当前位置:网站首页>Deep learning the principle of armv8/armv9 cache
Deep learning the principle of armv8/armv9 cache
2022-06-13 02:12:00 【Code changes the world CTW】
Quick links :
.
Personal blog notes guide Directory ( All )
Catalog
- 1、 Why use cache?
- 2、 background : Changes in Architecture ?
- 2、cache The hierarchy of –--big.LITTLE framework (A53 For example )
- 3、cache The hierarchy of –-- DynamIQ framework (A76 For example )
- 4、DSU / L3 cache
- 5、L1/L2/L3 cache How big are they
- 6、cache Related terms
- 7、cache The allocation strategy of (alocation,write-through, write-back)
- 8、 The type of memory in the schema
- 9、 As defined in the architecture cache The scope of the (inner, outer)
- 10、 The type of memory in the schema (mair_elx register )
- 11、cache The type of (VIVT,PIPT,VIPT)
- 12、Inclusive and exclusive caches
- 13、cache Query process of ( unofficial , vernacular )
- 14、cache The organizational form of (index, way, set)
- 15、cache line What's in it
- 16、cache Query examples
- 17、cache Query principle
- 18、cache maintenance
- 19、 Maintain memory consistency in software – invalid cache
- 20、 Maintain memory consistency in software – flush cache
- 21、cache Introduction to consistency directive
- 22、PoC/PoU point Introduce
- 23、cache A summary of the conformance directive
- 24、Kernel Use in cache Examples of consistency directives
- 25、Linux Kernel Cache API
- 26、A76 Of cache Introduce
- 27、A78 Of cache Introduce
- 28、armv8/armv9 Medium cache Related system registers
- 29、 Between multiple cores cache Uniformity
- 30、MESI/MOESI Introduction to
1、 Why use cache?
ARM At the beginning of architecture development , The clock speed of the processor is roughly similar to the access speed of the memory . Today's processor cores are much more complex , And the clock frequency can be several orders of magnitude faster . However , The frequency of external bus and storage device is not the same . It can be implemented on a small chip that can run at the same speed as the kernel SRAM block , But with standards DRAM Block comparison , such RAM It's very expensive , standard DRAM The capacity of blocks can be thousands of times higher . Based on many ARM Processor system , Accessing external memory requires dozens or even hundreds of kernel cycles .
A cache is a small, fast block of memory between the core and main memory . It keeps a copy of the project in main memory . Access to cache memory is much faster than access to main memory . Whenever the kernel reads or writes to a specific address , It first looks in the cache . If it finds an address in the cache , It uses the data in the cache , Instead of performing access to main memory . By reducing the impact of slow external memory access time , This significantly improves the potential performance of the system . By avoiding the need to drive external signals , It also reduces the power consumption of the system 
2、 background : Changes in Architecture ?

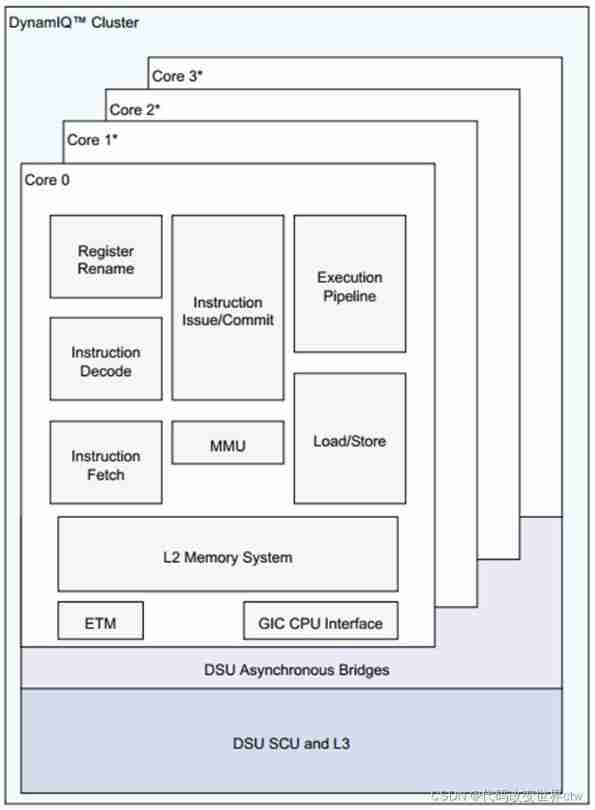
- DynamIQ yes Arm company 2017 New generation multi-core microarchitecture published in (microarchitecture) technology , The official name is DynamIQ big.LITTLE( Hereinafter referred to as DynamIQ), Replace the one that has been used for many years big.LITTLE technology
- big.LITTLE Technology will be multi-core processors IP Divided into two clusters, Every cluster most 4 A nuclear , Two cluster most 4+4=8 nucleus , and DynamIQ One of the cluster, Most support 8 A nuclear
- big.LITTLE Large and small nuclei must be placed in different places cluster, for example 4+4(4 Big nucleus +4 Micronucleus ),DynamIQ One of the cluster in , It can contain both large and small nuclei , achieve cluster Isomerism in (heterogeneous cluster), And large and small nuclei can be arranged and combined at will , for example 1+3、1+7 And other elastic configurations that could not be achieved before .
- big.LITTLE Every cluster Only one voltage can be used , And therefore the same cluster The core of the CPU There is only one frequency ,DynamIQ Every one of them CPU Cores can have different voltages and different frequencies
- big.LITTLE Every cluster Internal CPU nucleus , Share the same piece L2 Cache,DynamIQ Every one of them CPU The core , They all have their own L2 Cache, Share the same piece L3 Cache,L2 Cache and L3 Cache The capacity size of is optional , Exclusive to each core L2 Cache It can be downloaded from 256KB~512KB, All cores share L3 Cahce It can be downloaded from 1MB~4MB. This design greatly improves the speed of cross core data exchange . L3 Cache yes DynamIQ Shared Unit(DSU) Part of

2、cache The hierarchy of ––big.LITTLE framework (A53 For example )


3、cache The hierarchy of –-- DynamIQ framework (A76 For example )

4、DSU / L3 cache
DSU-AE The system control register is realized , These register pairs cluster All in core It's all universal . It can be downloaded from cluster Any of them core Access these registers . These registers provide :
- control cluster Power management for .
- L3 cache control .
- CHI QoS Bus control and scheme ID Distribute .
- of DSU‑AE Hardware configuration information , Including the designated Split‑Lock Cluster execution mode .
- L3 Cache hit and miss count information
L3 cache
- cache size Optional : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
- 1.5MB Of cache 12 Road groups are connected
- 512KB, 1MB, 2MB, and 4MB Of caches 16 Road groups are connected
5、L1/L2/L3 cache How big are they
Need reference ARM file , In fact, every one core Of cache The size is fixed or configurable .
6、cache Related terms
reflection : What is? Set、way、TAG 、index、cache line、entry?
7、cache The allocation strategy of (alocation,write-through, write-back)
Read allocation (read allocation)
When CPU When reading data , happen cache defect , In this case, a cache line Cache data read from main memory . By default ,cache Both support read allocation .Read allocation (read allocation) Write assignments (write allocation)
When CPU Write data occurs cache When missing , Will consider the write allocation strategy . When we do not support write allocation , The write instruction will only update the main memory data , And then it's over . When write allocation is supported , We first load data from main memory into cache line in ( It's like doing a read assignment first ), And then it updates cache line Data in .Write straight through (write through)
When CPU perform store Command and in cache Hit, , We update cache And update the data in main memory .cache Always keep consistent with the data in main memory .Read allocation (read allocation) Write back to (write back)
When CPU perform store Command and in cache Hit, , We only update cache Data in . And each cache line There will be one bit Whether the bit record data has been modified , be called dirty bit( Turn over the front picture ,cache line There's one next to it D Namely dirty bit). We will dirty bit Set up . The data in main memory will only be in cache line Replaced or displayed clean Update during operation . therefore , The data in main memory may be unmodified data , And the modified data lies cache in .cache The data may be inconsistent with the main memory

8、 The type of memory in the schema

9、 As defined in the architecture cache The scope of the (inner, outer)
about cacheable attribute ,inner and outer Describe the cache Definition or classification of . For example L1/L1 As a inner, hold L3 As a outer
Usually , Internally integrated cache Belong to inner cache, External bus AMBA Upper cache Belong to outer cache. for example :
- For the above mentioned big.LITTLE framework (A53 For example ) in ,L1/L2 Belong to inner cache, If SOC Hang up L3 Words , Then it belongs to outer cache
- For the above mentioned DynamIQ framework (A76 For example ) in ,L1/L2/L3 Belong to inner cache, If SOC Hang up System cache( Or some other name ) Words , Then it belongs to outer cache
And then we can do it for each kind of cache Separate attribute configuration , for example :
- To configure inner Non-cacheable 、 To configure inner Write-Through Cacheable 、 To configure inner Write-back Cacheable
- To configure outer Non-cacheable 、 To configure outer Write-Through Cacheable 、 To configure outer Write-back Cacheable

about shareable attribute ,inner and outer Describe the cache The scope of the . such as inner Refer to L1/L2 Within the scope of cache,outer Refer to L1/L2/L3 Within the scope of cache

The following is again true of Inner/Outer Attributes make a small summary :

If you will block The memory property of is configured as Non-cacheable, Then the data will not be cached to cache, So all observer The memory you see is consistent , In other words, it is equivalent to Outer Shareable.
In fact, official documents , There is also a description of this sentence :
stay B2.7.2 chapter “Data accesses to memory locations are coherent for all observers in the system, and correspondingly are treated as being Outer Shareable”If you will block The memory property of is configured as write-through cacheable or write-back cacheable, Then the data will be cached cache in .write-through and write-back Cache policy .
If you will block The memory property of is configured as non-shareable, that core0 When accessing this memory , Cached data to Core0 Of L1 d-cache and cluster0 Of L2 cache, It will not be cached to other cache in
If you will block The memory property of is configured as inner-shareable, that core0 When accessing this memory , The data will only be cached to core 0 and core 1 Of L1 d-cache in , It will also be cached to clustor0 Of L2 cache, Not cached to clustor1 Any of them cache in .
If you will block The memory property of is configured as outer-shareable, that core0 When accessing this memory , The data will be cached to all cache in
| Non-cacheable | write-through cacheable | write-back cacheable | |
|---|---|---|---|
| non-shareable | Data will not be cached to cache ( For observation , And it's equivalent to outer-shareable) | Core0 When reading , Cached data to Core0 Of L1 d-cache and cluster0 Of L2 cache, If core0 and core1 Both read and write the memory , And in core0 core1 Of L1 d-cache The memory is cached in . that core0 While reading the data ,core0 Of L1 Dcache Will update , but core 1 Of L1 Dcache Will not update | Same as left |
| inner-shareable | Data will not be cached to cache ( For observation , And it's equivalent to outer-shareable) | Core0 When reading , Cached data to Cluster0 All in cache | Same as left |
| outer-shareable | Data will not be cached to cache ( For observation , And it's equivalent to outer-shareable) | Core0 When reading , Data cache to all cache | Same as left |
10、 The type of memory in the schema (mair_elx register )

11、cache The type of (VIVT,PIPT,VIPT)
MMU from TLB and Address Translation form :
- Translation Lookaside Buffer
- TAddress Translation
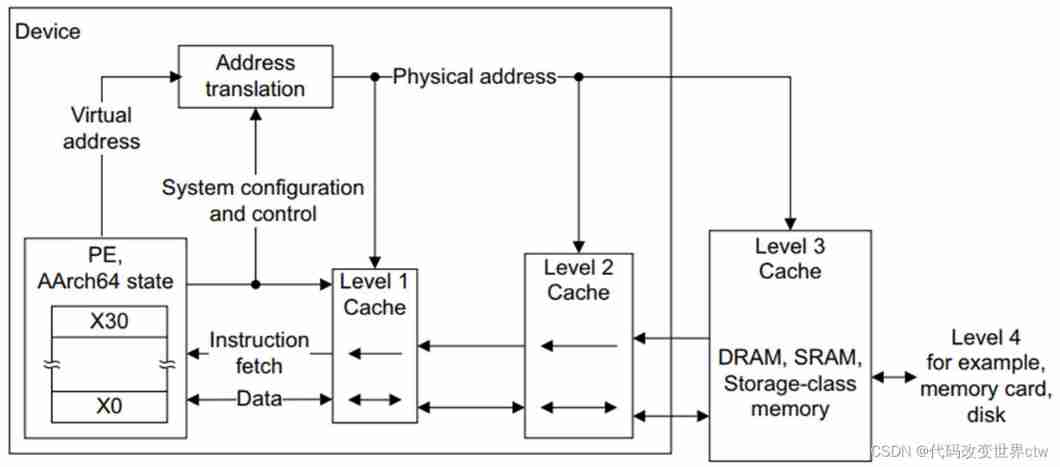
cache It is divided into ;
- PIPT
- VIVT
- VIPT
12、Inclusive and exclusive caches

Let's start with a simple memory read , Single core . Such as LDR X0, [X1], hypothesis X1 Point to main memory, And is cacheable.
(1)、Core Go first L1 cache Read ,hit 了 , Directly return data to Core
(2)、Core Go first L1 cache Read ,miss 了 , Then it will query L2 cache,hit 了 ,L2 Of cache The data will return Core, It will also lead to this cache line Replace the L1 One of the lines cache line
(3)、 If L1 L2 All are miss, that data Will read from memory , The cache to L1 and L2, And return it to Core
Then we look at a complex system , Don't consider L3, Multicore .
(1)、 If it is inclusive cache, Then the data will be cached to L1 and L2
(2)、 If it is exclusive cache, Then the data is only cached to L1, Not cached to L2
- Strictly inclusive: Any cache line present in an L1 cache will also be present in the L2
- Weakly inclusive: Cache line will be allocated in L1 and L2 on a miss, but can later be evicted from L2
- Fully exclusive: Any cache line present in an L1 cache will not be present in the L2
13、cache Query process of ( unofficial , vernacular )

Suppose a 4 Road connected cache, size 64KB, cache line = 64bytes, that 1 way = 16KB,indexs = 16KB / 64bytes = 256 ( notes : 0x4000 = 16KB、0x40 = 64 bytes)
0x4000 – index 0
0x4040 – index 1
0x4080 – index 2
…
0x7fc0 – index 2550x8000 – index 0
0x8040 – index 1
0x8080 – index 2
…
0xbfc0 – index 255
14、cache The organizational form of (index, way, set)

- All connected
- Direct connection
- 4 Road groups are connected

for example A76
L1 i-cache :64KB,4 road 256 Groups connected ,cache line by 64bytes
TLB i-cache : All connected , Support 4KB, 16KB, 64KB, 2MB,32M Page of
L1 d-cache :64KB,4 road 256 Groups connected ,cache line position 64bytes
TLB d-cache : All connected , Support 4KB, 16KB, 64KB, 2MB,512MB Page of
L2 cache :8 Road connected cache, Size optional 128KB, 256KB, or 512KB
15、cache line What's in it

Each line in the cache includes:
• A tag value from the associated Physical Address.
• Valid bits to indicate whether the line exists in the cache, that is whether the tag is valid.
Valid bits can also be state bits for MESI state if the cache is coherent across multiple cores.
• Dirty data bits to indicate whether the data in the cache line is not coherent with external memory
• data

that TAG What's in it ??(S13 Would say here TAG Is equal to... In the physical address TAG)
As follows A78 For example , It shows TAG What's in it

add :TLB What's in it ? Also think A78 For example ;

16、cache Query examples

17、cache Query principle
First use index Go to query cache, Then compare TAG, Compare tag It will also be checked when valid Sign a 
18、cache maintenance

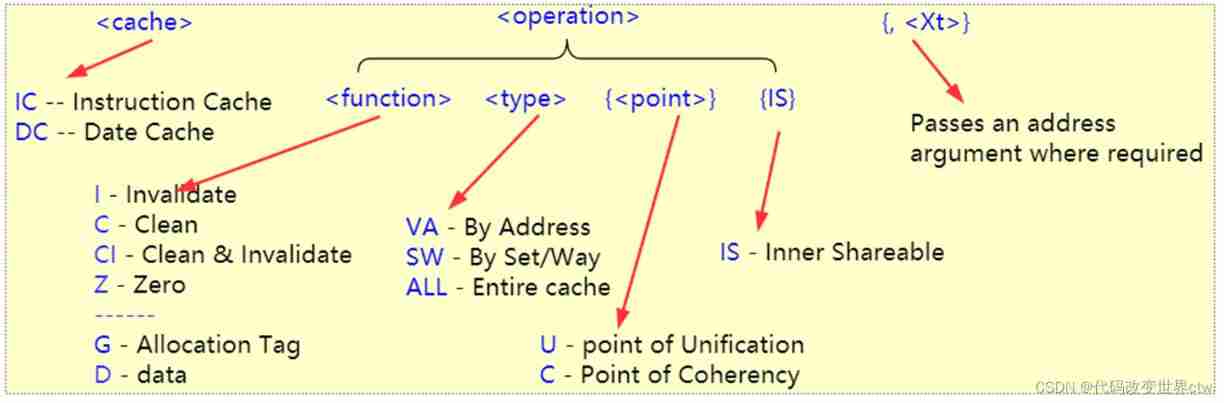
Software maintenance operation cache There are three types of instructions :
- Invalidation: In fact, it's modification valid bit, Give Way cache Invalid , Mainly used to read
- Cleaning: In fact, it's what we call flush cache, Here will be cache Data is written back to memory , And clearly dirty sign
- Zero: take cache The data in 0, This is actually what we call clean cache.
When software maintenance is needed cache:
(1)、 When there are others Master Changed external memory, Such as DMA operation
(2)、MMU Of enable or disable Memory access for the entire interval of , Such as REE enable 了 mmu,TEE disable 了 mmu.
For (2) spot ,cache How and mmu It's related ? That's because :
mmu On and off , Affect the memory permissions, cache policies
19、 Maintain memory consistency in software – invalid cache

20、 Maintain memory consistency in software – flush cache

21、cache Introduction to consistency directive
<cache> <operation>{, <Xt>}

22、PoC/PoU point Introduce

- PoC is the point at which all observers, for example, cores, DSPs, or DMA engines, that can access memory, are guaranteed to see the same copy of a memory location
- PoU for a core is the point at which the instruction and data caches and translation table walks of the core are guaranteed to see the same copy of a memory location
23、cache A summary of the conformance directive
24、Kernel Use in cache Examples of consistency directives

25、Linux Kernel Cache API
linux/arch/arm64/mm/cache.S
linux/arch/arm64/include/asm/cacheflush.h
void __flush_icache_range(unsigned long start, unsigned long end);
int invalidate_icache_range(unsigned long start, unsigned long end);
void __flush_dcache_area(void *addr, size_t len);
void __inval_dcache_area(void *addr, size_t len);
void __clean_dcache_area_poc(void *addr, size_t len);
void __clean_dcache_area_pop(void *addr, size_t len);
void __clean_dcache_area_pou(void *addr, size_t len);
long __flush_cache_user_range(unsigned long start, unsigned long end);
void sync_icache_aliases(void *kaddr, unsigned long len);
void flush_icache_range(unsigned long start, unsigned long end)
void __flush_icache_all(void)
26、A76 Of cache Introduce
A76
L1 i-cache :64KB,4 road 256 Groups connected ,cache line by 64bytes
L1 d-cache :64KB,4 road 256 Groups connected ,cache line by 64bytes
L2 cache :8 Road connected cache, Size optional 128KB, 256KB, or 512KB
L1 TLB i-cache :48 entries, All connected , Support 4KB, 16KB, 64KB, 2MB,32M Page of
L1 TLB d-cache : 48 entries, All connected , Support 4KB, 16KB, 64KB, 2MB,512MB Page of
L2 TLB cache : 1280 entries, 5 Road groups are connected
L3 cache
cache size Optional : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
1.5MB Of cache 12 Road groups are connected
512KB, 1MB, 2MB, and 4MB Of caches 16 Road groups are connected

27、A78 Of cache Introduce
A78
L1 i-cache :32 or 64KB,4 Road groups are connected ,cache line by 64bytes , VIPT
L1 d-cache : 32 or 64KB,4 Road groups are connected ,cache line by 64bytes, VIPT
L1 TLB i-cache :32 entries, All connected , Support 4KB, 16KB, 64KB, 2MB,32M Page of
L1 TLB d-cache : 32 entries, All connected , Support 4KB, 16KB, 64KB, 2MB,512MB Page of
L2 TLB cache : 1024 entries, 4 Road groups are connected
L3 cache
cache size Optional : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
1.5MB Of cache 12 Road groups are connected
512KB, 1MB, 2MB, and 4MB Of caches 16 Road groups are connected
28、armv8/armv9 Medium cache Related system registers
ID Register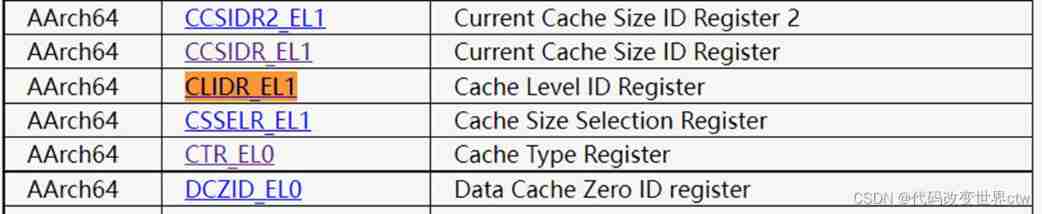
CTR_EL0, Cache Type Register
- IminLine, bits [3:0]
Log2 of the number of words in the smallest cache line of all the instruction caches that are controlled by the PE. - DminLine, bits [19:16]
Log2 of the number of words in the smallest cache line of all the data caches and unified caches that are controlled by the PE
29、 Between multiple cores cache Uniformity
about Big.LITTLE framework 
about DynamIQ framework

30、MESI/MOESI Introduction to


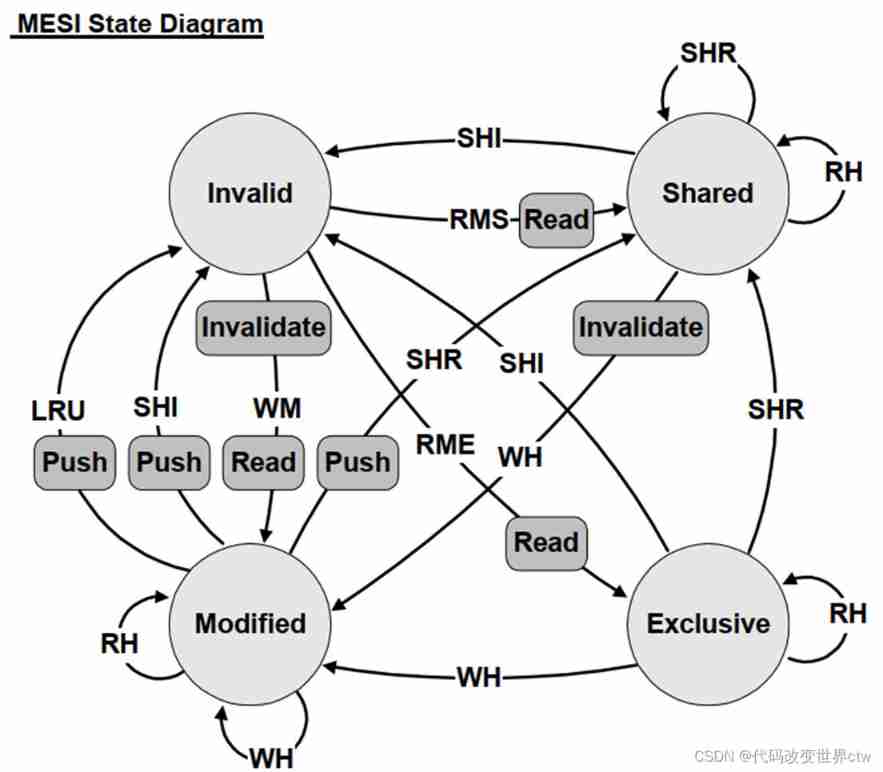
Events:
- RH = Read Hit
- RMS = Read miss, shared
- RME = Read miss, exclusive
- WH = Write hit
- WM = Write miss
- SHR = Snoop hit on read
- SHI = Snoop hit on invalidate
- LRU = LRU replacement
Bus Transactions:
- Push = Write cache line back to memory
- Invalidate = Broadcast invalidate
- Read = Read cache line from memory
Welcome to add wechat 、 Wechat group , Communicate more

边栏推荐
- QT realizes mind mapping function (II)
- SQL Server 删除数据库所有表和所有存储过程
- Mac使用Docker安装Oracle
- Installing Oracle with docker for Mac
- [the fourth day of actual combat of stm32f401ret6 smart lock project in 10 days] voice control is realized by externally interrupted keys
- Padavan mounts SMB sharing and compiles ffmpeg
- Ctrip reshapes new Ctrip
- 拍拍贷母公司信也季报图解:营收24亿 净利5.3亿同比降10%
- [programming idea] communication interface of data transmission and decoupling design of communication protocol
- json,xml,txt
猜你喜欢

Alertwindowmanager pop up prompt window help (Part 1)

In addition to the full screen without holes under the screen, the Red Devils 7 series also has these black technologies

传感器:SHT30温湿度传感器检测环境温湿度实验(底部附代码)

Mac使用Docker安装Oracle

Yovo3 and yovo3 tiny structure diagram

ROS learning-8 pit for custom action programming

华为设备配置双反射器优化虚拟专用网骨干层

Why is "iFLYTEK Super Brain 2030 plan" more worthy of expectation than "pure" virtual human
Vscode configuration header file -- Take opencv and its own header file as an example

Looking at Qianxin's "wild prospect" of network security from the 2021 annual performance report
随机推荐
Swiper horizontal rotation grid
华为设备配置虚拟专用网FRR
Build MySQL environment under mac
16 embedded C language interview questions (Classic)
Day 1 of the 10 day smart lock project (understand the SCM stm32f401ret6 and C language foundation)
C语言压缩字符串保存到二进制文件,从二进制文件读取压缩字符串后解压。
STM32 sensorless brushless motor drive
Decoding iFLYTEK open platform 2.0 is a fertile land for developers and a source of industrial innovation
ROS learning-7 error in custom message or service reference header file
STM32F103 IIC OLED program migration complete engineering code
Répertoire d'exclusion du transport rsync
[the 4th day of the 10 day smart lock project based on stm32f401ret6] what is interrupt, interrupt service function, system tick timer
Application and routine of C language typedef struct
Solution of depth learning for 3D anisotropic images
Detailed explanation of C language conditional compilation
What did Hello travel do right for 500million users in five years?
蓝牙模块:使用问题集锦
Ctrip reshapes new Ctrip
Ruixing coffee 2022, extricating itself from difficulties and ushering in a smooth path
1000粉丝啦~