approximate time when the model appears can be arxiv Link to see . among 3 One from MSRA、3 One from FAIR:
| num | model | org | conf | paper link |
|---|---|---|---|---|
| 1 | Swin Transformer | MSRA | ICCV2021(best paper) | https://arxiv.org/abs/2103.14030 |
| 2 | MLPMixer | MSRA | arxiv | https://arxiv.org/abs/2105.01601 |
| 3 | DeiT | FAIR | arxiv | https://arxiv.org/abs/2012.12877v2 |
| 4 | ConvNext | FAIR | arxiv | https://arxiv.org/abs/2201.03545 |
| 5 | SPACH | MSRA | arxiv | https://arxiv.org/abs/2108.13002 |
| 6 | LeViT | FAIR | ICCV2021 | paper link |
| 7 | MobileViT | Apple | ICLR2022 | https://arxiv.org/abs/2110.02178 |
| 8 | VAN | Tsinghua | arxiv | https://arxiv.org/abs/2202.09741 |
1. Swin Transformer

swin transformer yes ICCV2021 The Mar prize ( Best paper ) Get work , Nature is needed by everyone CVer Respectful .swin The mechanism of self - attention in window is proposed , And through sliding window To achieve information transfer between windows . This avoids the original ViT Can't deal with dense Type output visual task ( Such as target detection 、 Segmentation, etc ) The problem of .ViT Overall situation self-attention The biggest problem with the computing model is that its number of calculations varies with token The quantity increases and the quadratic linearity increases , therefore ViT You can't turn an image into too many token, I can't cope with dense Output visual tasks , Second, it is not suitable to deal with high-resolution The input of .Swin The significance of the emergence of : Make pure vision transformer Can replace CNN Become general-purpose Basic mold , And achieve SOTA.swin Accelerated transformer Sweep up CV The speed of any corner .
Yes swin transformer Interested students may wish to further click me for swin Write a blog 《swin transformer Detailed explanation 》, Yes swin Every part of the was explained very clearly .
2. MLPMixer

MLPMixer It is undoubtedly a very Enlightening The article , In pure MLP That's it. ImageNet Of SOTA Level .MLPMixer Follow the network architecture ViT Very similar , Simply put self-attention Replace the module with transpose MLP.
I've done something about it inference The experiment of speed , It is found that this model is not suitable for project deployment , Not yet swin The speed of / Efficiency balance .
This article reminds me of a time AI The one I met in the competition was “ Only MLP” The team , In the end, they achieved good results . so , There is still a batch MLP Fans still insist MLP, They think that if you use the right MLP, impact SOTA It's enough . The meaning of this article is : It has inspired researchers to MLP Rethinking of the concept , Began to explore MLP stay CV In the field of “ correct ” usage .
3. DeiT

DeiT It is the first article that will distill (distillation) The introduction of ideas Vision Transformer The article . In itself ViT The training process has no effect on the utilization of data CNN So efficient . because CNN Naturally more interested in neighboring areas , and ViT The mechanism of self attention is global Of , therefore CNN In this case Inductive Bias It can greatly reduce the solution space . thus CNN It's usually better than ViT Convergence is faster , We can see a comparison chart :
Actually CNN In addition to than ViT Faster convergence ,CNN The requirements for data are lower . The original version of ViT It needs to be ImageNet-22k Only by pre training can we achieve SOTA, Only ImageNet-1k The training effect is not so good . Theoretically, with sufficient data ,transformer Than CNN Have greater potential , Because it jumped out local sex ; And when the data is not enough ,transformer In training, you will be better than CNN want “ stupid ” some . This is why this paper proposes use CNN When ViT Of teacher, In this way distillation, Give Way ViT While learning ground truth, On the other side CNN. such ,ViT Can achieve with CNN Same Data-efficient 了 . This approach , Give a lot ViT The discovery of development has guided the way , For example, the lightweight King mentioned later in this article LeViT Model .
4. ConvNext
ConvNext Is pure CNN impact swin Status model , Its appearance proves CNN old but still vigorous in mind and body . When ViT Sweep up CV Domain time , I saw the netizens on Zhihu self-attention The question of . Doubters believe :ViT A lot of new trick, Such as scribing (patchify),LN Instead of BN,GeLU Instead of ReLU wait , It's not just self-attention. If there is a CNN Model , Use the most popular Of trick, Whether it can reach or even exceed vision transformer Of SOTA?FAIR The researchers used ConvNext The experiment answers this question , The answer is yes .
ConvNext Mainly in the ResNet Improve on the basis of , Through some advanced trick To transform .ConvNext There is nothing new in itself trick, This is a comprehensive experiment . The picture above is enough to show ConvNext All the improvements in , It also shows the improvement of calculation after this improvement .
My local experiments have confirmed ,ConvNext Can really achieve Swin The level of , But the reasoning speed is slightly lower Swin.
5. SPACH
SPACH yes Spatial Channel Abbreviation .SPACH It has not put forward new trick, Instead, it proposes a framework . hold conv、MLP、self-attention All become in this framework “ Plug and play ” The components of , Weakened CNN and ViT The boundaries of .
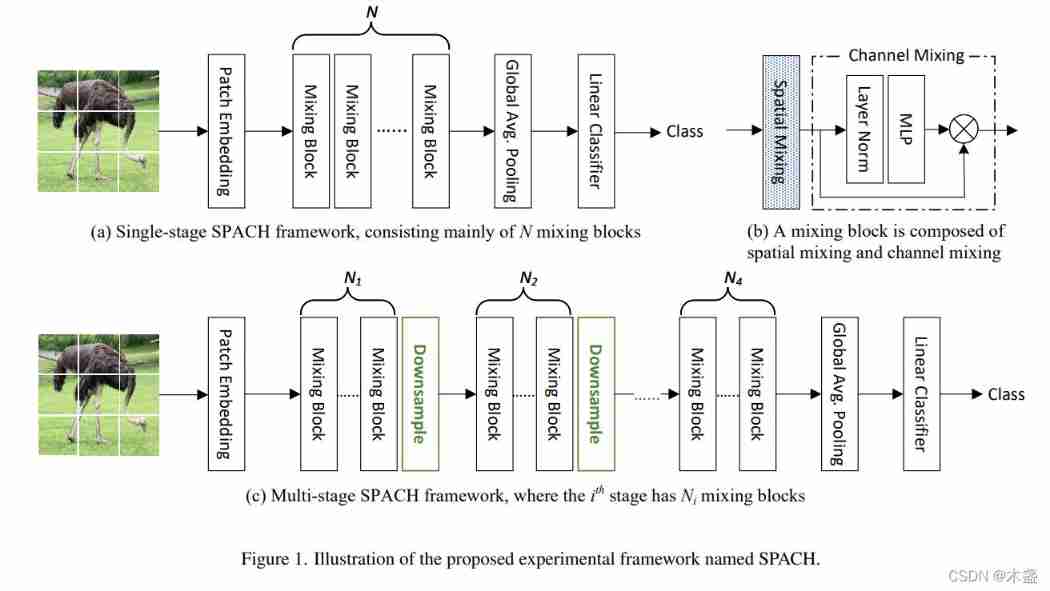
SPACH It is divided into single-stage and multi-stage frameworks , The multi-stage comes with a down sampling , It can quickly reduce the size of the feature map , This will speed up reasoning .
among ,Mixing Block That is SPACH Basic components , among Spatial Mixing The module can be replaced by one of the three :
SPACH Under mixed structure , The accuracy rate has also reached SOTA level , Its speed / The accuracy balance level is roughly the same as ConvNext almost .
Speed / Accuracy balance level refers to , Reach a certain point ImageNet Top1 Accuracy such as 80% The fastest reasoning speed that can be achieved .
6. LeViT
LeViT Is flaunting “ Lightweight ” Of ViT Model , Have the current ( By the end of 2022.2.22) Top speed / Accuracy balance level .LeViT The experiment also broke the lightweight model FLOPs and parameters A measure of number of references . Because many models have very low FLOPs And a small number of parameters , however inference The speed is not very high . Look at a picture :
The table shows ,EfficientNet B0 Than LeViT-128 There are fewer parameter Sum of numbers FLOPs, however CPU The speed of reasoning is only that of the latter 1/3. For project deployment ,inference speed Should be the most important reference index . therefore ,LeViT stay GPU, CPU, arm CPU Various experiments have been done on , Enough to prove that LeViT stay inference speed stay ImageNet top1 80% Accuracy is the fastest in the club !
LeViT In this paper, a dozen or so methods are proposed to accelerate and improve the ability of representation trick, I will write a blog to explain it later LeViT, I'll leave a hole here .
7. MobileViT
MobileViT Namely ViT Bounded MobileNet, It has been ICLR2022 Employment , It's also out of LeViT In addition to another flaunt “ Lightweight ” Of vision transformer Model . But limited by the lack of official open source code , I can't test it against LeViT Velocity contrast .MobileViT The data in the paper is still in the form of parameter Quantity as the main reference index . It was said that ,parameter Quantity is not the same as inference speed In a linear relationship .
We can see the picture above ,MobileViT Not to the original ViT Medium transformer Make any modifications to the module , It's about using Conv Instead of patchify, Then through a few MobileNet v2( It's also CNN) Module to reduce the size of the feature map .MV2 The modules are as follows :
The main contribution of this paper is to construct the downscaling structure of the inverted triangular characteristic graph , To ensure access transformer Medium token It won't be too much , So as to achieve the purpose of acceleration . This is also LeViT One of the techniques of . therefore , comparison MobileViT for ,LeViT Yes transformer The transformation of internal structure is more innovative and referential .
8. VAN(Visual Attention Network)
VAN yes “ Visual attention network ” Abbreviation , From Tsinghua University and Nankai University .VAN Combined with the self-attention and CNN The advantages of , It's also very Enlightening The article . First say CNN The shortcomings of : Pay more attention to adjacent areas , Lack of comprehensiveness . therefore CNN The theoretical effect of is not as good as the overall network structure ; Besides, self-attention The shortcomings of : Pay less attention to local sex , The training convergence is slow , Then it is not efficient enough for data .
For a global solution, there are two :self-attention and Large scale convolution kernel . The disadvantages of the former have been mentioned above , The disadvantage of the latter is that the amount of calculation is very large . So one of the core innovations of this paper is Decomposing large kernel convolution .
This decomposition is also called macronuclear attention (Large Kernel Attention), namely LKA. As shown in the figure above , A big one kernel size The convolution of is decomposed into a Depth-wise Convolution + One Depth-wise Cavity convolution + One 1 × \times × 1 Convolution . such , Can greatly reduce FLOPs And parameter quantities . It effectively solves the problem of small kernel convolution local sex .
Let's take a look at the comparison :
Formulate this LKA:
边栏推荐
- 疼痛分级为什么很重要?
- 数据库每日一题---第10天:组合两个表
- Mysql concat_ WS, concat function use
- China's alternative sports equipment market trend report, technology dynamic innovation and market forecast
- Configuring Dingding notification of SQL audit platform archery
- Research Report on water sports shoes industry - market status analysis and development prospect forecast
- How to develop programming learning with zero foundation during college
- iShot
- Have you really learned the common ancestor problem recently?
- JVM foundation - > three ⾊ mark
猜你喜欢

【Web技术】1348- 聊聊水印实现的几种方式

JVM foundation > CMS garbage collector
![[Part VI] source code analysis and application details of countdownlatch [key]](/img/6e/085e257c938a8c7b88c12c36df83e1.jpg)
[Part VI] source code analysis and application details of countdownlatch [key]

Configuring Dingding notification of SQL audit platform archery

Jin AI her power | impact tech, she can
![[Part 8] semaphore source code analysis and application details [key points]](/img/e2/05c08435d60564aaa1172d2d574675.jpg)
[Part 8] semaphore source code analysis and application details [key points]

Leetcode: the maximum number of building change requests that can be reached (if you see the amount of data, you should be mindless)

MySQL case when then function use

Redis optimization

Flutter series part: detailed explanation of GridView layout commonly used in flutter
随机推荐
How to abstract a problem into a 0-1 knapsack problem in dynamic programming
How to specify your webpage's language so Google Chrome doesn't offer to translate it
Implementation of master-slave replication and master-master replication for MySQL and MariaDB databases
Research Report on truffle fungus industry - market status analysis and development prospect forecast
设计消息队列存储消息数据的 MySQL 表格
leetcodeSQL:574. Elected
Mysql concat_ws、concat函数使用
【LeetCode】300. Longest ascending subsequence
JVM foundation > G1 garbage collector
Unity 常用3D数学计算
【LeetCode】209. 长度最小的子数组
JVM foundation - > talk about class loader two parent delegation model
Leetcode: the maximum number of building change requests that can be reached (if you see the amount of data, you should be mindless)
C#读取word中表格数据
Plusieurs camarades de classe de Tsinghua sont partis...
[web technology] 1348- talk about several ways to implement watermarking
How to develop programming learning with zero foundation during college
JVM Basics - > What are the JVM parameters?
JVM foundation - > what is STW?
Mysql concat_ WS, concat function use