当前位置:网站首页>Introduction to sakt method
Introduction to sakt method
2022-07-07 14:10:00 【Try more, record more, accumulate more】
Network architecture and embedded interpretation :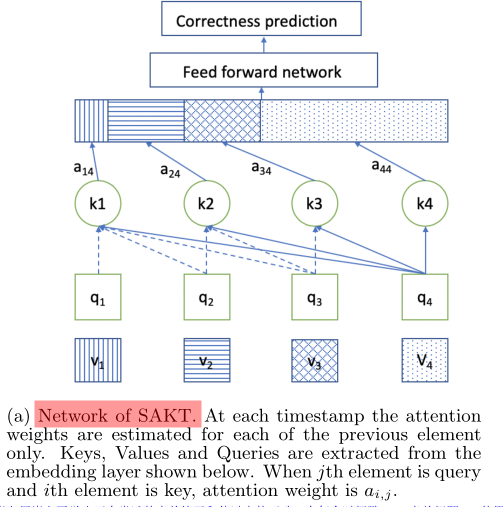
SAKT The Internet : At each timestamp , The attention weight is estimated only for each of the preceding elements . key 、 Values and queries are extracted from the embedding layer shown below . When the first j The first element is the query element and the i When elements are key elements , Note that the weight is a i j a_{ij} aij.
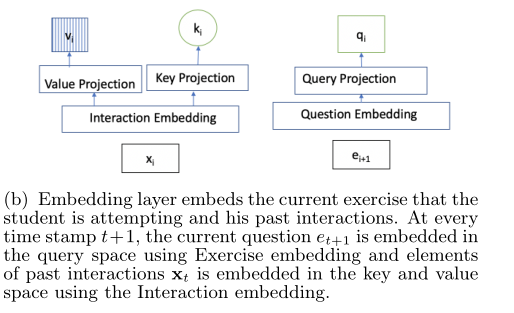
Embedded layer : Embed the current exercise the student is trying and his past interactions . At each mark t + 1 t+1 t+1 when , Use exercises to embed the current problem e t + 1 e_{t+1} et+1 Embedded in the query space , Use interaction to embed elements that will interact in the past x t x_t xt Embedded in key and value spaces .
The method is introduced in detail :
Model purpose : According to the students 1 To t moment Answer the exercises of ,( Interaction sequence X = x 1 , x 2 , . . . , x t X = x_1, x_2, ..., x_t X=x1,x2,...,xt,) Forecast on t + 1 t+1 t+1 moment , exercises e t + 1 e_{t+1} et+1 Response of ( That is, predict the real situation , The right probability ).
Interactive tuples : x t = ( e t , r t ) x_t = ( e_t, r_t) xt=(et,rt) : t t t Time exercises e t e_t et Answer of r t r_t rt Composed of . x t x_t xt When numbering , Use both to express ,: y t = e t + r t × E y_t = e_t + r_t × E yt=et+rt×E , E E E Is the number of topics , You can see the interaction number , Wrong answer The time is the same as the title number y t = e t y_t = e_t yt=et, When the answer is correct , Number plus the total number of topics y t = e t + E y_t = e_t + E yt=et+E.
Embedded layer description :
The interaction sequence needs to be divided , Ensure that the length of all interaction sequences is consistent , Many are truncated , Short fill .
Therefore, the interaction sequence is composed of y = ( y 1 , y 2 , . . . , y t ) y = (y_1, y_2, ...,y_t) y=(y1,y2,...,yt) Turn into s = ( s 1 , s 2 , . . . , s n ) s = (s_1,s_2,...,s_n) s=(s1,s2,...,sn).
Train an interactive embedding matrix : M ∈ R 2 E × d M ∈ R^{2E×d} M∈R2E×d, among d It's a potential dimension , Used to get interactive embedding . s i s_i si The embedding of is expressed as M s i M_{s_i} Msi
Practice embedding a matrix : E ∈ R E × d E ∈ R^{E×d} E∈RE×d, Users get exercises embedded . e i e_i ei The embedding of is expressed as E e i E_{e_i} Eei
Location code :
In order to encode the sequence sequence , Introduce parameters P ∈ R n × d P ∈ R^{n×d} P∈Rn×d, Add to interactive embedding , Form a new code . P i P_i Pi Add to section i i i An interactive embedding vector , Form an interactive embedding vector with position coding .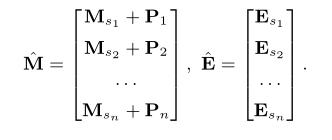
From the attention level 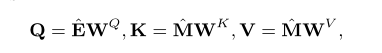
Q: Exercises embedded
K: Answer interactively embedded
V : Answer interactively embedded 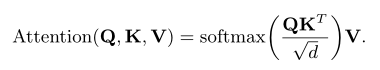
Using the attention mechanism of scaling dot product
The current exercise interacts with each previous answer Have a relationship , Calculate the attention weight .
long position
Capture information from different subspaces .
Causal relationship
Because of the sequence , Unable to know the information of the predicted topic , So use the causality layer to mask the weights learned from future interactions .
Feedforward layer
In order to add nonlinearity to the model and consider the interaction between different potential dimensions , We use a feedforward network .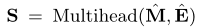
Residual connection
Use low-level information
Prediction layer
The probability of getting the prediction 
Network training
Cross entropy
边栏推荐
- Did login metamask
- Deep understanding of array related problems in C language
- Cesium 已知一点经纬度和距离求另一个点的经纬度
- Laravel5 call to undefined function openssl cipher iv length() 报错 PHP7开启OpenSSL扩展失败
- Beginner XML
- 高等数学---第八章多元函数微分学1
- Excuse me, I have three partitions in Kafka, and the flinksql task has written the join operation. How can I give the join operation alone
- Laravel form builder uses
- [AI practice] Application xgboost Xgbregressor builds air quality prediction model (II)
- Co create a collaborative ecosystem of software and hardware: the "Joint submission" of graphcore IPU and Baidu PaddlePaddle appeared in mlperf
猜你喜欢
566. 重塑矩阵

2022-7-7 Leetcode 34. Find the first and last positions of elements in a sorted array

The delivery efficiency is increased by 52 times, and the operation efficiency is increased by 10 times. See the compilation of practical cases of financial cloud native technology (with download)
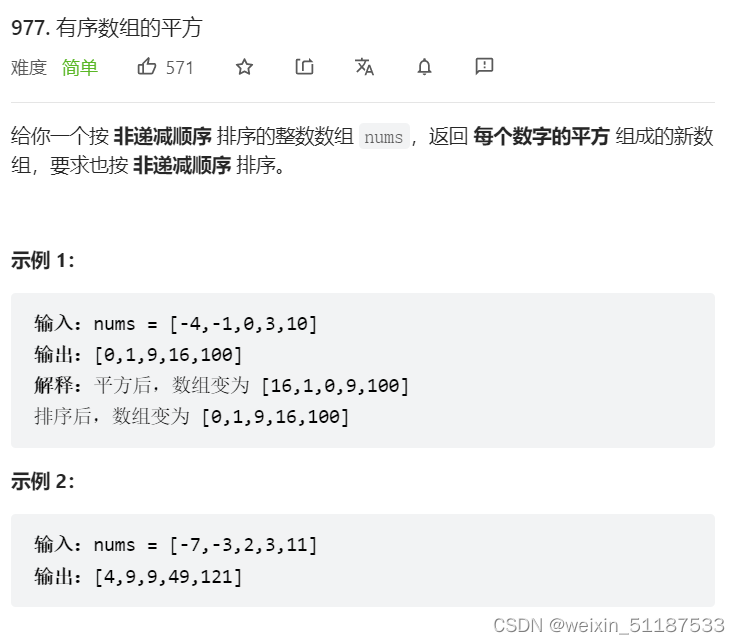
2022-7-6 Leetcode 977.有序数组的平方
得物客服热线的演进之路
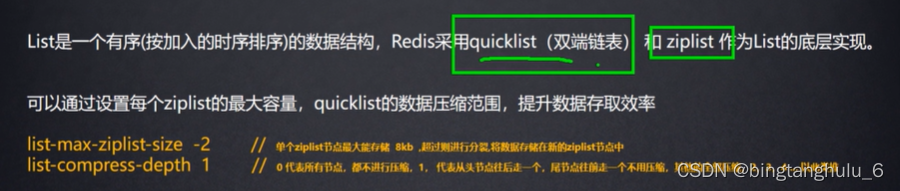
Details of redis core data structure & new features of redis 6

最长上升子序列模型 AcWing 482. 合唱队形

VSCode 配置使用 PyLint 语法检查器

Excerpt from "misogyny: female disgust in Japan"
2022-7-7 Leetcode 34.在排序数组中查找元素的第一个和最后一个位置
随机推荐
Oracle advanced (V) schema solution
最长上升子序列模型 AcWing 482. 合唱队形
Is the compass stock software reliable? Is it safe to trade stocks?
3D detection: fast visualization of 3D box and point cloud
Selenium库
Excerpt from "misogyny: female disgust in Japan"
Transferring files between VMware and host
2022-7-7 Leetcode 34. Find the first and last positions of elements in a sorted array
XML文件的解析操作
FC连接数据库,一定要使用自定义域名才能在外面访问吗?
请问,在使用flink sql sink数据到kafka的时候出现执行成功,但是kafka里面没有数
Supply chain supply and demand estimation - [time series]
Build a secure and trusted computing platform based on Kunpeng's native security
2022-7-6 Leetcode 977.有序数组的平方
IP address home location query full version
Es log error appreciation -limit of total fields
ES日志报错赏析-Limit of total fields
[daily training -- Tencent select 50] 231 Power of 2
Realization of search box effect [daily question]
SAKT方法部分介绍