当前位置:网站首页>【數據挖掘】視覺模式挖掘:Hog特征+餘弦相似度/k-means聚類
【數據挖掘】視覺模式挖掘:Hog特征+餘弦相似度/k-means聚類
2022-07-07 15:04:00 【zstar-_】
1. 實驗概述
本次實驗使用的是VOC2012數據集,首先從圖像中隨機采樣圖像塊,然後利用Hog方法提取圖像塊特征,最後采用餘弦相似度和k-means聚類兩種方法來挖掘視覺模式。
2. 數據集說明
本次實驗使用VOC2012數據集。VOC2012數據集常用於目標檢測、圖像分割、網絡對比實驗和模型效果評價。對於圖像分割任務,VOC2012的訓練驗證集包含了2007-2011年的所有對應圖像,包含有2913張圖片和6929個目標,測試集只包含了2008-2011年。
由於該數據集多用於目標檢測等任務中,因此在本次實驗中,僅使用到該數據集中的8類數據。
數據集下載鏈接:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
3. 算法模型介紹
3.1 Hog特征提取
方向梯度直方圖(Histogram of Oriented Gradient, HOG)特征是一種在計算機視覺和圖像處理中用來進行物體檢測的特征描述子。它通過計算和統計圖像局部區域的梯度方向直方圖來構成特征,它的主要步驟如下:
- 灰度化
將圖片進行灰度化,濾除無關顏色信息。 - 顏色空間的標准化
采用Gamma校正法對輸入圖像進行顏色空間的標准化,可以調節圖像的對比度,降低圖像局部的陰影和光照變化所造成的影響,同時可以抑制噪音的幹擾。 - 梯度計算
計算圖像每個像素的梯度(包括大小和方向),可以捕獲輪廓信息,同時進一步弱化光照的幹擾。 - Cell劃分
將圖像劃分成小cells,以8x8大小的Cell為例,如圖所示:
- 統計每個cell的梯度直方圖
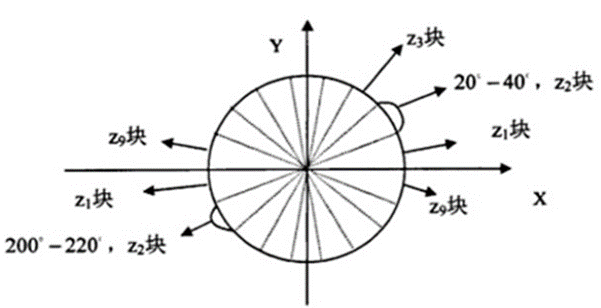
如圖所示,將360°劃分成18份,每一份角度為20°。同時,不考慮方向大小,即總共為9份角度類別,統計每個類別的頻度。 - 將每幾個cell組成一個block
以2x2大小的block為例,如圖所示:
圖中的藍色框錶示一個cell,黃色框錶示一個block,將2x2個cell組成為一個block,同時在每個block內將梯度直方圖進行歸一化。歸一化的方法主要有四種:
原論文中說明L2-Hys的方法效果最好[1],因此在本實驗中,歸一化方法也使用L2-Hys。 - 移動block
將每個block以cell為間隔在水平和垂直兩個方向上進行移動,最終串聯所有特征向量得到圖像塊的Hog特征。
3.2 餘弦相似度
得到每個圖像塊的Hog特征之後,通過計算每個圖像塊特征向量的餘弦相似性來進行類別的劃分,餘弦相似度的計算公式如下: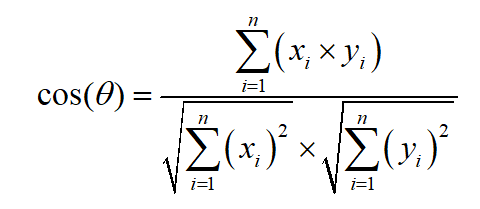
3.3 K-means聚類
得到每個圖像塊的Hog特征後,還可使用K-means聚類的方式來進行視覺模式的挖掘。K-means聚類的過程如圖所示: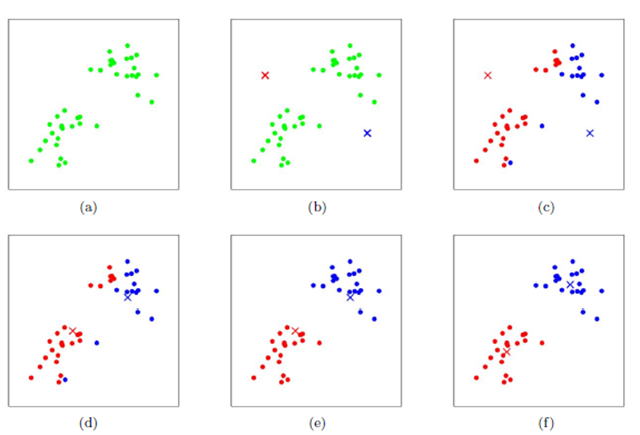
首先隨機初始化兩個點作為聚類中心,計算每個點到聚類中心的距離,並聚類到離該點最近的聚類中去。之後,計算每個聚類中所有點的坐標平均值,並將這個平均值作為新的聚類中心;重複上述兩個步驟,直到每個類的聚類中心不再變化,完成聚類。
4. 頻繁性和判別性評價指標
4.1 頻繁性評價指標
若一個圖案多次出現在正類圖像中,則稱其具有頻繁性。在本實驗中,頻繁性的評價指標參考了王倩楠等人[2]的評價標准,定義頻繁性公式如下: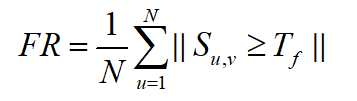
式中,N錶示某一類樣本的總數, S u , v S_{u,v} Su,v錶示該類中樣本u和樣本v的餘弦相似度, T f T_f Tf錶示閾值。
4.2 判別性評價指標
如果一個模式值出現在正類圖像中,而不是在負類圖像中,則稱其為具有判別性。在本次實驗中,使用視覺模式的平均分類精度來定義判別性,公式如下:
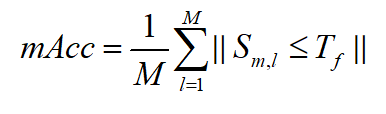
式中,M錶示樣本類別總數, S m , l S_{m,l} Sm,l錶示類中樣本視覺模式平均值m和樣本v的餘弦相似度, T f T_f Tf錶示閾值。
5. 實驗步驟
5.1 數據集類別劃分
本次實驗采用的VOC2012數據集,並沒有按類別將圖片進行歸類。因此首先需要根據類別,將包含該類別的圖片進行劃分。這裏總共使用7個類別:“車、馬、猫、狗、鳥、羊、牛”。
執行劃分的核心代碼如下:
def get_my_classes(Annotations_path, image_path, save_img_path, classes):
xml_path = os.listdir(Annotations_path)
for i in classes:
if not os.path.exists(save_img_path+"/"+i):
os.mkdir(save_img_path+i)
for xmls in xml_path:
print(Annotations_path+"/"+xmls)
in_file = open(os.path.join(Annotations_path, xmls))
print(in_file)
tree = ET.parse(in_file)
root = tree.getroot()
if len(set(root.iter('object'))) != 1:
continue
for obj in root.iter('object'):
cls_name = obj.find('name').text
print(cls_name)
try:
shutil.copy(image_path+"/"+xmls[:-3]+"jpg", save_img_path+"/"+cls_name+"/"+xmls[:-3]+"jpg")
except:
continue
代碼執行之後的結果如下:
5.2 圖像塊采樣
為了采樣圖像塊,本實驗中選用了隨機裁剪的方式。以每張圖像的中心點為基准,在[-圖片長寬/6,圖片長寬/6]的限定範圍內進行中心點偏移,從而獲得采樣圖像塊,采樣過程如圖所示: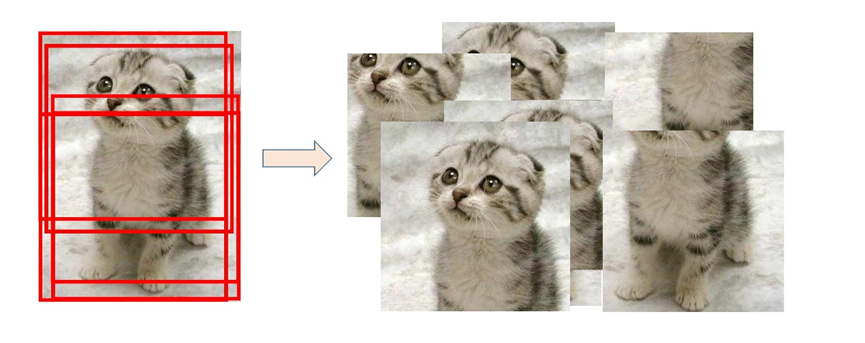
對於每張圖像,共隨機采樣得到10個采樣塊,核心代碼如下:
for each_image in os.listdir(IMAGE_INPUT_PATH):
# 每個圖像全路徑
image_input_fullname = IMAGE_INPUT_PATH + "/" + each_image
# 利用PIL庫打開每一張圖像
img = Image.open(image_input_fullname)
# 定義裁剪圖片左、上、右、下的像素坐標
x_max = img.size[0]
y_max = img.size[1]
mid_point_x = int(x_max/2)
mid_point_y = int(y_max/2)
for i in range(0, 10):
# 中心點隨機偏移
crop_x = mid_point_x + \
random.randint(int(-mid_point_x/3), int(mid_point_x/3))
crop_y = mid_point_y + \
random.randint(int(-mid_point_y/3), int(mid_point_y/3))
dis_x = x_max-crop_x
dis_y = y_max-crop_y
dis_min = min(dis_x, dis_y, crop_x, crop_y) # 獲取變動範圍
down = crop_y + dis_min
up = crop_y - dis_min
right = crop_x + dis_min
left = crop_x - dis_min
BOX_LEFT, BOX_UP, BOX_RIGHT, BOX_DOWN = left, up, right, down
# 從原始圖像返回一個矩形區域,區域是一個4元組定義左上右下像素坐標
box = (BOX_LEFT, BOX_UP, BOX_RIGHT, BOX_DOWN)
# 進行roi裁剪
roi_area = img.crop(box)
# 裁剪後每個圖像的路徑+名稱
image_output_fullname = IMAGE_OUTPUT_PATH + \
"/" + str(i) + "_" + each_image
# 存儲裁剪得到的圖像
roi_area.save(image_output_fullname)
5.3 Hog特征提取
對每個圖像塊,調整其尺寸為256x256,並進行歸一化,提取其Hog特征,核心代碼如下:
# 圖片預處理
def preprocessing(src):
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) # 將圖像轉換成灰度圖
img = cv2.resize(gray, (256, 256)) # 尺寸調整g
img = img/255.0 # 數據歸一化
return img
# 提取hog特征
def extract_hog_features(X):
image_descriptors = []
for i in range(len(X)):
''' 參數解釋: orientations:方向數 pixels_per_cell:胞元大小 cells_per_block:塊大小 block_norm:可選塊歸一化方法L2-Hys(L2範數) '''
fd, _ = hog(X[i], orientations=9, pixels_per_cell=(
16, 16), cells_per_block=(16, 16), block_norm='L2-Hys')
image_descriptors.append(fd) # 拼接得到所有圖像的hog特征
return image_descriptors # 返回的是訓練部分所有圖像的hog特征
這裏的cell大小選擇為(16,16),block大小為(16,16)。
5.4 通過餘弦相似度進行挖掘
根據所有圖像塊的Hog特征,利用頻繁性和判別性的標准來進行計算,核心代碼如下:
threshold = 0.6
group1 = []
group2 = []
group1.append(X_features[0])
for i in range(1, len(X_features)):
res = cosine_similarity(X_features[0].reshape(1, -1), X_features[i].reshape(1, -1))
if res > threshold:
group1.append(X_features[i])
else:
group2.append(X_features[i])
根據文獻[2]的經驗,這裏的閾值分別選用了0.6,0.7,0.8,實驗結果見下一節。
5.5 通過k-means聚類方法進行挖掘
在本實驗中,也采用另一種方式即k-means聚類的方式來挖掘的視覺模式,核心代碼如下:
cluster = KMeans(n_clusters=2, random_state=0)
y = cluster.fit_predict(X_features)
colors = ['blue', 'red']
plt.figure()
for i in range(len(y)):
plt.scatter(X_features[i][0], X_features[i][1], color=colors[y[i]])
plt.title("前兩個維度聚類錶示")
plt.savefig("cluster.png")
plt.show()
以“羊”作為頻繁性的挖掘類別,將挖掘出的正類和負類樣本前兩個維度可視化錶示如下: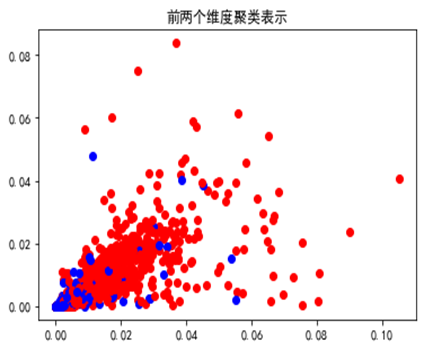
提取出具有頻繁性的視覺模式後,對判別性的挖掘,仍采用餘弦相似度的方式,結果見下一節。
6. 實驗結果
本次實驗選擇的類別是“羊”(sheep),並采用了兩種方法以及不同的餘弦相似度閾值,其數值結果如下錶所示:
| 閾值 | 頻繁性 |
|---|---|
| 0.6 | 0.623 |
| 0.7 | 0.863 |
| 0.8 | 0.999 |
可以發現,隨著閾值的增大,挖掘出的視覺模式頻繁性越大。
| 閾值 | car | horse | cat | dog | bird | cow | 平均判別性 |
|---|---|---|---|---|---|---|---|
| 0.6 | 0.887 | 0.291 | 0.315 | 0.258 | 0.489 | 0.144 | 0.397 |
| 0.7 | 0.957 | 0.513 | 0.64 | 0.567 | 0.708 | 0.382 | 0.628 |
| 0.8 | 0.988 | 0.791 | 0.914 | 0.841 | 0.873 | 0.716 | 0.854 |
相類似,隨著閾值的增大,挖掘出的視覺模式判別性也越大,當閾值取值為0.8時,最高的平均判別性為0.854。
將該方法挖掘出的視覺模式,可視化部分如下:

在本實驗中還采用了K-means聚類的方式來挖掘視覺模式,得到的頻繁性數值為0.707,對於判別性的計算,仍采用餘弦相似度的方式,其結果如下錶所示:
| 閾值 | car | horse | cat | dog | bird | cow | 平均判別性 |
|---|---|---|---|---|---|---|---|
| 0.6 | 0.883 | 0.26 | 0.299 | 0.242 | 0.493 | 0.146 | 0.387 |
| 0.7 | 0.956 | 0.503 | 0.632 | 0.569 | 0.713 | 0.391 | 0.627 |
| 0.8 | 0.987 | 0.793 | 0.91 | 0.843 | 0.879 | 0.724 | 0.856 |
和前一種方法相類似,隨著閾值的增大,挖掘出的視覺模式判別性也越大,當閾值取值為0.8時,最高的平均判別性為0.856。
將該方法挖掘出的視覺模式,可視化部分如下:
由圖可見,雖然兩個方法挖掘出的視覺模式數值上差异性不大,但可視化結果卻有差异。餘弦相似度方法挖掘出的視覺模式更多在於羊的面部特征,而K-means聚類挖掘出的視覺模式更多在於羊的身體特征。
7. 實驗總結
本次實驗,使用了傳統的Hog特征提取方式,並使用餘弦相似度和K-means聚類的方式來挖掘視覺模式。通過本實驗,可以發現某一類圖片的視覺模式可能不只一種,在本實驗中,未考慮多種視覺模式的情况。針對此類情况,采用基於密度的聚類方式[2]可能會更加適合。
此外,對於視覺模式的挖掘,諸如Hog、Sift等傳統特征提取方式,錶征能力不强,不具有抽象能力。使用類似CNN的神經網絡是目前更加主流且有效的方式。
參考文獻
[1] N Dalal, B Triggs. Histograms of Oriented Gradients for Human Detection [J]. IEEE Computer Society Conference on Computer Vision & Pattern Recognition, 2005, 1(12): 886-893.
[2] 王倩楠. 基於深度學習的視覺模式挖掘算法研究[D].西安電子科技大學,2021.DOI:10.27389/d.cnki.gxadu.2021.002631.
完整源碼
實驗報告+源碼:
鏈接:https://pan.baidu.com/s/131RbDp_LNGhmEaFREvgFdA?pwd=8888
提取碼:8888
边栏推荐
- WebRTC 音频抗弱网技术(上)
- Ascend 910 realizes tensorflow1.15 to realize the Minist handwritten digit recognition of lenet network
- Niuke real problem programming - Day9
- Ctfshow, information collection: web7
- 【深度学习】图像超分实验:SRCNN/FSRCNN
- [Yugong series] go teaching course 005 variables in July 2022
- Cocoscreator resource encryption and decryption
- CTFshow,信息搜集:web3
- Pandora IOT development board learning (HAL Library) - Experiment 12 RTC real-time clock experiment (learning notes)
- Delete a whole page in word
猜你喜欢
Ctfshow, information collection: web1
asp.netNBA信息管理系统VS开发sqlserver数据库web结构c#编程计算机网页源码项目详细设计

CTFshow,信息搜集:web9

上半年晋升 P8 成功,还买了别墅!

Five pain points for big companies to open source
Niuke real problem programming - day13
Ctfshow, information collection: web9

Ctfshow, information collection: web4

Guangzhou Development Zone enables geographical indication products to help rural revitalization
Niuke real problem programming - day16
随机推荐
With 8 modules and 40 thinking models, you can break the shackles of thinking and meet the thinking needs of different stages and scenes of your work. Collect it quickly and learn it slowly
Five pain points for big companies to open source
Discussion on CPU and chiplet Technology
"July 2022" Wukong editor update record
【服务器数据恢复】某品牌StorageWorks服务器raid数据恢复案例
Niuke real problem programming - day15
2022 cloud consulting technology series high availability special sharing meeting
防火墙基础之服务器区的防护策略
Simple steps for modifying IP of sigang electronic scale
《微信小程序-进阶篇》组件封装-Icon组件的实现(一)
Stream learning notes
IDA pro逆向工具寻找socket server的IP和port
15、文本编辑工具VIM使用
Ctfshow, information collection: web12
Several ways of JS jump link
电脑Win7系统桌面图标太大怎么调小
Summer safety is very important! Emergency safety education enters kindergarten
CTFshow,信息搜集:web10
word中删除一整页
一文读懂数仓中的pg_stat