当前位置:网站首页>华为云数据库DDS产品深度赋能
华为云数据库DDS产品深度赋能
2022-07-07 12:38:00 【程思扬】
声明:本文参考自《华为云开发者学堂》,华为云数据库DDS产品深度赋能,主要面向DA、交付、一线、二线数据库从业者,针对DDS常见问题及产品特性进行介绍,涉及:产品特性介绍、产品使用场景介绍、产品常见问题介绍、DDS实例使用规范及最佳实践介绍、DDS副本集内部机制和分片集群内部原理介绍等。
本文适合数据库解决方案工程师(DA)、数据库交付工程师、数据库一线&二线从业者、以及对DDS感兴趣的用户,希望读者可以通过本文通过华为云数据库DDS产品深度赋能课程的学习,加强DA、交付、一线、二线对数据库产品的理解和技能提升。
本文分为4个章节展开讲解:
第1章 华为云数据库DDS产品介绍
第2章 DDS业务开发使用基础
第3章 了解DDS内核原理
第4章 快速使用分片集群
一、 华为云数据库DDS产品介绍
1. DDS 概述
首先我们要了解一下DDS的一些基础信息:
文档数据库 DDS(Document Database Service)完全兼容 MongoDB 协议,也就是正常MongoDB如何使用,DDS就如何使用,在华为云高性能、高可用、高安全、可弹性伸缩的基础上,提供了一键部署,弹性扩容,容灾,备份,恢复,监控等服务能力。目前支持分片集群(Sharding)、副本集(ReplicaSet)、单节点(Single)三种部署架构。
MongoDB的数据结构

MongoDB存储结构
• 文档(Document):MongoDB中最基本的单元,由BSON键值对(key-value)组成。
相当于关系型数据库中的行(Row)。
• 集合(Collection):一个集合可以包含多个 文档,相当于关系型数据库中的表(Table)
• 数据库(Database):等同于关系型数据库中的数据库概念,一个数据库中可以包含多个集合。您可以在MongoDB中创建多个数据库。
2. DDS 部署形态及关键特性
2.1DDS服务部署形态-单节点(Single)
架构特点
1.超低成本,仅需支付一个节点的费用
2.支持10GB-1000GB 的数据存储;
3.较副本集/集群可用性不高:当节点故障,业务不可用;
适用场景
非核心数据存储
学习实践;
测试环境的业务;
2.2 DDS服务部署形态--副本集(Replica Set)

上图为一个经典的三副本形态
架构特点
1. 三节点高可用架构:当主节点故障时,系统自动选出
新的主节点
2.支持10GB-3000GB 数据存储;
3. 具备扩展到5节点,7节点副本集的能力。
适用场景
有高可用需求,数据存储<3T
2.3 DDS服务部署形态--集群(sharding)

架构特点
1. 组件构成:由mongos(路由)、config(配置)、shard(分片)三种类型的节点构成
2. Shard 分片:每个shard都是一个副本集架构,负责存储业务数据。可创建2-16个分片,每个分片10GB-2000GB。因此,集群空间范围( 2-16)*(10GB-2000GB)
3. 扩展能力:在线规格变更、在线横向扩展
适用场景
要求高可用,数据量大且未来横向扩展要求
2.4 DDS关键特性

文档数据库 DDS 主要特性集
• 数据库类型及版本:兼容 MongoDB 3.4/4.0 版本
• 数据安全:多种安全策略保护数据库和用户隐私,例如:VPC、子网、安全组、SSL等
• 数据高可靠:数据库存储支持三副本冗余,数据库数据可靠性高;备份数据可靠性高
• 服务高可用(同城容灾):集群/副本集实例支持跨AZ部署,服务可用性高
• 实例访问:多种访问方式,包括:内网IP 访问、公网IP 访问
• 实例管理:支持实例的创建、删除、规格变更、节点扩容、磁盘扩容、重启等生命周期管理
• 实例监控:支持监控数据库实例OS及DB引擎的关键性能指标,包括CPU/内存/存储容量使用率、1/O活动、数据库连接数等
• 弹性伸缩:水平伸缩:增删 shard 分片(最多 16个);垂直伸缩:实例规格变更,存储空间扩容(最大n*2TB)
• 备份与恢复:备份:自动备份、手动备份,全量备份、增量备份,备份文件的增、删、查、复制等生命周期管理。恢复:副本集支持恢复到备份保留期内任意时间点(Point-In-Time Recovery, PITR)/某个全量备份时间点,恢复到新实例/原实例。备份保存周期高达 732天
• 日志管理:支持慢SQL日志、错误日志的查看、以及审计日志下载
• 参数配置:可以根据监控和日志等信息,通过管理控制台对数据库实例的参数进行自定义设置,从而优化数据库。另外管理控制台对参数组提供了增、删、改、查、重置、比较、复制等一系列的参数管理的能力。
3. DDS 产品优势及应用场景
3.1 DDS 的产品优势
MongoDB
• 100%兼容 MongoDB
• 具备无需业务改造,直接迁移上云的能力
• 支持社区3.4/4.0版本
3种架构
• 集群、副本集、单节点
• 集群:nTB存储、在线扩容
• 副本集:2TB存储
• 单节点:高性价比
高可用
• 架构高可用、跨AZ 部署
• 支持副本集,Shard高可用架构(集群)
• 副本集多节点(三、五、七)
• 集群、副本集支持跨AZ部署
高可靠
• 自动/手动备份,数据恢复
• 每天自动备份,保留732天
• 手动备份,永久保存
• 备份恢复
高安全
• 具备多层安全防护
• 网络:VPC网络隔离
• 传输:SSL安全连接
• 访问:安全组出、入限制
管理、监控
• 可视化监控:CPU、内存、10、网络等
• 实例一键扩容、规格变更
• 错误日志、慢日志管理
• 参数组配置
3.2 DDS 应用场景
灵活多变的业务场景
DDS采用No-Schema的方式,避免变更表结构的痛苦,非常适用于初创型的业务需求。
游戏应用
作为游戏服务器的数据库存储用户信息,用户的游戏装备、积分等直接以内嵌文档的形式存储,方便进行查询与更新。
视频直播
存储用户信息,礼物信息等
3.3 DDS 使用场景举例:业务弹性扩展,数据结构灵活
游戏行业业务和数据特点
1.用户信息和交易数据存储在MySQL中。
2.角色装备数据及游戏的过程日志存储在 DDS 中
3.游戏业务变化频繁,对于数据表需要做结果变更DDS修改表结构对业务无影响。
客户痛点(私有云部署)
1.资源不具备弹性伸缩,需要停服然后手工操作,风险极高。
2.没有数据库的故障自动切换机制或能力不足,主实例故障,修改应用配置,停服时间长。
3.很少设置专职 DBA 岗位,遇见数据回档场景,很难满足运营的诉求。
4.游戏玩法变化快,数据模型灵活变化
华为云数据库的解决方案
1.高性能
RDS MySQL和DDS性能超越阿里云。
2.弹性伸缩
RDS和DDS支持磁盘的弹性扩容,对业务无影响。
3.一键回档(游戏业务数据诉求)
RDS和DDS支持表级和实例别任意时间点的回档。
4. 快读开服
RDS和DDS,可使用备份创建新实例,实现快速开服。
5.故障切换
RDS 和 DDS 主备故障秒级别切换,对业务透明,应用配置无需改动。
4. DDS 管理控制台及运维指南
DDS 服务首页

DDS 实例创建-1

DDS 实例创建-2

DDS 实例详情

二、 DDS业务开发使用基础
1. DDS 高可用连接方式
参数 | 说明 |
rwuser:**** | 启动鉴权的用户名和密码。 |
192168.0148:8635 192.168.0.96:8635 | 副本集主、备节点的IP及端口号 |
test | 待连接的数据库名称。 |
authSource=admin | 表示鉴权时,用户名所属的数据库。 |
replicaSet=replica | 副本集实例类型名称。 |
分片集群高可用址:
mongodb://wuser;****@192.168.0.204:8635.192.168.0.94:8635/test?authSource=admin
多个mongosIP配置在客户端Driver进行负载均衡
单个mongos故障,其他mongos正常运行
副本集和分片集群实例连接失败场景:
• 网络端口不通,安全组,跨 vpc
• 是否开启SSL安全连接
• 连接参数错误,用户名、密码错误
• DDS实例连接占满,无法创建新连接
• DDS实例内存、CPU过高
• 更多详情参考官方指南:
https://support.huaweicloud.com/dds fa/dds_faq_0218.html
2. DDS 用户认证及创建
2.1用户认证
用户,角色,权限,对象 模型 ---- 基于admin库创建并管理用户角色
用户:userA,userB,userC,角色:role1,role2,role3 权限:userAdmin,readWrite.…
对象:db,collection(action)
查看当前用户及角色:
use admin
db.runCommand({rolesinfo: 1});
db.runCommand({ userslnfo: 1} );
举例几个常用用户角色:
管理用户及角色账号:userAdminAnyDatabase
db.createUser({user:"user_admin,pwd:"YourPwd_234",roles:[{role:"userAdminAnyDatabase",db:"admin")
管理数据库账号:dbAdminAnyDatabase
db.createUser(fuser:"dbadmin"pwd:"YourPwd 234"roles:[{role:"dbAdminAnyDatabase",db:"admin"}l})
·指定库的管理账号:dbAdmin
db.createUser({user:"db_admin_db1",pwd:"YourPwd_234",roles:[{role:"dbAdmin",db:"db1"}I})
全库的只读账号:readAnyDatabase
db.createUser({user:"db_read",pwd:"YourPwd_234",roles:{role: "readAnyDatabase",db:"admin"}})
·指定库的读写账号:readWrite
db.createUser({user:"db_rw_db2",pwd:"YourPwd_234",roles:[{role:"readWrite",db:"db2"}l})
2.2创建权限用户
管理用户登录后可管理库表不可读写数据

只读用户登录后可读不可写

3. DDS 用连接参数读写分离
3.1 读写分离场景的选择
• 生产环境的高可靠运转,核心组件高可用,提高系统整体可用性及服务质量
• 结合节点部署形态理解 :
•https://supporthuaweicloud.com/bestpractice-dds/dds_0003.html
• 读写分离的使用场景
• 怎么选择读参数 Read Preference
primary(只主)只从 primary节点读数据,这个是默认设置
primaryPreferred(先主后从)优先从primary读取,primary不可服务,从 secondary读 secondary(只从)只从scondary节点读数据
secondaryPreferred (先从后主)优先从secondary读取,没有secondary成员时,从primary读取 nearest(就近)根据网络距离就近读取,根据客户端与服务端的PingTime实现
3.2 读写分离配置使用举例
读写分离配置使用举例:
可以通过uri连接参数配置,也可以再单次查询操作的时候配置读取偏好 mongodb://db_rw_db2:[email protected]:port1,IP2:port2/db2?
authSource=admin&replicaSet=replica&readPreference=secondaryPreferred
replica:PRIMARY> db.coll1.find().readPref("secondary");
2021-12-29T11:56:09.435+0000 I NETWORK [js] Successfully connected to 192.168.2
"id":0bjectId("61cc2b7270efbd76daa54891"),"age": 13 }
id" ObjectId("61cc2b7970efbd76daa54892"),"age": 14 }
4. DDS 写策略配置
一致性和可用性的一场较量----- 可调一致性参数
• 写入策略writeConcern参数使用及默认值
·db.collection.insert({x:1},{writeConcern:{w:1}})
·mongodb://db_rw_db2:YourPwd [email protected]:port1P2:port2/db2?
authSource=admin&replicaSet=replica&w=majority&wtimeoutMS=5000
• 分区容错不可避免
• 业务数据一致性:实时一致性,最终一致性{w:n} {w:“majority"}w默认是1
• 系统服务可用性:读写操作的延迟容忍度多节点数据同步依赖oplog复制到备节点
• 业务特征来平衡选择以上参数取值
写操作策略再连接参数中指定

写操作策略再单次操作参数中指定

三、 了解DDS内核原理
1. DDS 服务部署模型概述

架构特点
1.高可用服务方式,自动故障转移,读写分离场景
2.支持10GB-3000GB 数据存储;
3.具备扩展到5节点,7节点副本集的能力。
适用场景
有高可用需求,数据存储<3T
2. DDS心跳及选举
2.1 DDS心跳及选举

• 副本集内,节点之间
• 默认情况,间隔 2s
• 10s未收到主节点响应主动选举
• 实现自动故障转移
胜选:
数据相对最新的节点获得大多数节点选票
2.2 DDS自动故障转移

副本集节点角色:
• Primary
• Secondary
• Hidden
• Arbiter
故障转移
• Primary发生异常(节点心跳未正常)
• Secondary发起选举,主动接管
• Driver连接副本集正常业务读写
2.3 DDS副本集管理

副本集管理:
• 副本集配置初始化rs.initiate()
• 副本集添加成员 rs.add()
• 副本集删除成员rs.remove()
• 副本集配置查看rs.config()副本集配置重置rs.reconfig()
• 副本集状态查看rs.status()
3. DDS数据同步和复制
3.1 DDS数据同步

多个副本集内数据同步:
• 副本集内,一个Primary,多个Secondary
• 备节点可以承载读取能力
• 备节点选择同步源:主节点or其他比自己数据更新的节点
• 允许链式复制,减缓主节点压力
• 数据通过操作记录重放在备节点
• 随着数据复制推移备节点最新操作时间戳
3.2 DDS数据同步详解

复制数据关键技术点:
• 主节点写入数据后,记录oplog
• 备节点拉取oplog√备节点应用oplog
• voplog是固定大小的集合,自然序写入,无索引
• 多线程并行应用oplog:
• 一个线程内部操作串行执行
• 一个集合的oplog会被一个线程处理
• 不同集合的oplog会被分配到不同线程处理
• 更新数据库状态,更新最新时间戳
3.3 DDS数据同步注意事项

关于复制的注意事项:
• 副本集内oplogsize固定,写入数据会淘汰旧的oplog数据
• 空载业务的数据库实例,通过noop特殊操作推移
• noop操作每次间隔10s写入oplog,少于10s则不写入
• 业务过载,写入速度过快导致复制脱节
• 可以通过write Concern确保写入多数节点
• 可以指定读写分离readPreference
4. DDS 查询计划和其他机制
4.1 DDS查询计划及索引建议

索引类型:
• 单字段索引
• 组合字段索引
{userid: 1,score:-1}
• 嵌套字段索引
{“addr.zip”}
• 地理位置索引
2dsphere indexes
• 文本索引
• hash索引
索引属性:
• 唯一索引
• 部分索引
• 稀疏索引
• TTL索引(Time to Live)
通过查询计划诊断查询效果:
• explain计划分析:返回文档、扫描文档、是否覆盖索引、是否内存排序
• queryPlanCache查看查询计划方案缓存情况
4.2 DDS订阅数据变更场景

订阅数据变更:
• 通过watch对于一个集合的数据变更进行监听
• 通过cursor的next持续返回该集合的数据变更
• full_document='updateLookup’返回update全文档
• db.bar.watch(0.{“resumeAfter”:<\_id>})从断点恢复
• readConcern=true
• 断点时间可恢复,同理与oplog可用窗口
Change Stream限制:
• 部分DDL操作不支持
• fullDocument返回的update全文可能被后续操作更改的
• 全量信息(在频繁快速更改前提下)
• change stream返回体限制16M,则原始数据修改需要更小
4.3 DDS其他机制注意事项

文档&集合建议:
• JSON数据模型(对象模型内聚数据关联)
• 文档Size限制16MB
• 一个集合中不建议存储过量数据
• 有效使用固定集合(size,max)
• 删除数据库快速释放内存
• 集合总体数量过多导致内存占用过高
四、 快速使用分片集群
1.DDS服务部署模型概述
DDS服务集部署形态

架构特点
1.组件构成:由mongos(路由)、config(配置)、shard(分片)三种类型的节点构成
2.Shard 分片:每个shard 都是一个副本集架构,负责存
储业务数据。可创建 2-32个分片,每个分片10GB-2000GB。因此,集群空间范围(2-32)*(10GB-2000GB)
3. 扩展能力:在线规格变更、在线横向扩展
适用场景
要求高可用,数据量大且未来横向扩展要求
2. DDS分片集群基本使用
2.1 DDS选择集群规模

• 分片集群部署方式,水平分表,横向扩展存储和读写能力
• 2个mongos以上,路由模块提供高可用的接入
• 2个shard以上,具备分片扩展能力
• 一个shard内部以副本集方式服务,具备副本集所有属性
• 用户数据库默认创建非分片,需要指定分库及分表方式
2.2 DDS选择片键关联索引

分片键建议
类似索引选择,取值选择性强的字段、可以是组合字段索引取值单个关联文档过多,容易导致Jumbo chunk确保查询包含shard key,避免scatter-gather查询片键类型区分HashedRange
>sh.shardCollection("database.collection"{<field>:"hashed"})>sh.shardCollection("database.collection",{<shard key>})
分片键举例:海量设备日志类型数据
timestemp range | 时间趋势导致新数据集中一个shard 写请求并不均衡 | 不建议 |
Timestemp hashed | 根据device id 查询会广播到每个shard上、mongos上内存排序 | 不建议 |
Device id hashed | 同一个device 的数据可能带来Jumbo chunk | 不建议 |
device_id+timestamp range | 写入均匀到多个 shard、精细化 chunk 的划分、支撑范围查询 | 建议 |
2.3 DDS 预置chunk及其他建议

• 预置chunk能够最有效降低均衡带来的性能消耗
• chunksize默认64MB、数据聚集的逻辑单位
• shard key优选,避免Jumbo chunk
• shard key 取值不超过 512 Bytes
• db.colname.getShardDistribution()#可以查看数据分布
• scatter-gather查询产生mongos输入网卡流量过高
• hash分片方式,创建集合指定预置初始chunks数量
mongos> sh.enableSharding("<database>") mongos> use admin
mongos>db.runCommand({shardcollection:“<database>.<collection>”,key:{“keyname”:“hashed”), numinitialChunks: 1000})
• range分片方式,通过采用分裂点初始化chunks数量
mongos>db.adminCommand({split:"test.coll2middle:{username:1900}})(多次寻找合适切分点,建议采用DRS完整迁移功能)
3. DDS config 及管理操作
3.1DDS config server 及元数据

• config database # mongos> use config
• config.shards #db.shards.find()
• config.databases #db.databases.find()
• config.collections #分片集合
• config.chunks #所有chunks的记录
• config.settings #shard cluster配置信息
• mongos>db.settings.find()
("id" : "chunksize”, "value": NumberLong(64)}
{"id" : "balancer", "stopped": false )
• config server 存储整个分片集群元数据
• 以副本集为单位、高可用部署方式
3.2 DDS 集群管理及最佳实践

• 添加分片
db.runCommand({addShard:"repl0/mongodb3examplenet:27327"})
• 删除分片 removeShard 会影响chunks的重新分配、运行时间过长
• 查看均衡
mongos>sh.getBalancerState()#查看是否开启均衡
mongos>sh.isBalancerRunning0 #查看是否正在均衡迁移chunk
• 备份时停止、开启均衡sh.stopBalancer()
sh.setBalancerState(true)
• 刷新路由信息
db.adminCommand({flushRouterConfig:"<db.collection>"}) db.adminCommand({ flushRouterConfig: "<db>" } )
db.adminCommand( { flushRouterConfig: 1 })
4.DDS分裂和均衡的基本原理
4.1 DDS分裂基本原理

• 分裂命令
sh.splitFind("records.people"{"zipcode":"63109"})
#匹配 zipcode:63109的chunk,分裂为2个或多个chunk sh.splitAt( “records.people”,{ “zipcode”: “63109”))#以zipcode:63109为分裂点,分裂为2个 chunk
• 分裂基本过程
sharding.autoSplit自动分裂默认开启
插入、更新、删除数据时,mongos判断chunk是否超过阈值,触发chunk分裂
chunk分裂是逻辑动作,基于元数据进行标记数据边界左开右闭[)
chunk内数据shard key是相同的一个值,则无法分裂形成Jumbo chunk
4.2 DDS均衡基本原理

• 迁移命令
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
• 迁移命令
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
_waitForDelete<boolean>})
• 迁移基本过程
• 由config server 通知发送方shard,并指定迁移chunk任务(一时迁移一个chunk)
• 发送方shard 通知接收方shard主动分批次拷贝数据、增量应用到接收方
• 发送方判断chunk数据迁移完毕后进入临界区,写入操作挂起直到退出临界区
• 接收方最后拷贝chunk 最后一次增量数据完成commit,完成后接受方退出临界区
• 接收方最后进行异步删除本地chunk(孤儿chunk)
• 均衡窗口
use config
db.settings.update({id:"balancer}.{$set:
{activeWindow:{start:“02:00stop:"06:00"}}}
{upsert: true })
边栏推荐
猜你喜欢
Introduction to sakt method
手把手教会:XML建模
通过 iValueConverter 给datagrid 的背景颜色 动态赋值
Simple use of websocket
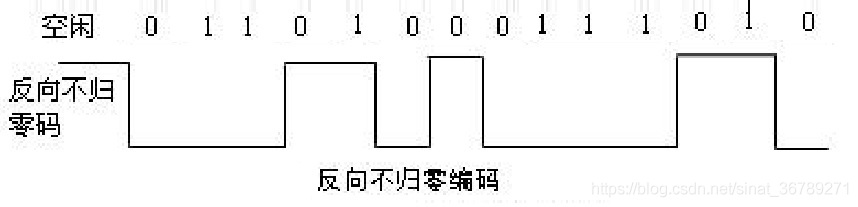
常用數字信號編碼之反向不歸零碼碼、曼徹斯特編碼、差分曼徹斯特編碼

【服务器数据恢复】某品牌StorageWorks服务器raid数据恢复案例
gvim【三】【_vimrc配置】
Mmkv use and principle
Selenium Library
Substance painter notes: settings for multi display and multi-resolution displays
随机推荐
最长上升子序列模型 AcWing 1014. 登山
股票开户首选,炒股交易开户佣金最低网上开户安全吗
The longest ascending subsequence model acwing 482 Chorus formation
小米的芯片自研之路
一个简单LEGv8处理器的Verilog实现【四】【单周期实现基础知识及模块设计讲解】
Vscode configuration uses pylint syntax checker
CVPR2022 | 医学图像分析中基于频率注入的后门攻击
常用数字信号编码之反向不归零码码、曼彻斯特编码、差分曼彻斯特编码
LeetCode每日一题(636. Exclusive Time of Functions)
【网络安全】sql注入语法汇总
Common response status codes
JS get the current time, month, day, year, and the uniapp location applet opens the map to select the location
Mmkv use and principle
Démontage de la fonction du système multi - Merchant Mall 01 - architecture du produit
Hangdian oj2092 integer solution
Data connection mode in low code platform (Part 2)
wpf dataGrid 实现单行某个数据变化 ui 界面随之响应
bashrc与profile
Cvpr2022 | backdoor attack based on frequency injection in medical image analysis
OAuth 2.0 + JWT 保护API安全