当前位置:网站首页>Huawei cloud database DDS products are deeply enabled
Huawei cloud database DDS products are deeply enabled
2022-07-07 14:30:00 【Cheng Siyang】
Statement : This article references from 《 Huawei cloud developer school 》, Huawei cloud database DDS Deep product empowerment , Main orientation DA、 deliver 、 A line of 、 Second line database practitioners , in the light of DDS Common problems and product features , involve : Introduction to product features 、 Product usage scenarios 、 Product FAQs 、DDS Example usage specification and best practice introduction 、DDS Introduction to the internal mechanism of replica set and the internal principle of partitioned cluster .
This article is suitable for database solution engineers (DA)、 Database Delivery Engineer 、 Database frontline & Second line practitioners 、 And right DDS Interested users , It is hoped that readers can use Huawei cloud database through this article DDS Learning of product depth empowerment courses , To strengthen DA、 deliver 、 A line of 、 Second line understanding and skill improvement of database products .
This article is divided into 4 There are four chapters to explain :
The first 1 Chapter Huawei cloud database DDS Product introduction
The first 2 Chapter DDS Business development and use foundation
The first 3 Chapter understand DDS Kernel principle
The first 4 Chapter Use sharded clusters quickly
One 、 Huawei cloud database DDS Product introduction
1. DDS summary
First of all, we need to understand DDS Some basic information about :
Document database DDS(Document Database Service) Fully compatible with MongoDB agreement , It's normal MongoDB How to use ,DDS How to use , High performance in Huawei cloud 、 High availability 、 High security 、 On the basis of elastic expansion , Provides one click deployment , The elastic expansion , disaster , Backup , recovery , Monitoring and other service capabilities . At present, we support Fragmentation cluster (Sharding)、 Replica set (ReplicaSet)、 A single node (Single) Three deployment architectures .
MongoDB Data structure of

MongoDB Storage structure
• file (Document):MongoDB The most basic unit in , from BSON Key value pair (key-value) form .
Equivalent to rows in a relational database (Row).
• aggregate (Collection): A set can contain multiple file , Equivalent to tables in a relational database (Table)
• database (Database): Equivalent to the database concept in relational database , A database can contain multiple collections . You can go to MongoDB Create multiple databases in .
2. DDS Ministry Deployment form and key characteristics
2.1DDS Service deployment form - A single node (Single)
Architectural features
1. Ultra low cost , Just pay for one node
2. Support 10GB-1000GB Data storage ;
3. Compare replica sets / The cluster availability is not high : When the node fails , Business is not available ;
Applicable scenario
Non core data storage
Learning practice ;
The business of the test environment ;
2.2 DDS Service deployment form -- Replica set (Replica Set)

The figure above shows a classic three copy form
Architectural features
1. Three node high availability architecture : When the primary node fails , The system automatically selects
New master
2. Support 10GB-3000GB data storage ;
3. Have the ability to extend to 5 node ,7 Node replica set capabilities .
Applicable scenario
High availability requirements , data storage <3T
2.3 DDS Service deployment form -- colony (sharding)

Architectural features
1. Components : from mongos( route )、config( To configure )、shard( Fragmentation ) Three types of nodes make up
2. Shard Fragmentation : Every shard Is a replica set architecture , Responsible for storing business data . Can create 2-16 A shard , Each slice 10GB-2000GB. therefore , Cluster space range ( 2-16)*(10GB-2000GB)
3. Expand capabilities : Online specification change 、 Scale out online
Applicable scenario
High availability required , Large amount of data and future horizontal expansion requirements
2.4 DDS Key features

Document database DDS Major feature sets
• Database type and version : compatible MongoDB 3.4/4.0 edition
• Data security : Multiple security policies protect database and user privacy , for example :VPC、 subnet 、 Security group 、SSL etc.
• Data is highly reliable : Database storage supports triple copy redundancy , High reliability of database data ; High reliability of backup data
• High service availability ( Disaster tolerance in the same city ): colony / Replica set instances support cross AZ Deploy , High service availability
• Instance access : Multiple access methods , Include : Intranet IP visit 、 Public network IP visit
• Instance management : Support the creation of instances 、 Delete 、 Specification change 、 Node expansion 、 Disk expansion 、 Restart and other life cycle management
• Instance monitoring : Support monitoring database instances OS And DB Key performance indicators of the engine , Include CPU/ Memory / Storage capacity utilization 、1/O Activities 、 The number of database connections, etc
• Stretch and stretch : Horizontal expansion : Add or delete shard Fragmentation ( most 16 individual ); Vertical expansion : Instance specification change , Storage expansion ( Maximum n*2TB)
• Backup and recovery : Backup : Automatic backup 、 Manual backup , Full volume backup 、 Incremental backup , Addition of backup files 、 Delete 、 check 、 Lifecycle management such as replication . recovery : Replica sets support recovery to any point in time within the backup retention period (Point-In-Time Recovery, PITR)/ A full backup point in time , Restore to new instance / The original example . The backup storage cycle is up to 732 God
• Log management : Slow support SQL journal 、 Check the error log 、 And audit log download
• Parameter configuration : According to monitoring and log information , Customize the parameters of the database instance through the management console , To optimize the database . In addition, the management console provides an add function for parameter groups 、 Delete 、 Change 、 check 、 Reset 、 Compare 、 The ability to manage a series of parameters such as replication .
3. DDS Product advantages and application scenarios
3.1 DDS Product advantages
MongoDB
• 100% compatible MongoDB
• There is no need for business transformation , The ability to migrate directly to the cloud
• Support the community 3.4/4.0 edition
3 Architecture
• colony 、 Replica set 、 A single node
• colony :nTB Storage 、 Online expansion
• Replica set :2TB Storage
• A single node : High cost performance
High availability
• High availability of Architecture 、 Span AZ Deploy
• Support for replica sets ,Shard High availability Architecture ( colony )
• Replica set multi node ( 3、 ... and 、 5、 ... and 、 7、 ... and )
• colony 、 Replica sets support cross AZ Deploy
Highly reliable
• Automatically / Manual backup , Data recovery
• Automatic backup every day , Retain 732 God
• Manual backup , Keep forever
• Backup recovery
High security
• With multi-layer safety protection
• The Internet :VPC Network isolation
• transmission :SSL A secure connection
• visit : Security group out 、 Entry restrictions
management 、 monitor
• Visual monitoring :CPU、 Memory 、10、 Network, etc
• Instance one click expansion 、 Specification change
• Error log 、 Slow log management
• Parameter group configuration
3.2 DDS Application scenarios
Flexible business scenarios
DDS use No-Schema The way , Avoid the pain of changing the table structure , Ideal for start-up business needs .
Game applications
The database as the game server stores user information , User's game equipment 、 Integration and so on are directly stored in the form of embedded documents , Easy to query and update .
Live video
Store user information , Gift information, etc
3.3 DDS Use scenario example : Business elasticity extension , Flexible data structure
Business and data characteristics of the game industry
1. User information and transaction data are stored in MySQL in .
2. The character equipment data and the game process log are stored in DDS in
3. The game business changes frequently , The data table needs to be changed DDS Modifying the table structure has no impact on business .
The customer is in pain ( Private cloud deployment )
1. Resources do not scale elastically , You need to stop taking it and then operate it manually , High risk .
2. There is no automatic database fail over mechanism or insufficient capability , Primary instance failure , Modify application configuration , It takes a long time to stop taking it .
3. It's rare to set up a full-time DBA Position , Encounter the scenario of data archiving , It's hard to meet the demands of operations .
4. Game play changes quickly , The data model is flexible
Huawei cloud database solution
1. High performance
RDS MySQL and DDS Performance exceeds that of Alibaba cloud .
2. Stretch and stretch
RDS and DDS Support elastic expansion of disk , No business impact .
3. One click back ( Game business data demands )
RDS and DDS It supports table level and instance level file retrieval at any time point .
4. Read the service quickly
RDS and DDS, You can use backup to create a new instance , Realize fast service opening .
5. Fail over
RDS and DDS Switching between active and standby faults at second level , Transparent to business , The application configuration does not need to be changed .
4. DDS Management console and operation and maintenance guide
DDS Service home page

DDS Instance creation -1

DDS Instance creation -2

DDS Example details

Two 、 DDS Business development and use foundation
1. DDS High availability connection mode
Parameters | explain |
rwuser:**** | User name and password for starting authentication . |
192168.0148:8635 192.168.0.96:8635 | Replica set master 、 Standby node IP And port number |
test | Name of the database to be connected . |
authSource=admin | Indicates authentication , The database to which the user name belongs . |
replicaSet=replica | Replica set instance type name . |
Shard cluster high availability address :
mongodb://wuser;****@192.168.0.204:8635.192.168.0.94:8635/test?authSource=admin
Multiple mongosIP Configure on the client Driver Load balancing
Single mongos fault , other mongos The normal operation
Scenario of connection failure between replica set and partitioned cluster instance :
• The network port is blocked , Security group , Span vpc
• Open or not SSL A secure connection
• Connection parameter error , user name 、 Wrong password
• DDS The instance connection is full , Unable to create new connection
• DDS Instance memory 、CPU Too high
• Refer to the official guide for more details :
https://support.huaweicloud.com/dds fa/dds_faq_0218.html
2. DDS User recognition Certificate and creation
2.1 User authentication
user , role , jurisdiction , object Model ---- be based on admin Libraries create and manage user roles
user :userA,userB,userC, role :role1,role2,role3 jurisdiction :userAdmin,readWrite.…
object :db,collection(action)
View the current user and role :
use admin
db.runCommand({rolesinfo: 1});
db.runCommand({ userslnfo: 1} );
Take several common user roles for example :
Manage user and role accounts :userAdminAnyDatabase
db.createUser({user:"user_admin,pwd:"YourPwd_234",roles:[{role:"userAdminAnyDatabase",db:"admin")
Manage database accounts :dbAdminAnyDatabase
db.createUser(fuser:"dbadmin"pwd:"YourPwd 234"roles:[{role:"dbAdminAnyDatabase",db:"admin"}l})
· Specify the management account of the library :dbAdmin
db.createUser({user:"db_admin_db1",pwd:"YourPwd_234",roles:[{role:"dbAdmin",db:"db1"}I})
Read only account of the whole database :readAnyDatabase
db.createUser({user:"db_read",pwd:"YourPwd_234",roles:{role: "readAnyDatabase",db:"admin"}})
· Specify the read / write account number of the library :readWrite
db.createUser({user:"db_rw_db2",pwd:"YourPwd_234",roles:[{role:"readWrite",db:"db2"}l})
2.2 Create a privileged user
The management user can manage the unreadable and writable data of the library table after logging in

Read only users can read but not write after logging in

3. DDS Use the connection parameters to separate the read and write
3.1 Selection of read / write separation scenarios
• Highly reliable operation of the production environment , High availability of core components , Improve the overall availability and service quality of the system
• Understand in combination with node deployment patterns :
•https://supporthuaweicloud.com/bestpractice-dds/dds_0003.html
• Usage scenario of read-write separation
• How to select read parameters Read Preference
primary( Only master ) Only from primary Nodes read data , This is the default setting
primaryPreferred( First lord, then slave ) Priority from primary Read ,primary No service , from secondary read secondary( Only from ) Only from scondary Nodes read data
secondaryPreferred ( First from then on ) Priority from secondary Read , No, secondary Members , from primary Read nearest( Nearby ) Read nearby according to network distance , According to the client and server PingTime Realization
3.2 An example of a read / write separation configuration
An example of a read / write separation configuration :
Can pass uri Connection parameter configuration , You can also configure the read preferences for a single query operation mongodb://db_rw_db2:[email protected]:port1,IP2:port2/db2?
authSource=admin&replicaSet=replica&readPreference=secondaryPreferred
replica:PRIMARY> db.coll1.find().readPref("secondary");
2021-12-29T11:56:09.435+0000 I NETWORK [js] Successfully connected to 192.168.2
"id":0bjectId("61cc2b7270efbd76daa54891"),"age": 13 }
id" ObjectId("61cc2b7970efbd76daa54892"),"age": 14 }
4. DDS Write policy configuration
A battle of consistency and availability ----- Adjustable consistency parameter
• Write strategy writeConcern Parameter usage and default values
·db.collection.insert({x:1},{writeConcern:{w:1}})
·mongodb://db_rw_db2:YourPwd [email protected]:port1P2:port2/db2?
authSource=admin&replicaSet=replica&w=majority&wtimeoutMS=5000
• Partition fault tolerance is inevitable
• Business data consistency : Real time consistency , Final consistency {w:n} {w:“majority"}w The default is 1
• System service availability : The delay tolerance of read / write operations depends on multi node data synchronization oplog Copy to the standby node
• Select the above parameter values based on the business characteristics
The write operation policy is specified in the connection parameter

The write operation policy is specified in the single operation parameter

3、 ... and 、 understand DDS Kernel principle
1. DDS Overview of service deployment model

Architectural features
1. High availability service mode , Automatic failover , Read write separation scenario
2. Support 10GB-3000GB data storage ;
3. Have the ability to extend to 5 node ,7 Node replica set capabilities .
Applicable scenario
High availability requirements , data storage <3T
2. DDS Heartbeat and election
2.1 DDS heart Jump and election

• Within the replica set , Between nodes
• By default , interval 2s
• 10s The primary node did not respond to the active election
• Automatic failover
victory :
The node with the latest data gets most of the node votes
2.2 DDS Automatic failover

Replica set node role :
• Primary
• Secondary
• Hidden
• Arbiter
Fail over
• Primary Something goes wrong ( Node heartbeat is not normal )
• Secondary Launch an election , Take over actively
• Driver Connect replica set for normal business read / write
2.3 DDS Replica set management

Replica set management :
• Replica set configuration initialization rs.initiate()
• Replica set add members rs.add()
• Replica set delete member rs.remove()
• Replica set configuration view rs.config() Replica set configuration reset rs.reconfig()
• Replica set status view rs.status()
3. DDS Count Data synchronization and replication
3.1 DDS data Sync

Data synchronization within multiple replica sets :
• Within the replica set , One Primary, Multiple Secondary
• The standby node can carry the read capacity
• The standby node selects the synchronization source : Master node or Other nodes that are newer than their own data
• Allow chain copying , Reduce the pressure on the main node
• Data is replayed on the standby node through operation records
• The latest operation timestamp of the standby node as the data replication progresses
3.2 DDS Count According to the synchronous explanation

Key technical points of data replication :
• After the master node writes data , Record oplog
• Standby node pull oplog√ Standby node application oplog
• voplog Is a set of fixed size , Write in natural order , No index
• Multithreaded parallel applications oplog:
• A thread internal operation is executed serially
• A collection of oplog Will be handled by a thread
• Of different sets oplog Will be allocated to different threads for processing
• Update database state , Update the latest timestamp
3.3 DDS Data synchronization considerations

Notes on replication :
• Within the replica set oplogsize Fix , Writing data will eliminate the old oplog data
• Database instance of no-load service , adopt noop Special operation progress
• noop Every operation interval 10s write in oplog, Less than 10s No writing
• Business overload , Write speed is too fast, causing the replication to be disjointed
• Can pass write Concern Make sure to write to most nodes
• Read write separation can be specified readPreference
4. DDS check Inquire about plans and other mechanisms
4.1 DDS Query plan and index suggestions

Index type :
• Single field index
• Combined field index
{userid: 1,score:-1}
• Nested field index
{“addr.zip”}
• Geolocation index
2dsphere indexes
• Text index
• hash Indexes
Index attribute :
• unique index
• Partial index
• Sparse index
• TTL Indexes (Time to Live)
Diagnose the query effect through the query plan :
• explain Plan analysis : Return to document 、 Scan document 、 Whether to overwrite the index 、 Whether to sort in memory
• queryPlanCache View the query plan scheme cache
4.2 DDS book Read the data change scenario

Subscription data change :
• adopt watch Listen for data changes in a set
• adopt cursor Of next Continue to return the data changes of the set
• full_document='updateLookup’ return update Full text file
• db.bar.watch(0.{“resumeAfter”:<\_id>}) Recover from breakpoints
• readConcern=true
• Breakpoint time can be recovered , The same goes for oplog Available Windows
Change Stream Limit :
• part DDL Operation does not support
• fullDocument Back to update The full text may be changed by subsequent operations
• Full information ( Under the premise of frequent and rapid changes )
• change stream Return body limit 16M, The original data modification needs to be smaller
4.3 DDS other Mechanism considerations

file & Gather suggestions :
• JSON Data model ( Object model cohesive data association )
• file Size Limit 16MB
• It is not recommended to store excessive data in a collection
• Use fixed sets effectively (size,max)
• Delete the database to quickly free memory
• The total number of sets is too large, which leads to high memory consumption
Four 、 Use sharded clusters quickly
1.DDS Overview of service deployment model
DDS Service set deployment form

Architectural features
1. Components : from mongos( route )、config( To configure )、shard( Fragmentation ) Three types of nodes make up
2.Shard Fragmentation : Every shard Is a replica set architecture , Be responsible for keeping
Store business data . Can create 2-32 A shard , Each slice 10GB-2000GB. therefore , Cluster space range (2-32)*(10GB-2000GB)
3. Expand capabilities : Online specification change 、 Scale out online
Applicable scenario
High availability required , Large amount of data and future horizontal expansion requirements
2. DDS branch The chip cluster basically uses
2.1 DDS Select the cluster size

• Fragment cluster deployment mode , Horizontal sub table , Scale out storage and read / write capabilities
• 2 individual mongos above , The routing module provides highly available access
• 2 individual shard above , It has the ability of fragment expansion
• One shard Internally, it serves as a replica set , Have all the properties of the replica set
• The user database creates non sharding by default , You need to specify the database and table splitting methods
2.2 DDS Select the slice key Association index

Suggestions for slicing keys
Similar to index selection , Fields with strong value selectivity 、 It can be that there are too many single associated documents for the combined field index value , Easily lead to Jumbo chunk Make sure the query contains shard key, avoid scatter-gather Query slice key types HashedRange
>sh.shardCollection("database.collection"{<field>:"hashed"})>sh.shardCollection("database.collection",{<shard key>})
Example of partition key : Massive device log type data
timestemp range | Time trends lead to a new data set shard Write requests are not balanced | Don't suggest |
Timestemp hashed | according to device id The query is broadcast to each shard On 、mongos Upper memory sort | Don't suggest |
Device id hashed | The same device The data may bring Jumbo chunk | Don't suggest |
device_id+timestamp range | Write evenly to multiple shard、 Refine chunk Division 、 Support range query | Suggest |
2.3 DDS preset chunk And other suggestions

• preset chunk It can effectively reduce the performance consumption caused by balancing
• chunksize Default 64MB、 The logical unit of data aggregation
• shard key optimization , avoid Jumbo chunk
• shard key The value does not exceed 512 Bytes
• db.colname.getShardDistribution()# You can view the data distribution
• scatter-gather Query generates mongos Input network card traffic is too high
• hash Fragmentation mode , Create a set to specify the preset initialization chunks Number
mongos> sh.enableSharding("<database>") mongos> use admin
mongos>db.runCommand({shardcollection:“<database>.<collection>”,key:{“keyname”:“hashed”), numinitialChunks: 1000})
• range Fragmentation mode , Initialize by using the split point chunks Number
mongos>db.adminCommand({split:"test.coll2middle:{username:1900}})( Look for the right syncopation point many times , The proposal USES DRS Full migration functionality )
3. DDS config And management operation
3.1DDS config server And metadata

• config database # mongos> use config
• config.shards #db.shards.find()
• config.databases #db.databases.find()
• config.collections # Piecewise set
• config.chunks # all chunks The record of
• config.settings #shard cluster Configuration information
• mongos>db.settings.find()
("id" : "chunksize”, "value": NumberLong(64)}
{"id" : "balancer", "stopped": false )
• config server Store the metadata of the entire partitioned cluster
• In replica sets 、 High availability deployment
3.2 DDS Cluster management and best practices

• Add the shard
db.runCommand({addShard:"repl0/mongodb3examplenet:27327"})
• Delete fragment removeShard It will affect chunks The redistribution of 、 Too long running time
• View balance
mongos>sh.getBalancerState()# Check whether equalization is enabled
mongos>sh.isBalancerRunning0 # Check whether the migration is balanced chunk
• Stop during backup 、 Turn on equilibrium sh.stopBalancer()
sh.setBalancerState(true)
• Refresh routing information
db.adminCommand({flushRouterConfig:"<db.collection>"}) db.adminCommand({ flushRouterConfig: "<db>" } )
db.adminCommand( { flushRouterConfig: 1 })
4.DDS The basic principles of division and equilibrium
4.1 DDS The basic principle of splitting

• Split command
sh.splitFind("records.people"{"zipcode":"63109"})
# matching zipcode:63109 Of chunk, Split into 2 One or more chunk sh.splitAt( “records.people”,{ “zipcode”: “63109”))# With zipcode:63109 Is the split point , Split into 2 individual chunk
• The basic process of splitting
sharding.autoSplit Auto split is on by default
Insert 、 to update 、 When deleting data ,mongos Judge chunk Whether the threshold is exceeded , Trigger chunk split
chunk Splitting is a logical action , Mark the data boundary left open and right closed based on metadata [)
chunk Internal data shard key Is the same value , Cannot be split to form Jumbo chunk
4.2 DDS The basic principle of equilibrium

• Migration command
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
• Migration command
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
_waitForDelete<boolean>})
• The basic process of migration
• from config server Notify the sender shard, And specify the migration chunk Mission ( Move one at a time chunk)
• The sender shard Inform the recipient shard Actively copy data in batches 、 The increment is applied to the receiver
• The sender judges chunk After data migration, enter the critical zone , The write operation is suspended until the critical area is exited
• The receiver's last copy chunk The last incremental data is completed commit, After completion, the receiver exits the critical area
• The receiver finally deletes the local data asynchronously chunk( orphan chunk)
• Equalization window
use config
db.settings.update({id:"balancer}.{$set:
{activeWindow:{start:“02:00stop:"06:00"}}}
{upsert: true })
边栏推荐
- GAN发明者Ian Goodfellow正式加入DeepMind,任Research Scientist
- Excuse me, as shown in the figure, the python cloud function prompt uses the pymysql module. What's the matter?
- IP and long integer interchange
- Horizontal of libsgm_ path_ Interpretation of aggregation program
- LeetCode每日一题(636. Exclusive Time of Functions)
- Data connection mode in low code platform (Part 2)
- 一文读懂数仓中的pg_stat
- 交换机和路由器的异同
- WPF DataGrid realizes the UI interface to respond to a data change in a single line
- MicTR01 Tester 振弦采集模块开发套件使用说明
猜你喜欢

Docker deploy Oracle

Data connection mode in low code platform (Part 2)

CVPR2022 | 医学图像分析中基于频率注入的后门攻击

Vscode configuration uses pylint syntax checker
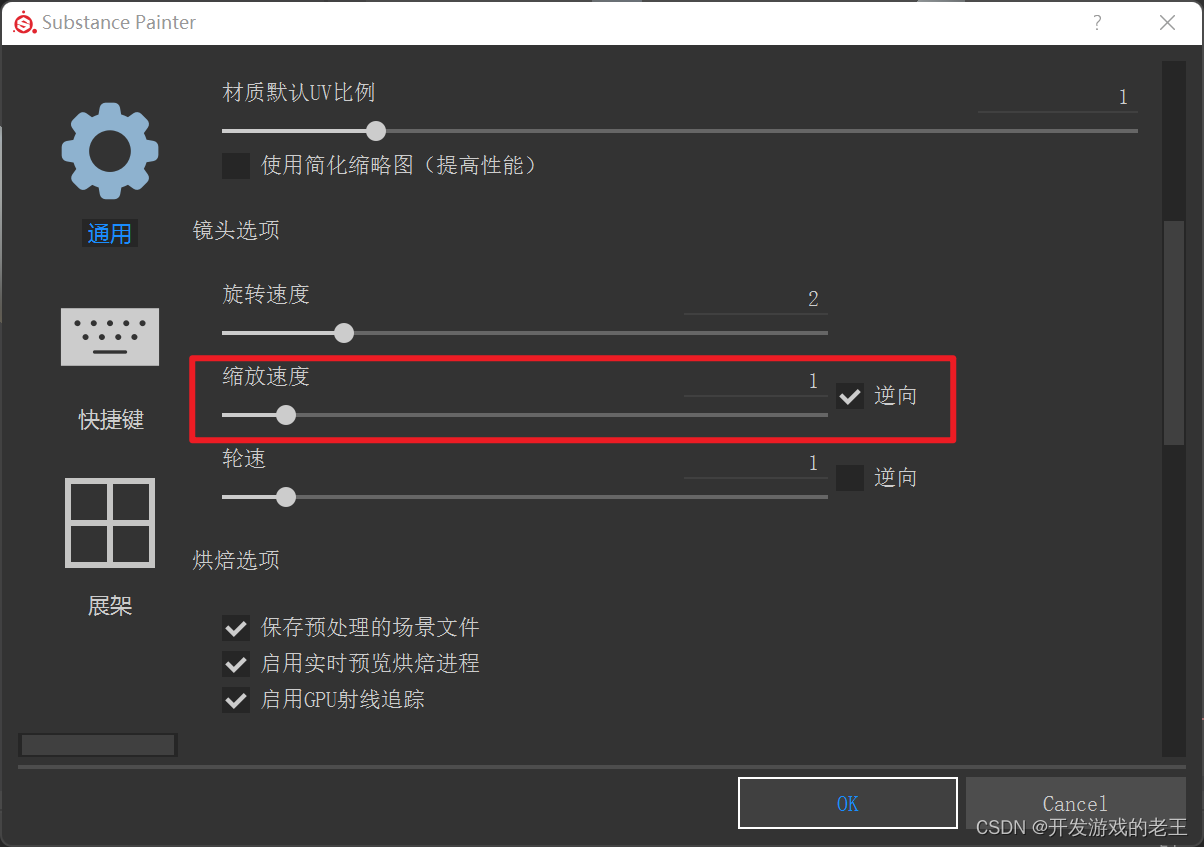
Substance Painter笔记:多显示器且多分辨率显示器时的设置
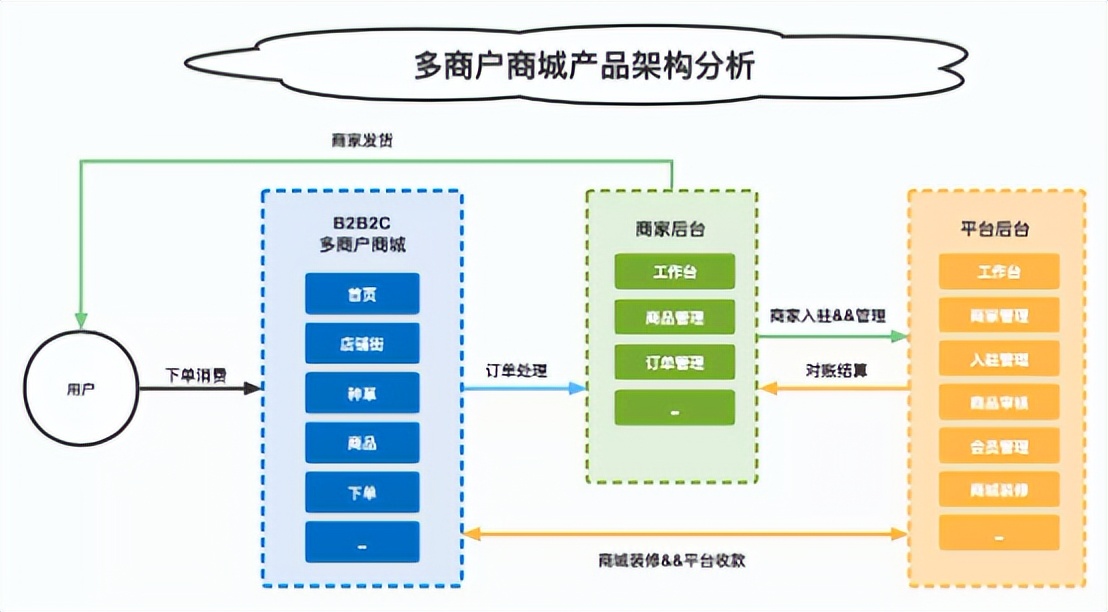
多商户商城系统功能拆解01讲-产品架构
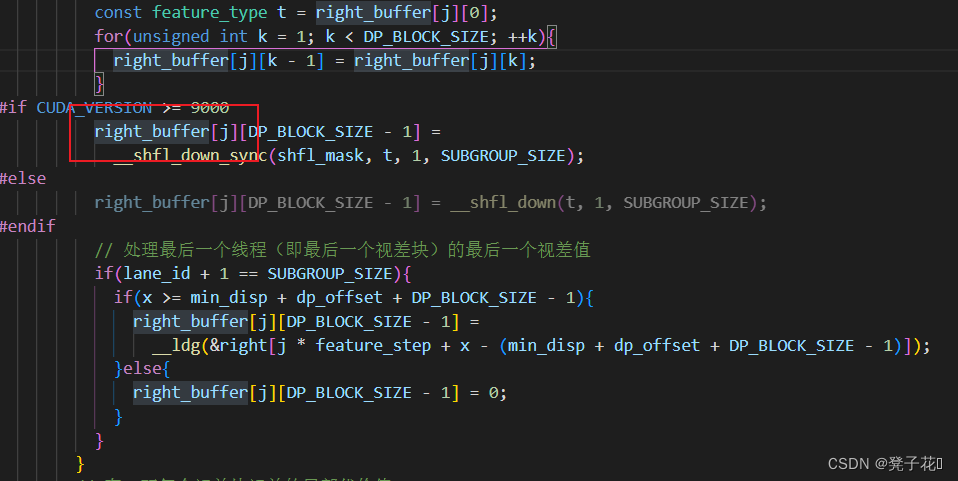
libSGM的horizontal_path_aggregation程序解读
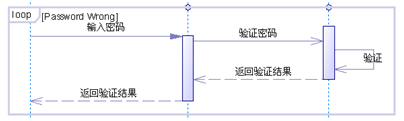
UML 顺序图(时序图)

最长上升子序列模型 AcWing 1014. 登山
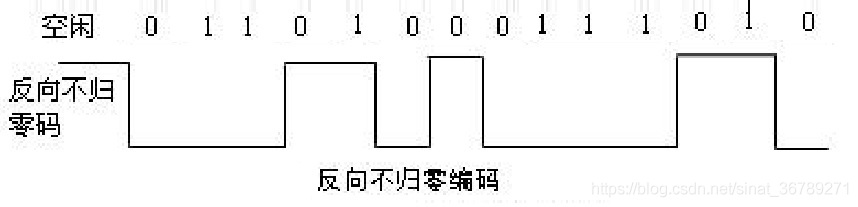
常用數字信號編碼之反向不歸零碼碼、曼徹斯特編碼、差分曼徹斯特編碼
随机推荐
请问,PTS对数据库压测有好方案么?
Verilog implementation of a simple legv8 processor [4] [explanation of basic knowledge and module design of single cycle implementation]
[Reading stereo matching papers] [III] ints
Navigation - are you sure you want to take a look at such an easy-to-use navigation framework?
Use case diagram
ndk初学习(一)
Mrs offline data analysis: process OBS data through Flink job
小米的芯片自研之路
华为云数据库DDS产品深度赋能
Notes de l'imprimante substance: paramètres pour les affichages Multi - écrans et multi - Résolutions
【立体匹配论文阅读】【三】INTS
最长上升子序列模型 AcWing 1012. 友好城市
LeetCode 648. 单词替换
[AI practice] Application xgboost Xgbregressor builds air quality prediction model (II)
Decrypt the three dimensional design of the game
Cascading update with Oracle trigger
docker部署oracle
First choice for stock account opening, lowest Commission for stock trading account opening, is online account opening safe
UML 状态图
IP and long integer interchange