当前位置:网站首页>时空可变形卷积用于压缩视频质量增强(STDF)
时空可变形卷积用于压缩视频质量增强(STDF)
2022-07-07 12:45:00 【mytzs123】
Spatio-Temporal Deformable Convolution for Compressed Video Quality Enhancement
Abstract
近年来,深度学习方法在提高压缩视频质量方面取得了显著的成功。为了更好地探索时间信息,现有方法通常估计光流以进行时间运动补偿。然而,由于压缩视频可能会因各种压缩伪影而严重失真,因此估计的光流往往不准确和不可靠,从而导致质量增强无效。此外,连续帧的光流估计通常以成对方式进行,这是计算成本高且效率低的。在本文中,我们提出了一种快速而有效的压缩视频质量增强方法,通过合并一种新的时空可变形融合(STDF)方案来聚集时间信息。具体来说,该STDF将目标帧及其相邻参考帧作为输入,共同预测偏移场以使卷积的时空采样位置变形。因此,可以在单个时空可变形卷积(STDC)操作中融合来自目标帧和参考帧的互补信息。大量实验表明,我们的方法在准确性和效率方面都达到了压缩视频质量增强的最先进性能。
1 Introduction
如今,视频内容已成为数字网络流量的主要部分,并且仍在增长(Wien 2015)。为了在有限的带宽下传输视频,视频压缩对于显著降低比特率至关重要。然而,压缩算法,如H.264/AVC(Wiegand等人,2003)和H.265/HEVC(Sullivan,Ohm和Wiegand 2013),通常会在压缩视频中引入各种伪影,尤其是在低比特率下。如图1所示,此类伪影可能会显著降低视频质量,导致体验质量(QoE)下降。低质量压缩视频中的失真内容也可能会降低低带宽应用中后续视觉任务(例如识别、检测、跟踪)的性能(Galteri等人,2017年;Lu等人,2019年)。因此,对压缩视频质量增强(VQE)的研究至关重要。

在过去的几十年里,人们对单个压缩图像的伪影去除或质量增强进行了大量的研究。传统方法(Foi、Katkovink和Egiazarian 2007;Zhang等人,2013)通过优化特定压缩标准的变换系数来减少伪影,因此很难扩展到其他压缩方案。随着卷积神经网络(CNN)的最新进展,基于CNN的图像质量增强方法(董等人,2015;泰等人,2017;张等人,2017;2019)也出现了。他们通常学习非线性映射,从大量训练数据中直接回归无伪影图像,从而高效地获得令人印象深刻的结果。然而,这些方法不能直接扩展到压缩视频,因为它们独立处理帧,因此无法利用时间信息。
另一方面,对压缩视频质量增强的研究还很有限。杨等人。首次提出了多帧质量增强(MFQE 1.0)方法,以利用时间信息进行矢量量化。具体来说,利用压缩视频中的高质量帧作为参考帧,通过一种新的多帧CNN(MF-CNN)帮助提高相邻低质量目标帧的质量。最近,引入了升级版MFQE 2.0(Guan等人,2019),以进一步提高MF-CNN的效率,实现最先进的性能。为了聚集来自目标帧和参考帧的信息,两种MFQE方法都采用了广泛使用的时间融合方案,该方案采用了密集光流进行运动补偿(Kappeler等人,2016;Caballero等人,2017;Xue等人,2017)。然而,这种时间融合方案在矢量量化环境任务中可能是次优的。由于压缩伪影可能会严重扭曲视频内容并破坏帧之间的像素对应,因此估计的光流往往不准确和不可靠,从而导致质量增强无效。此外,需要以成对的方式对不同的参考目标帧对重复执行光流估计,这涉及到大幅增加计算成本以探索更多参考帧。
为了解决上述问题,我们介绍了一种用于矢量量化环境任务的时空可变形融合(STDF)方案。具体来说,我们提出学习一种新的时空可变形卷积(STDC)来聚集时间信息,同时避免显式光流估计。STDC的主要思想是自适应地使卷积的时空采样位置变形,以捕获最相关的上下文并排除噪声内容,从而提高目标帧的质量。为此,我们采用基于CNN的预测器来联合建模目标和参考帧之间的对应,并相应地在单个推理过程中回归这些采样位置。本文的主要贡献总结如下:
我们提出了一种基于端到端CNN的VQE任务方法,该方法结合了一种新的STDF方案来聚合时间信息;我们通过分析和实验将提出的STDF与先验融合方案进行了比较,并证明了其更高的灵活性和鲁棒性;我们在VQE基准数据集上对该方法进行了定量和定性评估,结果表明,该方法在准确性和效率方面达到了最先进的性能。
2 Related Work
Image and Video Quality Enhancement:在过去的十年中,越来越多的作品关注于压缩图像的质量增强。其中,基于CNN的端到端方法取得了近期最先进的性能。具体来说,Dong等人首先引入了一种4层AR-CNN来去除各种JPEG压缩伪影。后来,Zhang等人成功地学习了一个非常深的DnCNN,并针对多个图像恢复任务使用了残差学习方案。最近,Zhang等人提出了一种更深的网络RNAN,它具有残差非局部注意机制,可以捕获像素之间的长依赖关系,并建立了一种新的图像质量增强技术。这些方法倾向于使用大型的cnn来捕获图像中的特征,从而导致大量的计算和参数。另一方面,mfqe1.0率先应用多帧CNN来利用时间信息进行压缩视频质量增强,其中高质量帧用于帮助增强相邻低质量帧的质量。为了利用长距离时间信息,Yang等人后来引入了一种改进的卷积长-短期记忆网络,用于视频质量增强。最近,Guan等人提出了MFQE2.0,以升级MFQE1.0的几个关键组件,并在准确性和速度方面取得了最先进的性能。
Leveraging Temporal Information:在视频相关任务中,跨多个帧利用互补信息至关重要。Karpathy等人首先介绍了几种基于卷积的融合方案,以结合时空信息进行视频分类(Karpathy等人,2014)。Kappeler等人后来研究了这些用于低水平视觉任务的融合方案(Kappeler等人,2016),并通过使用基于全变差(TV)的光流估计算法补偿连续帧之间的运动来提高精度。Caballero等人进一步用CNN取代了基于TV的流量估计器,以实现端到端训练(Caballero等人,2017年)。自那时以来,具有运动补偿的时间融合已被广泛用于各种视觉任务(薛等人2017;杨等人2018;金等人2018;关等人2019)。然而,这些方法严重依赖于精确的光流,由于一般问题(例如遮挡、大运动)或任务特定问题(例如压缩伪影),很难获得精确的光流。为了解决这个问题,已经进行了绕过显式光流估计的工作。Niklaus、Mai和Liu提出了AdaConv(Niklaus、Mai和Liu 2017),通过隐式利用运动线索进行视频帧插值来自适应生成卷积核。Shi等人介绍了ConvLSTM网络,以利用来自长范围相邻帧的上下文信息(Shi等人,2015)。在这项工作中,我们提出将运动线索与卷积相结合,以有效地聚集时空信息,这也省略了光流的显式估计
Deformable Convolution:Dai等人首次提出用可学习的采样偏移量来增强规则卷积,从而为目标检测建模复杂的几何变换。后来,一些作品将其沿时间范围进行扩展,以隐式捕获视频相关应用的运动线索,并取得了比传统方法更好的性能。然而,这些方法以成对的方式执行可变形卷积,因此无法完全探索跨多个帧的时间对应。在这项工作中,我们提出了STDC来共同考虑一个视频片段,而不是将其分割成多个参考目标帧对,从而更有效地利用上下文信息。
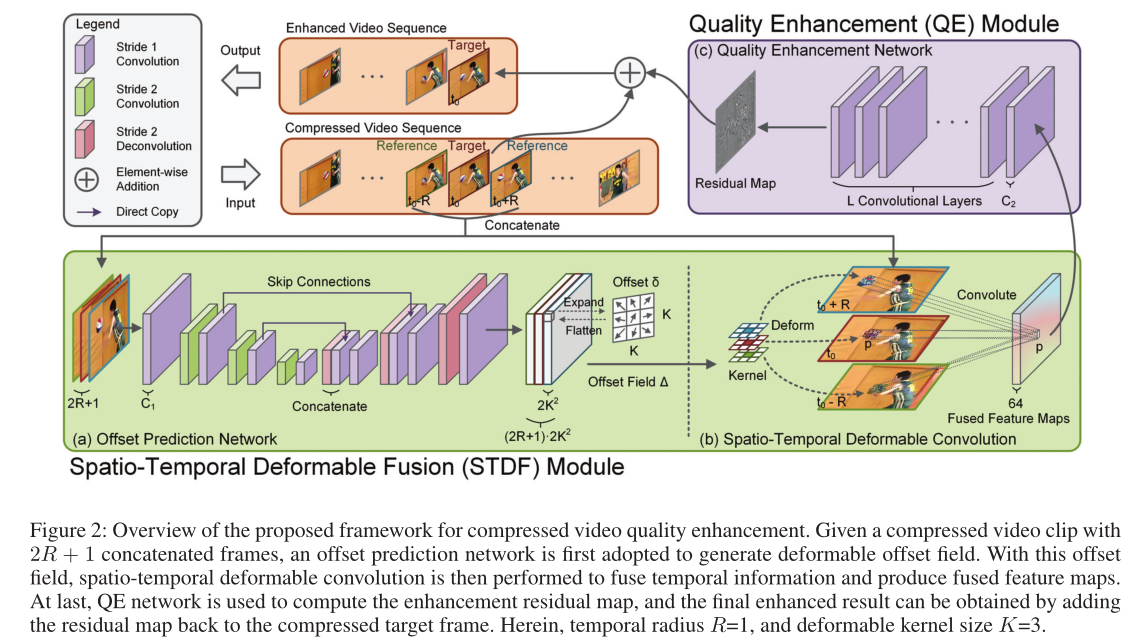
3 Proposed Method
3.1 Overview
假设压缩视频因压缩伪影而失真,我们方法的目标是消除这些伪影,从而提高视频质量。具体来说,我们分别对每个压缩帧 在
在 时进行增强。为了利用时间信息,我们将前后的R帧作为参考,以帮助提高每个目标的质量。增强结果
时进行增强。为了利用时间信息,我们将前后的R帧作为参考,以帮助提高每个目标的质量。增强结果 可以表示为:
可以表示为:
图2展示了我们方法的框架,该框架由时空可变形融合(STDF)模块和质量增强(QE)模块组成。STDF模块将目标帧和参考帧作为输入,并通过时空可变形卷积融合上下文信息,其中可变形偏移由偏移预测网络自适应生成。然后,通过融合的特征映射,QE模块结合了一个完全卷积增强网络来计算增强结果。由于STDF模块和QE模块都是卷积的,因此可以以端到端的方式训练我们的统一框架。
3.2 STDF Module
Spatio-Temporal Deformable Convolution: 对于压缩视频剪辑 最直接的时间融合方案,即早期融合(EF),可以表示为直接应用于压缩帧的多信道卷积,如下所示:
最直接的时间融合方案,即早期融合(EF),可以表示为直接应用于压缩帧的多信道卷积,如下所示:

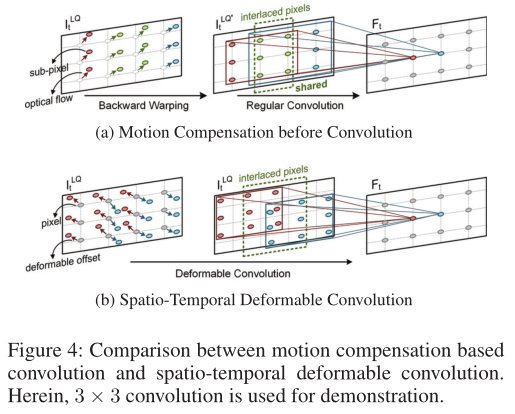
其中F是得到的特征映射,K表示卷积核的大小, 是卷积核的第t个通道,p表示任意空间位置,pk表示规则采样偏移量。例如,pk∈ {(−1,−1),(−1,0),····,(1,1)}对于K=3。尽管效率很高,但EF很容易引入噪声内容,并由于时间运动而降低后续增强的性能,如图3所示。受Dai等人的启发,为了解决这个问题,我们引入了一种新的时空可变形卷积(STDC)算法,用额外的可学习偏移量
是卷积核的第t个通道,p表示任意空间位置,pk表示规则采样偏移量。例如,pk∈ {(−1,−1),(−1,0),····,(1,1)}对于K=3。尽管效率很高,但EF很容易引入噪声内容,并由于时间运动而降低后续增强的性能,如图3所示。受Dai等人的启发,为了解决这个问题,我们引入了一种新的时空可变形卷积(STDC)算法,用额外的可学习偏移量 来增强规则采样偏移量:
来增强规则采样偏移量:
![]()
值得注意的是,可变形偏移δ(t、 p)是位置特定的,即被分配给以时空位置(t,p)为中心的每个卷积窗口的δ(t、 p)都是独特的。因此,视频片段中的空间变形和时间动态可以同时建模,如图3所示。由于可学习的偏移可以是分数,因此我们遵循Dai等人将可微双线性插值应用于采样亚像素
与以往的VQE方法不同,在融合前进行显式运动补偿以减轻时间运动的影响,STDC在融合时隐式地将运动线索与位置特定采样相结合。这导致了更高的灵活性和健壮性,因为相邻的卷积窗口可以独立地对内容进行采样,如图4所示。
Joint Deformable Offset Prediction:
与一次只处理一个参考帧对的光流估计不同,我们提出了一种将整个剪辑考虑在内,同时联合预测所有可变形偏移量的方法。为此,对于视频剪辑中的所有时空位置,我们应用偏移量预测网
预测偏移场 用于视频片段中的所有时空位置,如:
用于视频片段中的所有时空位置,如:
![]()
其中帧连接在一起作为输入。由于连续帧高度相关,因此一帧的偏移预测可以受益于其他帧,从而比成对方案更有效地利用时间信息。此外,联合预测的计算效率更高,因为所有可变形偏移量都可以在单个推理过程中获得。
如图2-(a)所示,我们采用基于U-Net的网络(Ronneberger、Fischer和Brox 2015)进行偏移量预测,以扩大感受野,从而捕获大的时间动态。步长为2的卷积层和反卷积层(Zeiler和Fergus 2014)分别用于下采样和上采样。对于步长为1的卷积层,采用零填充来保持特征尺寸。为简单起见,我们设置所有的卷积层的卷积核数量为C1。除了最后一个之后是线性激活以回归偏移场Δ,校正线性单元(ReLU)是所有层的激活函数. 我们在网络中不使用任何规范化层。
3.3 QE Module
QE模块的主要思想是充分挖掘融合特征映射F中的互补信息,从而生成增强的目标帧。为了利用残差学习(Kim、Lee和Lee 2016),我们首先学习非线性映射 以预测增强残差
以预测增强残差
如图2-(c)所示,我们通过另一个由步长1的L卷积层组成的CNN来实现。除最后一层外,所有层都具有C2卷积滤波器,然后是ReLU激活。最后一个卷积层输出增强残差。这种简单的QE网络在没有铃声和哨声的情况下,能够获得令人满意的增强效果。
3.4 Training Scheme
由于STDF模块和QE模块是完全卷积的,因此是可微的,因此我们以端到端的方式联合优化 和
和 。将总损耗函数L设置为增强目标帧
。将总损耗函数L设置为增强目标帧 和原始目标帧
和原始目标帧 之间的平方误差之和(SSE),如下所示:
之间的平方误差之和(SSE),如下所示:
![]()
注意,由于不存在可变形偏移的 ground-truth,偏移预测网络的学习 是完全无监督的,完全由最终损耗L驱动,这不同于以前的工作(Yang等人2018;Guan等人2019),这些工作包含了辅助损耗来约束光流估计。
是完全无监督的,完全由最终损耗L驱动,这不同于以前的工作(Yang等人2018;Guan等人2019),这些工作包含了辅助损耗来约束光流估计。
4 Experiments
4.1 Datasets
遵循MFQE 2.0(Guan等人,2019),我们从两个数据库(Xiph.org)和VGEG(VGEG))收集了130个具有不同分辨率和内容的未压缩视频,其中106个用于训练,其余用于验证。为了测试,我们采用了来自视频编码联合协作团队(Ohm等人,2012)的数据集,其中包含18个未压缩视频。这些测试视频广泛用于视频质量评估,每个视频约450帧。我们使用最新的H.265\/HEVC参考软件HM16.5 2在低延迟P(LDP)配置下压缩上述所有视频,与之前的工作一样(Guan等人,2019)。压缩是在在4个不同的量化参数(QP),即22、27、32、37,以评估不同压缩级别下的性能。
4.2 Implementation Details
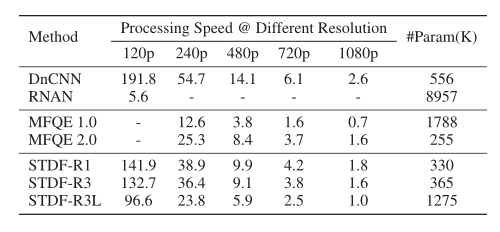
该方法基于Pytork框架,参考MMDetection工具箱(Chen等人,2019)实现可变形卷积。对于训练,我们从原始视频和相应的压缩视频中随机裁剪64×64个片段作为训练样本。进一步使用数据增强(即旋转或翻转)来更好地利用这些训练样本。我们使用Adam optimizer(Kingma和Ba 2014)训练所有模型,β1=0.9,β2=0.999和 =1e−8、学习率最初设置为10−4并在整个培训过程中保留。我们从零开始分别为4个QP训练4个模型。对于评估,与之前的工作一样,我们仅在YUV /YCbCr空间中的Y通道(即亮度分量)上应用质量增强。我们采用增量峰值信噪比(ΔPSNR)和结构相似性(ΔSSIM)(Wang等人,2004)来评估质量增强性能,这衡量了增强视频相对于压缩视频的改善程度。我们还从参数和计算成本方面评估了质量增强方法的复杂性。
=1e−8、学习率最初设置为10−4并在整个培训过程中保留。我们从零开始分别为4个QP训练4个模型。对于评估,与之前的工作一样,我们仅在YUV /YCbCr空间中的Y通道(即亮度分量)上应用质量增强。我们采用增量峰值信噪比(ΔPSNR)和结构相似性(ΔSSIM)(Wang等人,2004)来评估质量增强性能,这衡量了增强视频相对于压缩视频的改善程度。我们还从参数和计算成本方面评估了质量增强方法的复杂性。
4.3 Comparison to State-of-the-arts
我们将提出的方法与最先进的图像/视频质量增强方法、AR-CNN(Dong等人,2015)、DnCNN(Zhang等人,2017)、RNAN(Zhang)进行了比较等,2019),MFQE 1.0(杨等,2018)和MFQE 2.0(关等,2019)。为了公平比较,所有图像质量增强方法都在我们的训练集上重新训练。视频质量增强方法的结果引用自(Guan等人,2019)。我们评估了具有不同配置的方法的三种变体(有关详细信息,请参阅上一节)。1) STDF-R1,R=1,C1=32,C2=48,L=8。2) STDF-R3,R=3,C1=32,C2=48,L=8。3) STDF-R3L,R=3,C1=64,C2=64,L=16。
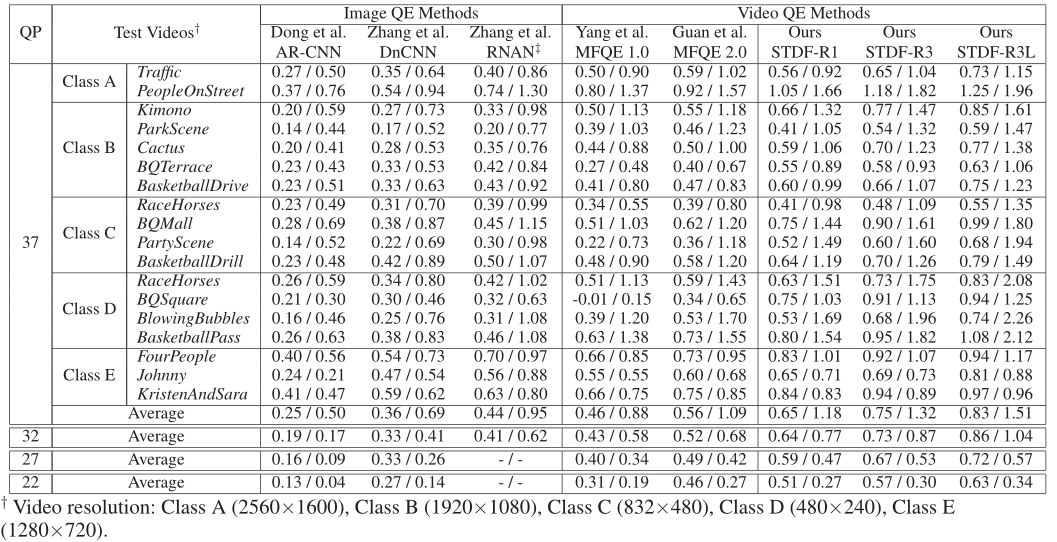
Quantitative Results:表1和表2分别给出了精度和模型复杂度的定量结果。可以观察到,我们的方法在18个测试视频上始终优于所有比较的方法的平均ΔPSNR和ΔSSIM。更具体地说,在QP37,我们的STDF-R1优于mfqe2.0对大多数视频,并且拥有更快的处理速度和差不多的参数。我们注意到,我们的STDF-R1只是将前面和后面的帧作为参考,不像mfqe2.0使用高质量的相邻帧,从而节省了预先搜索那些高质量帧的计算成本。随着时间半径R增加到3,我们的STDF-R3设法利用更多的时间信息,从而进一步提高平均值ΔPSNR为0.75db,比mfqe2.0高34%,比mfqe1.0高63%,比RNAN高70%。由于所提出的STDF模块的高效率,STDF-R3的总体速度仍然比mfqe2.0快。此外,扩容后的STDF-R3L的ΔPSNR达到0.83db,表明该方法仍有改进的空间。类似的结果可以在ΔSSIM以及其他QP。
Qualitative Results:图5提供了4个测试视频的定性结果。可以看出,压缩后的帧由于各种压缩伪影(ringing in Kimono and blurring in F ourPeople)而严重失真,虽然图像质量增强方法可以适当地减少这些伪影,但是生成的帧通常会变得过于模糊和缺乏细节。另一方面,视频质量增强方法在参考帧的帮助下实现了更好的增强效果。与MFQE 2.0相比,我们的STDF模型对压缩伪影更具鲁棒性,可以更好地探索时空信息,从而更好地恢复结构细节。
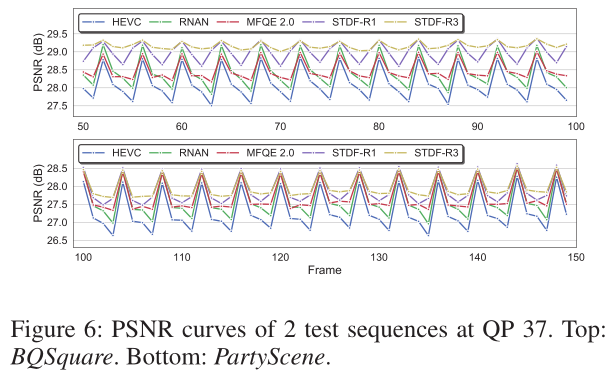
Quality Fluctuation:据观察,压缩视频中存在显著的质量波动(Guan等人,2019年),这可能会严重破坏时间一致性并降低QoE。为了研究我们的方法如何帮助实现这一点,我们在图6中绘制了2个序列的峰值信噪比曲线。可以看出,我们的STDF-R1模型可以有效增强大多数低质量帧,并缓解质量波动。通过将时间半径R扩大到3,我们的STDF-R3模型能够利用相邻的高质量帧,从而获得比其他比较方法更好的性能。
4.4 Analysis and Discussions
在本节中,我们进行了消融研究和进一步的分析。为了公平比较,我们只对融合方案进行了消融实验,并将QE网络固定为L=8,C2=48,所有模型都按照相同的协议和规则进行训练ΔPSNR/ΔSSIM在qp37对从B类到E类的所有测试视频进行平均。使用在480p视频上计算的浮点运算(FLOPs)来评估计算成本。
Effectiveness of STDF :
为了证明STDF对时间融合的有效性,我们将其与之前的两种融合方案进行了比较,即早期融合(EF)和早期运动补偿融合(EFMC)。具体来说,对于EFMC方案,我们选择了两个基于CNN的光流估计器进行运动补偿。1) EF_STMC,MFQE 2.0中使用的轻型空间变压器运动补偿(STMC)网络。2) EF_FlowNetS,FlowNet中使用的较大网络。我们在不同的时间半径R下训练模型来评估可伸缩性。
图7显示了比较结果。我们可以观察到,所有参考帧的方法都优于单帧baseline,证明了使用时间信息的有效性。当R=1时,STDF在ΔPSNR性能上显著优于EF和EFMC且计算量相当,说明STDF可以更好地利用时间信息。随着R的进一步增加,有趣的是ΔEF-STMC的峰值信噪比反而下降,EF-FlowNetS的峰值信噪比仅略有提高。我们认为原因是双重的。首先,光流估计器很难捕捉到长时间间隔的运动,这导致了附加参考帧的无效使用。其次,不同运动强度的训练样本可能会使光流估计器产生混淆,特别是对于容量相对较低的EF-STMC。相比之下,所提出的STDF考虑了整个视频片段,迫使偏移预测网络同时学习不同强度的运动。因此,STDF的ΔPSNR随着R的增加而不断提高。此外,随着R的增加,STDF的计算增长的速度比EF-STMC和EF-FlowNetS慢得多,说明STDF的效率更高。
Effectiveness of STDC:
所提出的STDC具有特定于位置的采样特性,比传统的运动补偿融合方法具有更高的灵活性和鲁棒性。为了验证这一点,我们引入了一种方法的变体,用EFMC替换STDC。具体地说,EFMC中的光流估计器是从偏移预测网络修改而来的,其中网络的输出层被修改为用于流估计而不是偏移预测。根据表3,虽然用EFMC代替STDC时参数和 FLOPs略有改善,但总体上R=1和R=3时的ΔPSNR分别下降0.04 dB和0.08 dB。这证明了所提出的STDC的有效性
Effectiveness of Joint Offset Prediction:
提出了一种联合预测方法来生成STDC的可变形偏移量。为了证明其有效性,我们将其替换为成对预测方案。具体地说,我们修改了偏移预测网络的输入层和输出层,分别对每个参考目标对进行偏移预测。从表3我们可以看出ΔPSNR和ΔSSIM采用两两方案的联合预测方案在减少的同时,大大提高了FLOPs,表明该联合预测方案能够更好地利用时间信息,具有较高的效率。
5 Conclusion
我们提出了一种快速有效的压缩视频质量增强方法,该方法结合了一种新的时空可变形卷积来聚集连续帧的时间信息。在基准数据集上,我们的方法在准确性和效率方面都优于以前的方法。我们相信,所提出的时空可变形卷积也可以扩展到其他与视频相关的低级视觉任务,包括超分辨率、恢复和帧合成,以实现高效的时间信息融合
边栏推荐
- PAG experience: complete AE dynamic deployment and launch all platforms in ten minutes!
- Pert diagram (engineering network diagram)
- Leetcode——344. 反转字符串/541. 反转字符串 II/151. 颠倒字符串中的单词/剑指 Offer 58 - II. 左旋转字符串
- 内部排序——插入排序
- Substance painter notes: settings for multi display and multi-resolution displays
- Million data document access of course design
- PD虚拟机教程:如何在ParallelsDesktop虚拟机中设置可使用的快捷键?
- Excuse me, does PTS have a good plan for database pressure measurement?
- Oracle Linux 9.0 正式发布
- JSON解析实例(Qt含源码)
猜你喜欢

Docker deploy Oracle
Computer win7 system desktop icon is too large, how to turn it down

2022pagc Golden Sail award | rongyun won the "outstanding product technology service provider of the year"

小米的芯片自研之路
Leetcode one question per day (636. exclusive time of functions)
Substance Painter筆記:多顯示器且多分辨率顯示器時的設置
多商戶商城系統功能拆解01講-產品架構
Notes de l'imprimante substance: paramètres pour les affichages Multi - écrans et multi - Résolutions
AWS学习笔记(三)
【历史上的今天】7 月 7 日:C# 发布;Chrome OS 问世;《仙剑奇侠传》发行
随机推荐
PyTorch模型训练实战技巧,突破速度瓶颈
回归测试的分类
STM32CubeMX,68套组件,遵循10条开源协议
【愚公系列】2022年7月 Go教学课程 005-变量
Substance painter notes: settings for multi display and multi-resolution displays
Huawei cloud database DDS products are deeply enabled
Ascend 910实现Tensorflow1.15实现LeNet网络的minist手写数字识别
2022云顾问技术系列之高可用专场分享会
UML state diagram
2022pagc Golden Sail award | rongyun won the "outstanding product technology service provider of the year"
MLGO:Google AI发布工业级编译器优化机器学习框架
LeetCode每日一题(636. Exclusive Time of Functions)
LeetCode 648. 单词替换
[Yugong series] go teaching course 005 variables in July 2022
EfficientNet模型的完整细节
Small game design framework
6. Electron borderless window and transparent window lock mode setting window icon
PLC:自动纠正数据集噪声,来洗洗数据集吧 | ICLR 2021 Spotlight
数据库如何进行动态自定义排序?
一文读懂数仓中的pg_stat