在我们之前的文章中,我们讨论了多模式索引的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能。在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制的设计,类似于 PostgreSQL 和 MySQL 等流行的数据库系统,它支持索引构建而不会阻塞写入。
背景
Apache Hudi 将事务和更新/删除/更改流添加到弹性云存储和开放文件格式之上的表中。 Hudi 内部的一个关键组件是事务数据库内核,它协调对 Hudi 表的读取和写入。索引是该内核的最新子系统。所有索引都存储在内部 Hudi Merge-On-Read (MOR) 表中,即元数据表在事务上与数据表保持同步,即使在出现故障时也是如此。元数据表也被构建为由 Hudi 的表服务自行管理,就像数据表一样。
动机
而Hudi目前支持三种索引;文件、column_stats 和bloom_filter,大数据的数量和种类使得添加更多索引以进一步降低I/O 成本和查询延迟势在必行。建立新索引的一种方法是停止所有写入程序,然后在元数据表内建立一个新的索引分区,然后恢复写入程序。随着我们添加更多索引,这可能并不理想,因为,a)它需要停机,b)它不会随着更多索引而扩展。因此,需要在与写入并发的表上动态添加和删除索引。异步索引有两个好处,改进写入延迟和解耦故障。对于那些熟悉数据库系统中的“CREATE INDEX”的人来说会了解创建索引是多么容易,而不用担心持续的写入。将异步索引添加到 Hudi 丰富的表服务集是尝试为 Lakehouse 带来类似数据库的易用性、可靠性和性能。
设计
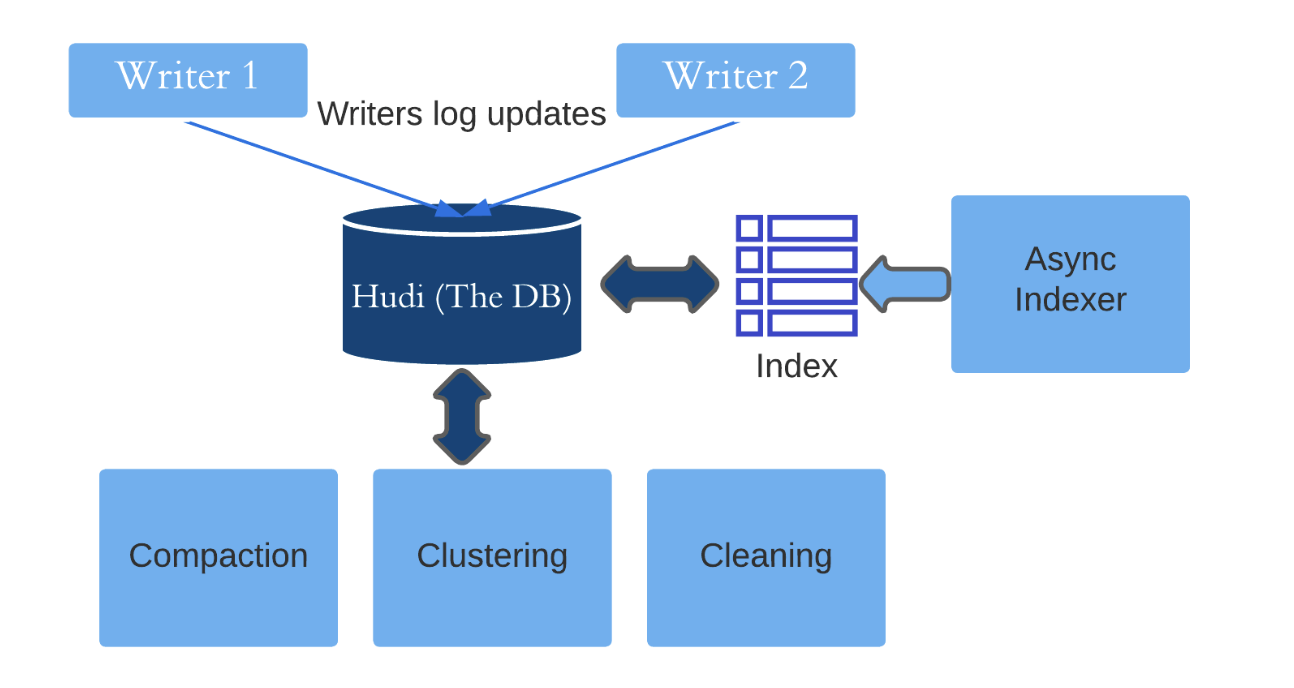
与正在进行的写入进行异步索引的核心是确保这些写入可以对索引执行一致的更新,即使历史数据正在后台被索引。处理这个问题的一种方法是完全锁定索引分区,直到历史数据被索引然后赶上。然而,冲突的可能性只会随着长时间运行的事务的锁定而增加。这个问题的解决依赖于 Hudi 事务内核设计的三个支柱:
Hudi 文件布局
Hudi 表中的数据文件被组织成文件组,其中每个文件组包含多个文件切片。每个切片都包含一个在特定提交时生成的基本文件,以及一组包含对基本文件的更新的日志文件。这使得我们将在下一节中看到细粒度的并发控制成为可能。初始化文件组并写入基本文件后,另一个写入器可以记录对同一文件组的更新,并且将创建一个新切片。
混合并发控制
异步索引混合使用乐观并发控制和基于日志的并发控制模型。索引分为两个阶段:调度和执行。
在调度过程中,索引器(负责创建新索引的外部进程)获取一个短锁,并为数据文件生成一个索引计划,直到最后一个提交时刻 t。它初始化与请求的索引对应的元数据分区,并在此阶段完成后释放锁。这应该需要几秒钟,并且在此阶段不会写入任何索引文件。
在执行期间,索引器执行计划,将索引基础文件(对应于直到瞬间 t 的数据文件)写入元数据分区。同时,常规的正在进行的写入继续将更新记录到与元数据分区中的基本文件相同的文件组中的日志文件。编写基本文件后,索引器会检查 t 之后的所有已完成提交instant,以确保它们中的每一个都根据其索引计划添加条目,否则只是优雅地中止。这是当乐观并发控制启动时,使用元数据表锁来检查写入者是否影响了重叠文件,如果存在冲突,则中止,优雅中止确保可以以幂等方式重试索引。
Hudi时间线
Hudi 维护了在不同时刻在表上执行的所有操作的时间表。将其视为事件日志,作为进程间协调的核心部分。 Hudi 在时间轴上实现了细粒度的基于日志的并发协议。为了将索引与其他写入操作区分开来,我们在此时间线上引入了一个名为“索引”的新操作。此操作的状态转换由索引器处理。调度索引会在时间线中添加一个“indexing.requested” instant。执行阶段在执行计划时将其转换为“inflight”状态,然后在索引完成后最终转换为“completed”状态。索引器仅在向时间线添加事件时锁定,而不是在写入索引文件时锁定。
这种设计的优点如下:
- 数据写入和索引是分离的,但它们彼此了解。
- 它可以扩展到其他类型的索引。
- 它适用于批处理和流式工作负载。
使用时间线作为事件日志,两种并发模型的混合提供了出色的可扩展性和异步性,以便索引过程与写入器与其他表服务(如compaction和clustering)同时运行。
文档
有关索引器的设计和实现的更多详细信息,请查看 RFC-45。要设置并查看运行中的索引器,请遵循异步索引指南。
未来的工作
异步索引功能是 Lakehouse 架构中的首创,仍在不断发展。虽然可以与写入器同时创建索引,但删除索引需要表级锁定,因为表通常会被其他读取器/写入器线程使用。因此,一项工作是通过延迟删除索引并增加异步量来克服当前的限制,以便可以同时创建或删除多个索引。另一项工作是增强索引器的可用性;与 SQL 和其他类型的索引集成,例如二级键的Bloom索引,基于Lucene的二级索引(RFC-52)等。我们欢迎社区更多的想法和贡献。
结论
Hudi 的多模式索引和异步索引功能表明,事务数据湖不仅仅是表格格式和元数据。分布式存储系统的基本原理也适用于 Lakehouse 架构,并且挑战出现在不同的规模上。这种规模的异步索引很快就会成为必需品。我们讨论了一种可扩展到其他索引类型、可扩展和非阻塞的设计,并将继续在此框架的基础上为索引子系统添加更多功能。
![[STM32] solution to the problem that SWD cannot recognize devices after STM32 burning program](/img/03/41bb3870b9a6c2ee66099abac08eb3.png)